Cut AWS EC2 ASG Costs with nOps Rightsizing Recommendations
EC2 instances not being correctly sized can quickly lead to unnecessary expenses. Rightsizing is critical to optimize costs and stability.
However, rightsizing a single EC2 instance is one thing — everything gets much more complicated if you want to rightsize within Auto Scaling Groups. Most sources of rightsizing recommendations overlook this area — yet it is a huge portion of your compute cost.
Why is ASG rightsizing so hard to do right?
Rightsizing instances in an ASG is infinitely more complicated than rightsizing an EC2 instance. EC2 instances that are part of an ASG should be rightsized together — NOT individually as you would normally do when rightsizing.
The dynamic nature of ASGs is such that instances come and go over time and may have different metrics distributions. Some terminated instances may have a higher or lower percentage utilization. These factors all add a huge amount of complexity to the calculations, particularly when it comes to Mixed-Instance ASGs.
To make reliable rightsizing recommendations, we need to account for (1) ALL of the instances that belonged to each ASG, both short-lived and long-lived, (2) track all of the instances’ metrics over time, and (3) group that data together to analyze their min and max resource consumption at an aggregate level.
And if you make just one mistake and act on an unreliable recommendation, this may result in problems when the instances reappear — affecting the performance and stability of your workload.
nOps Makes ASG Rightsizing Simple and Seamless
Tracking all of your instances, finding the right data, performing the right calculations, and accounting for all of the possible variables in a mixed-instance ASG is almost impossible to do manually.
That’s why nOps has integrated with the two industry-leading monitoring solutions, AWS CloudWatch and Datadog, for effortless rightsizing savings. We automatically analyze every EC2 instance in your environment (including shortlived ones) and pull their metadata to group them into their respective ASGs, analyzing min and max resource consumptions at an aggregate level to provide cost-saving recommendations.
Continuous coverage of resource-level insights such as memory, CPU, network bandwidth and storage are fed through nOps’s state-of-the-art ML engine for the best rightsizing recommendations available on the market.
Rightsize with nOps for:
The most trustworthy rightsizing recommendations. Because nOps automatically collects and analyzes highly granular data, recommendations are 100% accurate and reliable — so engineers can act on them with the utmost confidence that workloads won’t be disturbed.
Up to 50% in immediate cost savings. When engineers don’t act on rightsizing recommendations, underutilized and idle resources continue to drive unnecessary AWS costs. nOps make it completely pain-free, safe and effortless for engineers to actually act on recommendations and start saving.
How it works
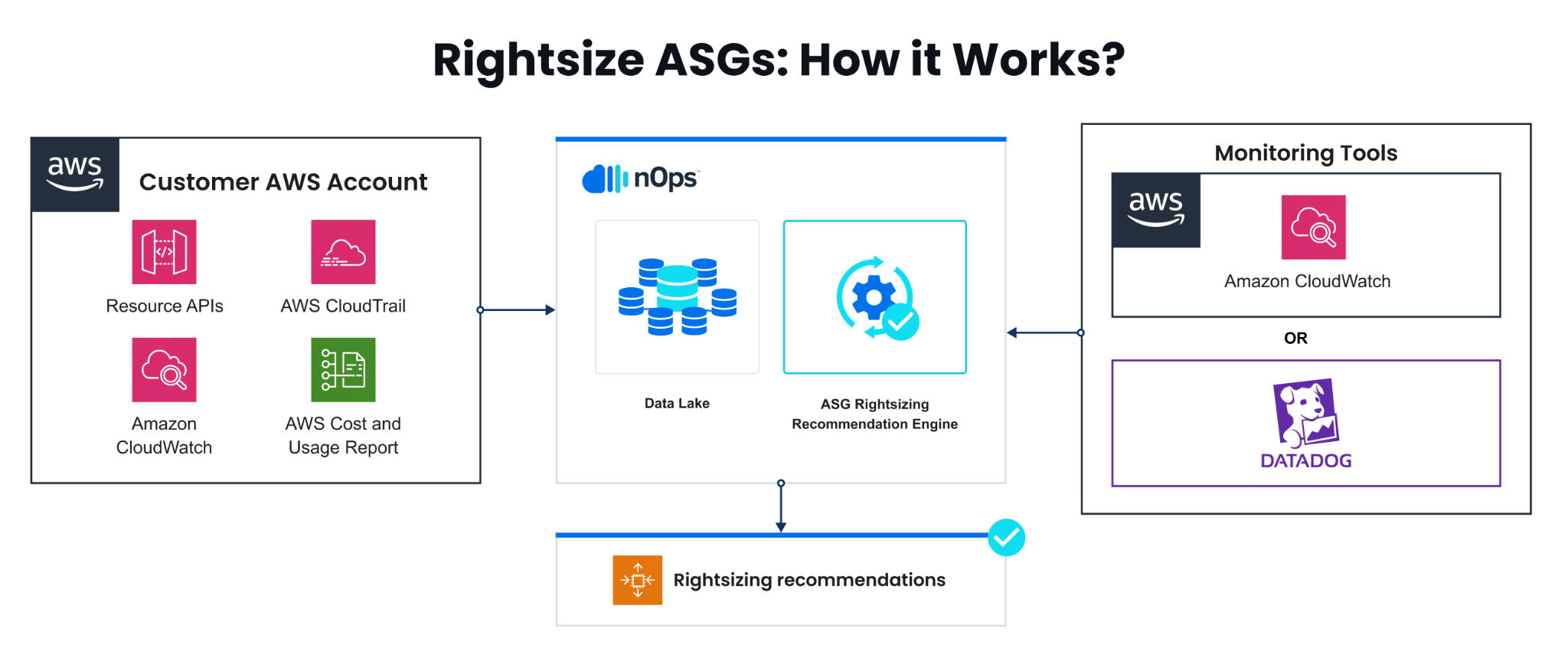
- nOps integrates with your CloudWatch, CloudWatch Agent or Datadog to collect all of the metrics needed for ASG rightsizing recommendations, based on your last 10+ days of usage. Our API queries your data every 24 hours.
- We quickly and efficiently process huge amounts of your CloudWatch data, crossed-referenced with AWS EC2 metadata and the latest AWS On-Demand pricing data to keep track of all of your ASGs (including terminated instances). These three sources are combined and fed through a Rightsizing Engine, allowing us to understand your dynamic ASGs holistically.
- For each ASG, each of your instances is analyzed taking all relevant info into account, such as the metrics necessary for your particular operating system. For each instance in your environment, we make the following calculations:
- Max Disk usage
- Max Network usage
- Max RAM utilization
- Max CPU utilization
For each instance, our rightsizing algorithm compares maximum recorded usage against the capacity of a lower instance type, multiplied by a threshold value that accounts for potential future usage spikes. nOps takes into account the aggregate performance and utilization metrics of all instances within an ASG to make informed recommendations.
- If all of the instances are rightsizable, the whole ASG is rightsizable. If you have several instance types, they can be analyzed and rightsized separately.
- These rightsizing recommendations are then pushed to nOps microservices, which are responsible for showing recommendations from the nOps platform on the UI.
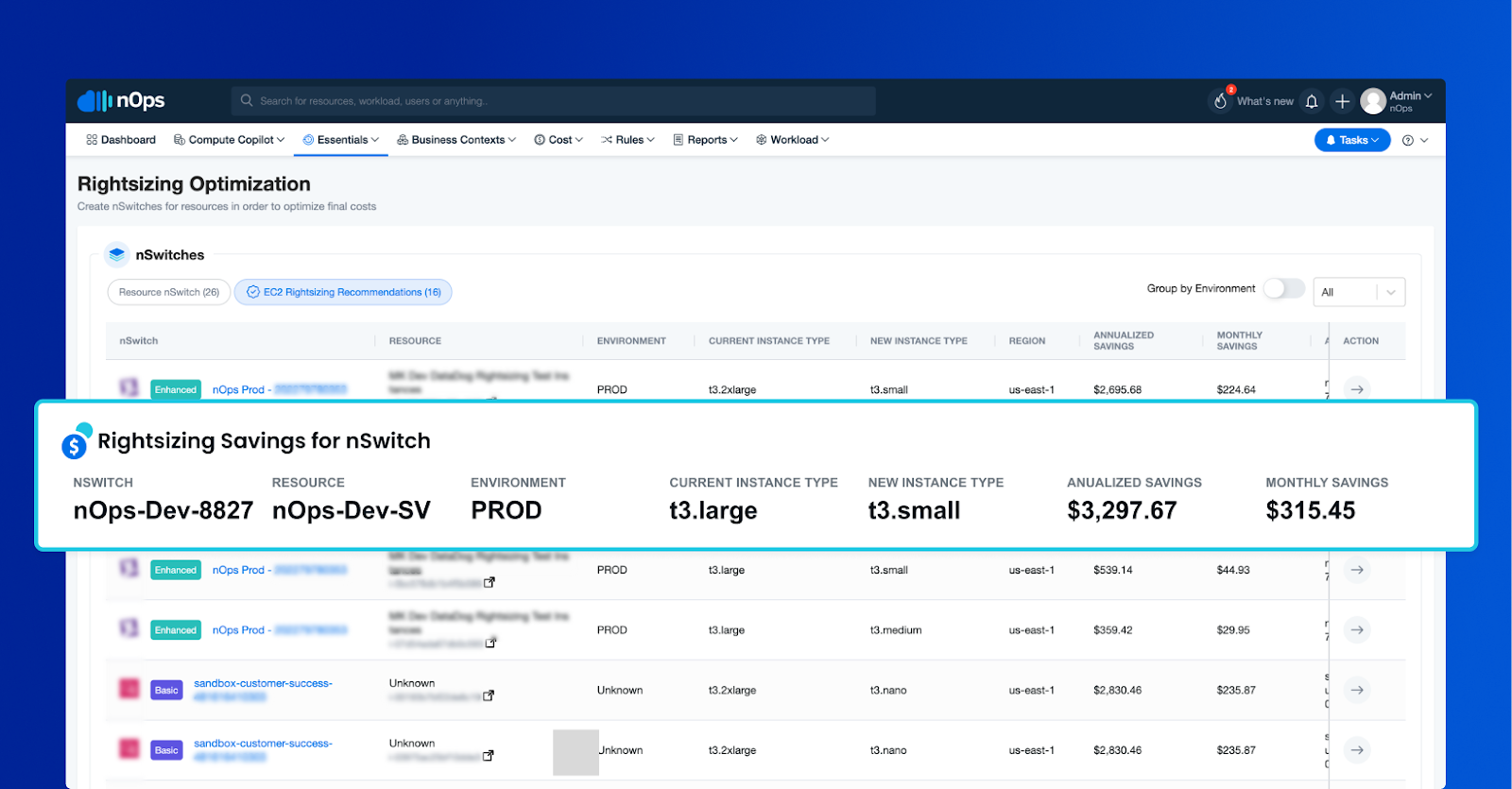
6. Every 24 hours the process runs from top to bottom.