 Skip to content
Skip to content


AWS Batch allows batch processing, training models, and running analysis at scale. AWS allows you to efficiently schedule Batch jobs with little management overhead.
We’re often asked, “How can we reduce our Batch costs?” Under the hood, “Batch spend” is EC2 spend. That means that by leveraging Autoscaling Groups, Spot, effective scheduling, scaling policies and other techniques to reduce your EC2 costs, you can reduce your “Batch spend” to achieve a lower AWS bill.
That’s why we wrote this guide to AWS Batch cost optimization. It covers how to get started, common questions and challenges, EC2 vs Fargate, real life scenarios, best practices, and how to save with nOps.
Let’s start with a quick explanation of what AWS Batch is and how it works.
What is AWS Batch?
AWS Batch is a fully managed service that simplifies and automates batch computing workloads across EC2, Fargate, and other AWS cloud services. Its two functions are:
- Job scheduler. Users can submit jobs to AWS Batch by specifying basic parameters such as GPU, CPU, and memory requirements. Batch queues job requests and manages the full lifecycle from pending to running, ensuring completion. If a job fails, Batch will automatically retry it — useful in the case of unexpected hardware failures or Spot instance terminations.
- Resource orchestrator engine. Batch scales up resources when there are jobs in the queue and scales down once the queue is empty — so you only pay for the compute and storage you use.
How does it work?
Let’s break down exactly how AWS Batch works.
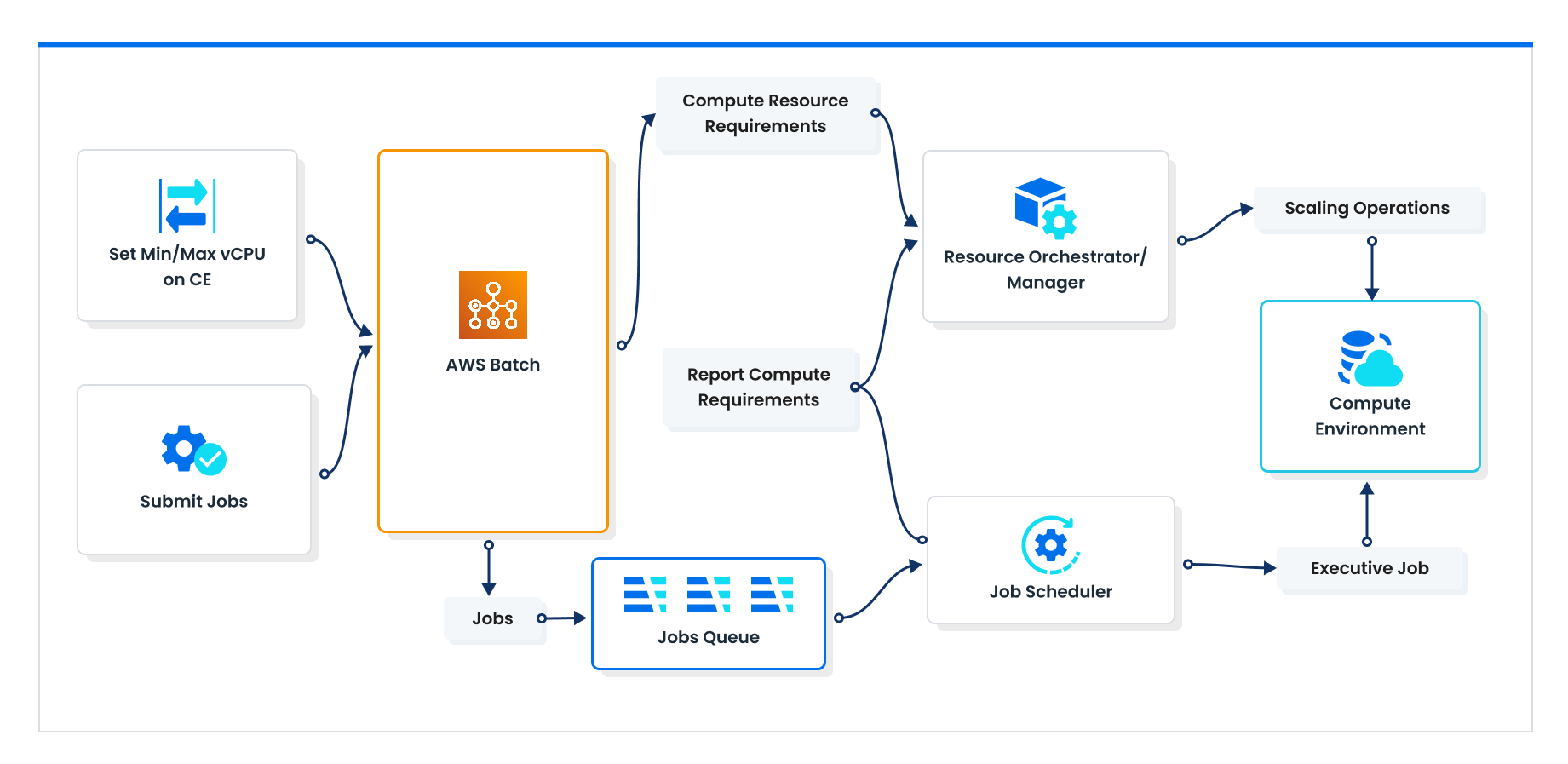
- Initially, you set constraints on the capacity Batch is allowed to use, including defining job requirements like vCPU, memory, and instance type.
- Jobs submitted to Batch are placed in a job queue.
- The job scheduler periodically reviews the job queue, assessing the number of jobs and their requirements to determine necessary resources.
- Based on this evaluation, the resource manager orchestrates the scaling of resources up or down as needed.
- The resource manager reports back to the job scheduler, informing it of the available capacity. The schedule then begins assigning workloads to the compute environment, continuously running this process in a loop.
Common challenges and FAQ for new users
If you are new to AWS Batch and just submitted your first job, you might be asking one of these common questions.
“Why aren’t these jobs going anywhere even though I’ve submitted them successfully?”
The Job Scheduler ensures scaling only to the capacity it can manage in that time frame, and no more than that. That means that it takes a certain amount of time to scale up.
“What happens if I submit a new Job while there’s a scaling event already happening?”
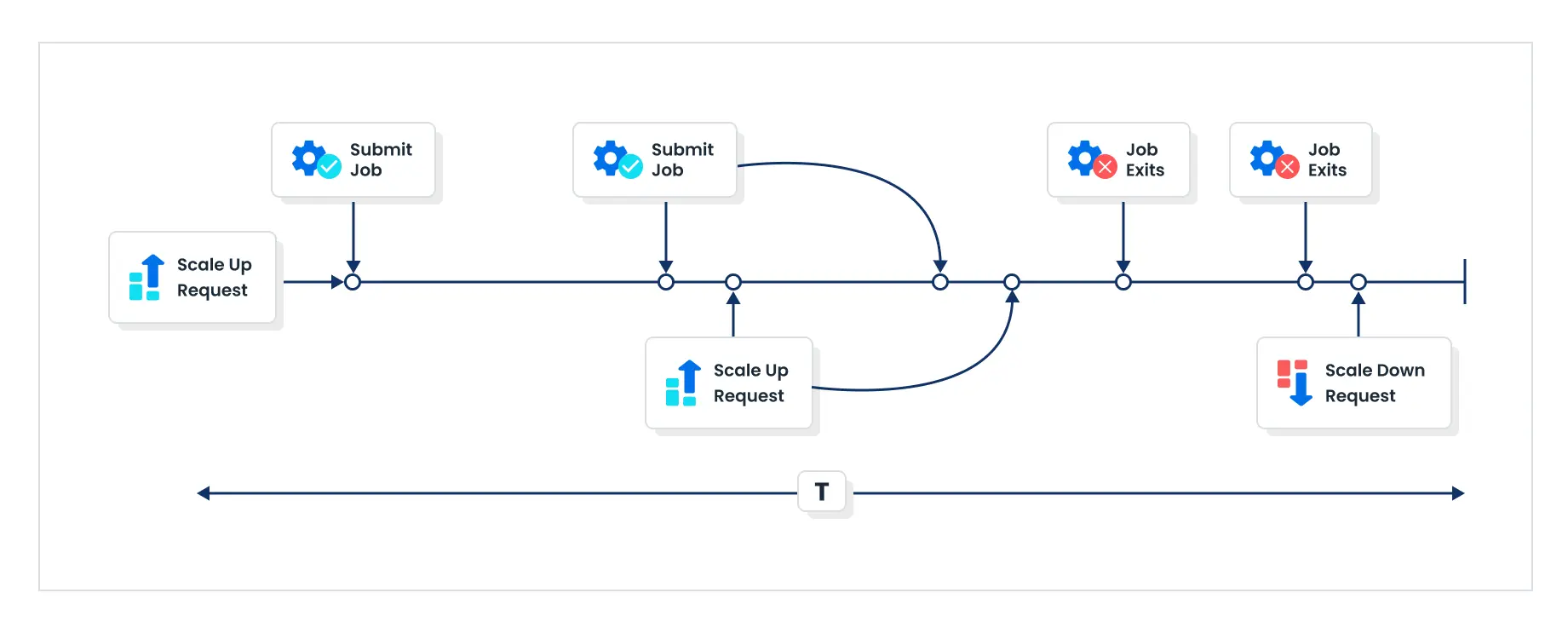
When a job is submitted in Batch and triggers a scale-up request, the system responds by increasing capacity. If another job is submitted during the same time period, AWS Batch can handle an additional scale-up request even within the ongoing interval.
“Should I use Batch with EC2 or Fargate?”
Batch is compatible with EC2 instances, AWS Fargate, and very recently EKS
Fargate is serverless. The advantage is that you don’t have to worry about compute capacities at all. Jobs are submitted to AWS as tasks, with each task receiving a right sized host. Scaling up or down is not a concern, as each job is automatically assigned to its own task.
On the other hand, with EC2, you can launch as many or as few virtual servers as you need, configure security and networking, and manage storage.
For handling a large volume of jobs, EC2 infrastructure is advisable, especially if you surpass Fargate’s throttling limits. Although Fargate scales up faster, EC2 offers faster job processing once instances are launched and available — allowing for a higher dispatch rate of jobs to EC2 resources compared to Fargate resources.
Quick guidelines for determining when to use EC2:
- More than 16 vCPUs
- More than 120 gibibytes (GiB) of memory
- A GPU
- A custom Amazon Machine Image (AMI)
- Any of the linuxParameters parameters
Best practices for cost optimizing AWS Batch
Here is a quick checklist of best practices and tips to keep in mind.
- Define job queues, priorities, and dependencies carefully in order to address job scheduling complexity. AWS Batch offers various features for managing job dependencies.
- Design for Spot Instance Interruptions: Implement job checkpointing to resume interrupted work. Design for fault tolerance with features like job retries and checkpointing. Distribute workloads across multiple availability zones for increased resilience.
- Optimize scaling policies for dynamic resource adjustments. Review and adjust auto-scaling policies regularly based on workload patterns. Use predictive scaling and historical data for resource allocation optimization.
- Manage data transfer between storage and compute resources. Don’t forget to manage data movement costs, optimize access patterns, use data compression, parallel processing, and local storage on compute instances.
- Monitoring and Logging: Establish comprehensive monitoring and logging for job progress and errors with Amazon CloudWatch and CloudWatch Logs. Implement custom logging within batch jobs for specific details.
- Balance usage of Spot and commitments: Use Spot Instances strategically for cost savings, implement job scheduling policies to minimize idle resources, leverage Reserved Instances for baseline workloads.
The Ultimate Guide to AWS Commitments


The biggest challenges of cost optimizing AWS Batch
If you’re looking to save on EC2, Spot is key to reducing cost. Yet, most companies shy away from using Spot because it requires dedicated and costly engineering resources to do effectively.
Here are a few challenges that we hear all the time:
- “What if the Spot Instances used by AWS Batch are interrupted on short notice? This can impact the completion of my Batch jobs.”
- “My Batch Jobs run daily but they change every day. How can I implement Spot, when I have no idea how to keep track of all of these Job changes?”
- “Which of the hundreds of EC2 instances available do I use? How much do I use of each? How do I decide what to commit to? How do I keep track of it all as my usage changes?”
If these challenges sound familiar, nOps Compute Copilot can help. Just simply integrate it with ASG, EKS, or other compute-based workload and let nOps handle the rest.
nOps offers proprietary AI-driven management of instances for the best price in real time. It continually analyzes market pricing and your existing commitments to ensure you are always on the best blend of Spot, Reserved, and On-Demand.
Here are the key benefits of delegating the hassle of cost optimization to nOps.
Hands free. Copilot automatically selects the optimal instance types for your Batch or other workloads, freeing up your time and attention to focus on building and innovating.
Cost savings. Copilot ensures you are always on the most cost-effective and stable Spot options.
Enterprise-grade SLAs for the highest standards of reliability. Run production and mission-critical workloads on Spot with complete confidence.
Effortless onboarding. Just plug in your Batch, ASG, EKS, or other compute-based workload to start saving effortlessly.
No upfront cost. You pay only a percentage of your realized savings, making adoption risk-free.
Real-life example:
Let’s take a look at how one of our customers (Company X) is using AWS Batch to efficiently handle the processing of AI algorithms, playlist generation and high-quality music output. Backend services are hosted on EC2.
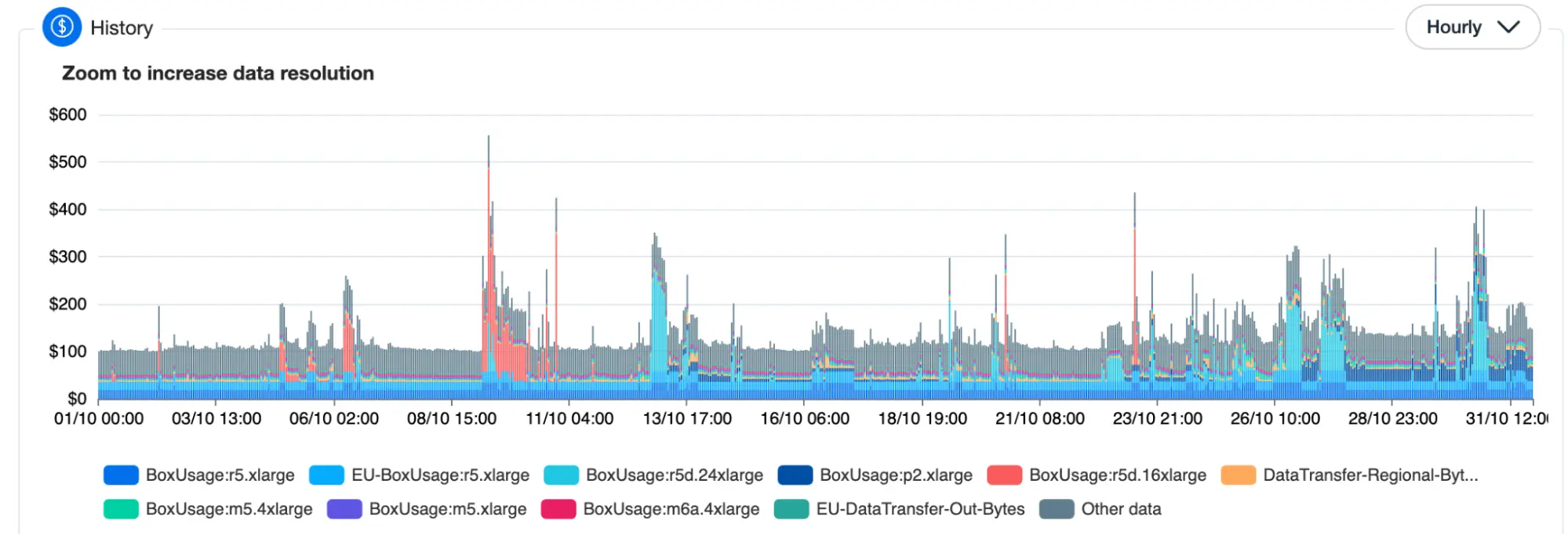
Hourly Batch usage pattern
The problem is that processing AI algorithms is resource-intensive, requiring significant computational power. Therefore, Company X configured AWS Batch to dynamically scale resources based on the volume of incoming AI processing tasks and improve resource utilization.
Yet, Company X faced challenges optimizing costs associated with AWS Batch, especially during periods of low demand. Due to dynamic usage patterns, Savings Plans and Reserved Instances were often going unused.
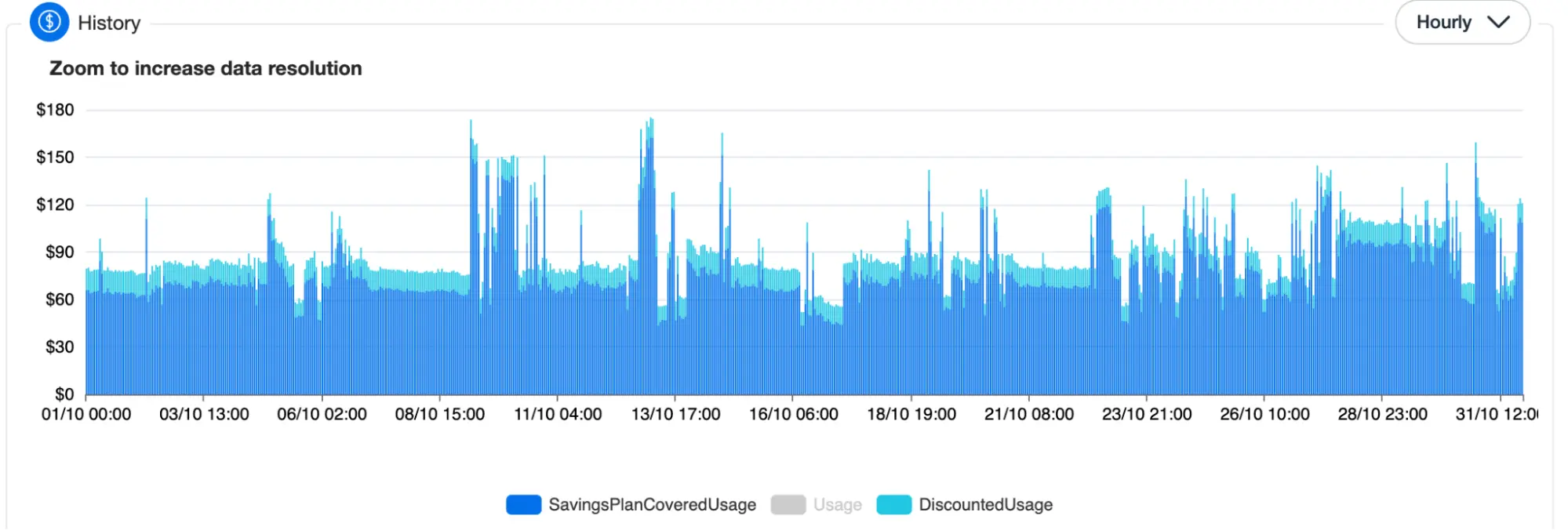
Hourly usage of SPs and RIs
Company X wanted to use Spot to cover spikes in usage and reduce commitments, but Spot interruptions threatened the AI processing workflows.
Solution: nOps Compute Copilot for automatic cost optimization & Spot reliability
Compute Copilot identified the baseline workload for AI processing and managed these workloads on long-term commitments automatically for Company X, with zero engineering effort required.
It automatically replaced the Batch workloads running on Savings Plans with Spot when cheaper, and pushed non-Batch on-demand EC2 workloads to Savings Plans to maximize savings from unused commitments. Spot Instances were strategically used during periods of peak demand, providing cost savings. The interruption risk was mitigated by 1-hour advance ML prediction of Spot instance interruptions.
nOps delivery team worked with Company X engineers to implement checkpointing in the AI algorithms to mitigate the impact of interruptions (should there be any), allowing for the resumption of data processing from the last completed checkpoint.
As a result, Company X benefitted from Spot savings with the same reliability as On-Demand.
Take a look at the before and after graph:
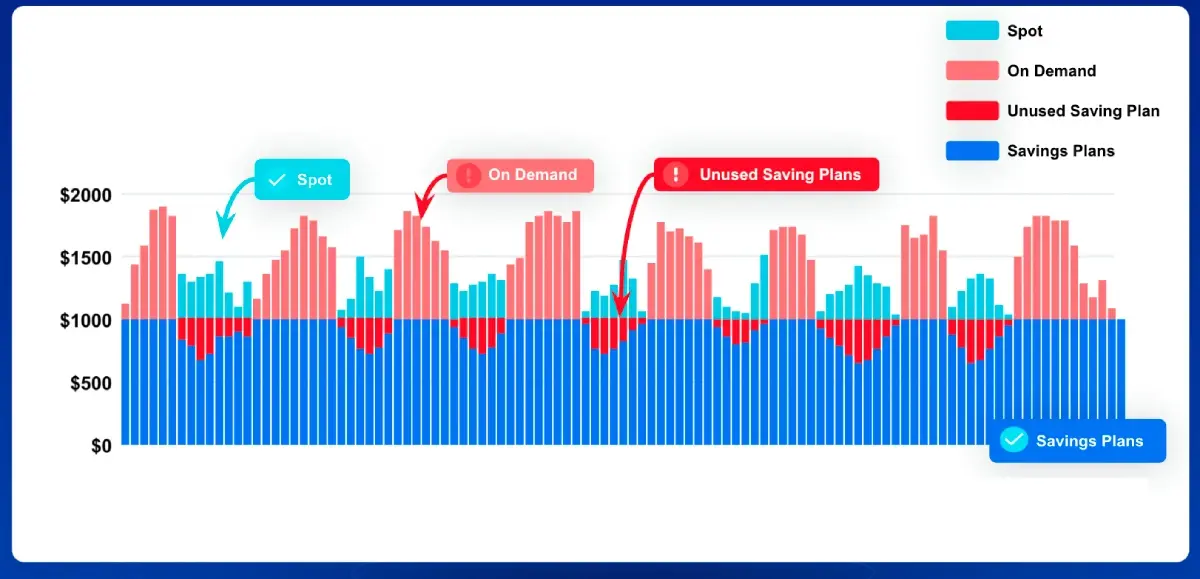
Before: Unused commitments, insufficient Spot, and high On-Demand prices drive up AWS bills.
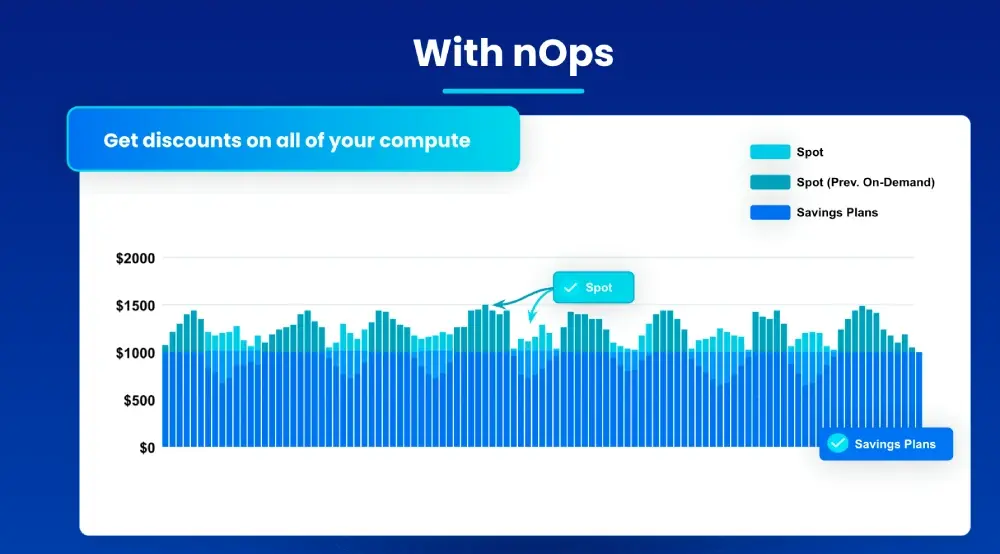
After: Copilot automatically manages your workload to ensure all of your usage is discounted, maximizing savings hands-free
nOps was recently ranked #1 in G2’s cloud cost management category. Join our customers using nOps to slash your cloud costs and leverage automation with complete confidence by booking a demo today!


