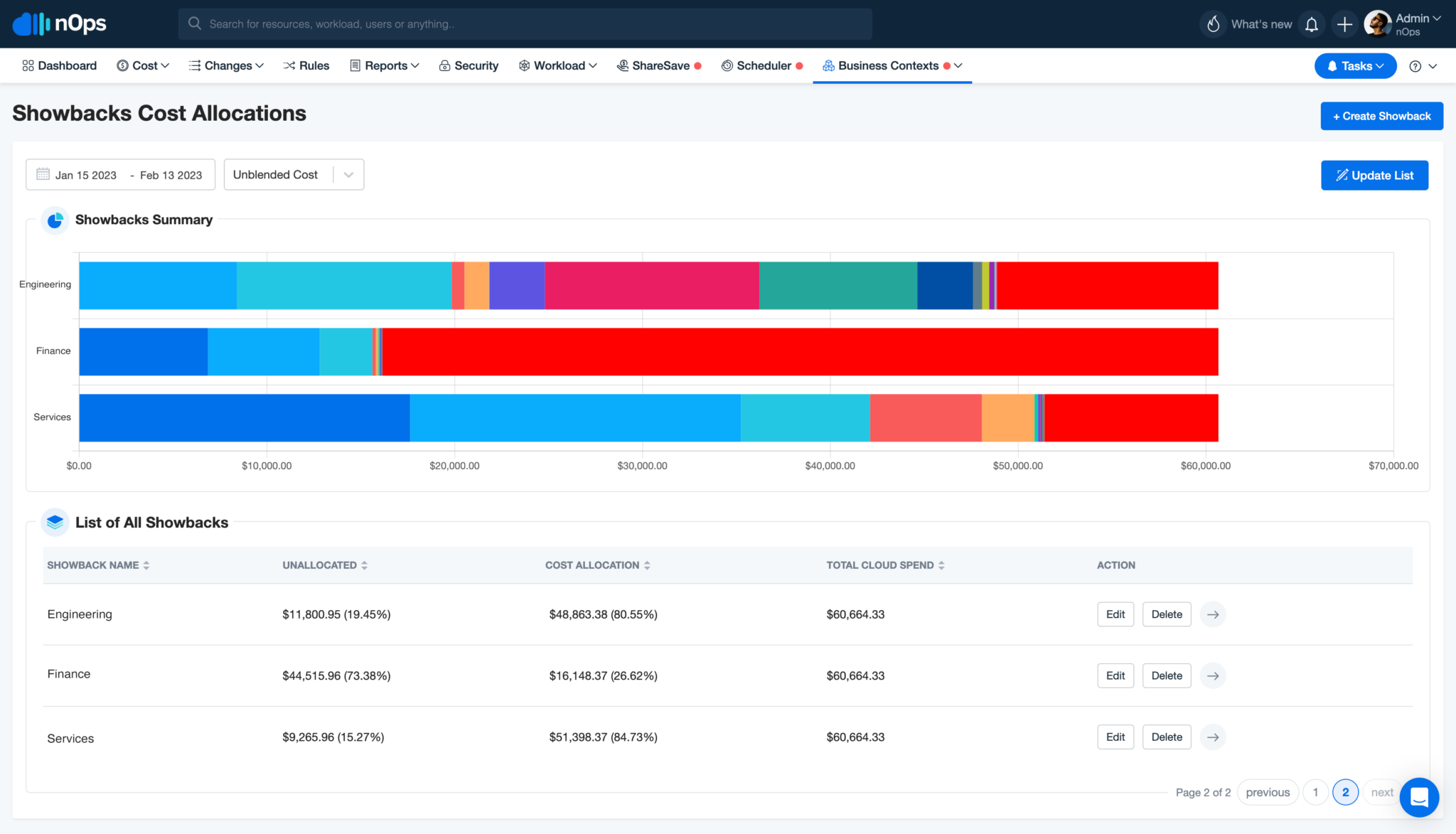
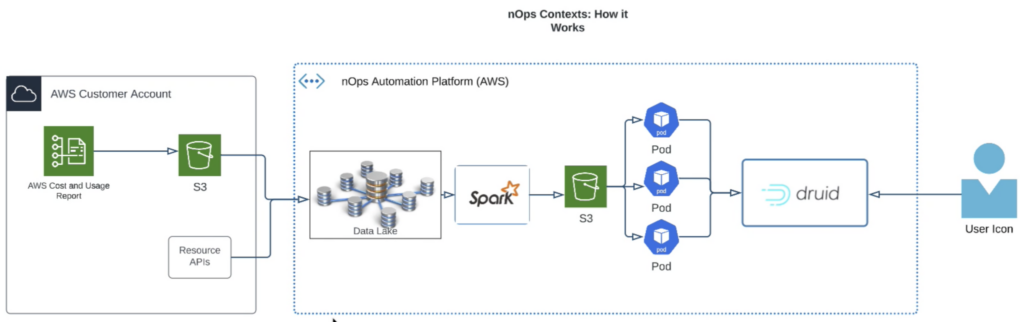
By using Apache Druid, we provide you with the capability to quickly interact with your data and build custom filters and allocation rules without having to run a background report or experience any slowdowns. Druid provides subsecond queries without having to pre-cash.



 Skip to content
Skip to content