 Skip to content
Skip to content


Data engineering is a critical aspect of any modern business that relies on data-driven decision-making. It involves the collection, processing, and storage of large amounts of data in a way that makes it easy to analyze and derive insights from.
nOps, an automated FinOps platform, is an excellent solution for organizations that want to optimize their AWS costs. With its AI-powered optimization capabilities, nOps can help organizations reduce their AWS costs by up to 50% on auto-pilot.
The nOps platform uses machine learning algorithms to identify opportunities for cost savings in real-time. By analyzing an organization’s AWS usage patterns, nOps can provide automation to make changes to optimize costs without sacrificing performance. This can include recommendations and automated provisioning on areas such as optimal instance reservations, unused resources, underutilized instances, spot, and even guidance on which AWS services to use for optimal performance and cost-effectiveness.
One of the data engineering problems that nOps needed to first solve was the fast and repeatable ingestion of large Cost and Usage Report (CUR) parquet objects. This is in addition to a handful of boto3 calls for data points not in the CUR. What made these problems difficult before is that the CUR can be millions of rows, which can all be updated multiple times per day. This is in addition to schema drift (new or missing columns, changed data types) that can happen at any time and break a traditional data pipeline. By traditional I mean using csv or json file types and relational databases (RDS). Using a combination of S3, Parquet, Databricks, and Druid solves these problems. Today we can quickly give users the near-real time FinOps showback data, which is unique in the FinOps as a service industry.
I can firmly state that Databricks has been by far the best data platform I’ve ever used. In fact, is it so valuable to our operations that it has taken over every revenue-generating part of the nOps platform. After working with Databricks for many months, I had some thoughts regarding our internal and external data offerings that I wanted to share with the reader; starting with the nOps Data Diagram:
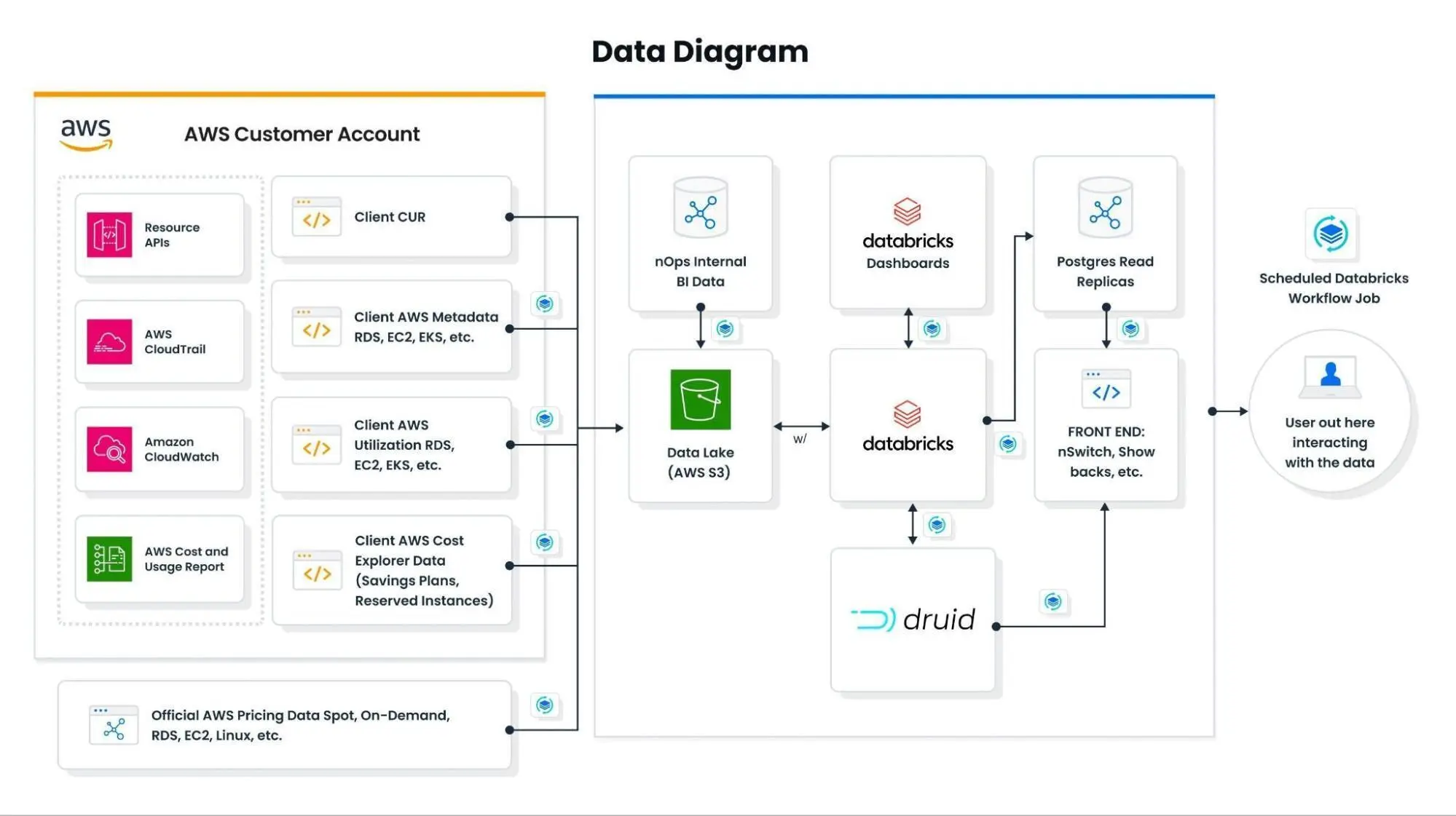
Data Lake
S3 could be thought of as an object database. For example, any table over ~100k rows should only live in S3 as a Parquet and be referenced as needed. For our purposes, there is no need to make it a static SQL table in an RDS. Thankfully the AWS Cost and Usage Report (CUR) officially supports the Parquet format. Also, with Spark, the act of producing, partitioning, optimizing, and maintaining large SQL tables is now obsolete (and will not scale anyway).
Spark and Parquet makes working with huge datasets (3 billion rows and ~250 columns in our case) incredibly easy. As our machine learning engineer says: “I do not have to think about any underlying infrastructure. I just simply run my SQL queries using Spark, which aggregates our huge dataset in seconds. Pandas, Pyspark and Notebook are also workflow options. Back in the day, working with even 200 GB of data could bring a lot of pain. With databricks, the pain is gone.”
Ingestion
In many cases there is no ingestion that Databricks has control over. Data is read as needed from S3. There is processing that happens on a schedule then those results are saved to S3. The expected raw data exists in the source bucket or it doesn’t. In practice, a time window is agreed on. (current month, last 24 hours, etc) and a Golden List list of expected `client_id` is constructed (using nOps BI logic) and then iterated over.
However, we use Databricks as a “test” layer for ingestion. Our machine learning engineers often test different data ingestions (like AWS APIs) before the ingestion is moved to batch.
Compute Layer
Databricks could be thought of as a compute layer. For example, it makes recommendations, processing the SharedSave realization, etc. Currently, as a shortcut, we’ve been stashing the results as tables in the Databricks SQL warehouse, but moving forward I would like to suggest we copy these result tables to a Postgres DB. For API development this future state is not a blocker since the columns will be one-to-one.
Our machine learning engineers absolutely love notebooks. The reasons are obvious for those who work with notebooks. Plus, all the code is accessible from a web browser. This in-browser workflow has saved me multiple times when my work laptop was unreliable.
On top of that, it makes it incredibly easy to prepare notebooks with analysis that needs to be run on demand/on request, and not on a schedule. Simply share the URL notebook with the person that needs analysis and all they have to do is just press “Run All”. Good things for international teams when there is a significant time zone difference.
All of our ML and statistical models are built inside notebooks and run on scheduled Databricks Workflows. Those jobs export results to Postgres RDS – which we call the “Small Presentation Layer”.
Small Presentation Layers
Postgres RDS is treated as the small presentation layer; the final stop for all computed data. This is mostly used for finished products whereas newer R&D phase products use the built-in Databricks SQL Warehouse. By this point in the pipeline, we should have no more calculations, no models, and ideally very few JOINs. This layer exists to serve data to an API and keep our Premium SQL compute costs low. The entire contents of the Postgres RDS can be destroyed and remade from calculations done in the previous step.
Large Presentation Layer
Another presentation layer we have started using is Apache Druid which is optimized for business analytics. In our case, Druid contains millions of rows of historical Cost and Usage Report (CUR) data for all of our clients. This naturally lends itself to a timeseries style database; of which there are many but Duid is perhaps the most powerful. This approach to event data solves the common problem of chargebacks in FinOps, which is the ability to attribute every single dollar in the CUR to a specific team or process. Druid allows users to quickly slice and dice millions of rows of data; not only on a time dimension but also filter using custom tags. This functionality is not offered in any other free-to-use finops platform.
Data Velocity
I am proposing that these layers remain stateless (as in: independent of each other) for the benefit of clarity and accessibility of the data to anyone on the team. Every part of this flow can be inspected and re-ran by a human using a Notebook.
All of the aspects above are central to the nOps data platform and they are only made possible with Databricks. We at nOps are huge fans. The next steps are that we hope to go even deeper into Databricks Machine Learning workflows.
Impact Summary
Databricks has allowed us to achieve tremendous innovation. Using Notebooks allows anyone to quickly look at our data in a reproducible and accessible way. The Databricks SQL Warehouse allows us to quickly make an end-to-end feature to test on the front end. Not only do things move faster internally, so does the new value to the customers. We at nOps are excited to keep innovating with Databricks.
From a data science perspective Databricks allows us to iterate faster through our typical pipeline. With an already preconfigured PySpark in our cluster, handling big data cases is no longer a problem. Additional attention deserves Databricks Notebooks, having them we can do everything as we would do in .py file but easier, faster and with more debug power. Intuitive UI makes it super easy to configure the Notebook as a job with desired run schedule and computational power you need.
All these advantages could be summed up with one sentence: “Databricks enables handling of Data Engineering, Data Science, Data Analytics, DevOps and BE in one ecosystem”. From one angle this is similar to Github/Gitlab but for data purposes.
