

What is Athena in AWS?
In this essential guide, we'll cover AWS Athena key features, use cases and benefits, step-by-step instructions for getting started, frequently asked questions, and more.
What is Amazon Athena?
AWS Athena is an interactive query service that makes it easy to analyze data directly in Amazon Simple Storage Service (AWS S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run.
Athena simplifies the process of querying large-scale datasets and integrates with various data formats, enabling quick analysis without the need to set up complex ETL processes. This service is ideal for quick, ad-hoc querying and also for complex analysis, such as large joins and window functions.
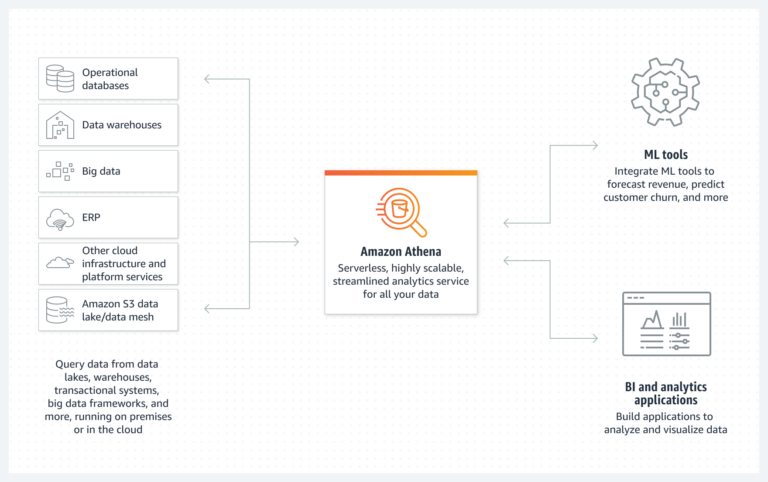
The benefits of AWS Athena, an interactive query service (image source; AWS)
Benefits of Amazon Athena
The key benefits of AWS Athena include:
Serverless Architecture:
Athena operates on a serverless model, meaning you don't need to manage the underlying compute infrastructure. This allows you to focus solely on querying and analyzing your data without worrying about maintaining servers.
Ease of Use & Quick Setup:
Amazon Athena requires no complex ETL processes, making it accessible for users with basic SQL knowledge. You can start querying your data almost immediately in Athena by simply pointing it to your data in S3, defining the schema, and executing your SQL queries, which is ideal for rapid ad-hoc querying and iterative analysis.
Built on Amazon S3 for an underlying data store:
Athena uses Amazon S3 as its underlying data store. This integration allows you to directly query data in Amazon S3 without prior data loading. S3 and Athena are durable and highly available; Athena executes queries across multiple facilities, automatically routing queries appropriately if any specific facility is unreachable.
Integrates with AWS QuickSight and Glue:
Athena seamlessly integrates with Amazon QuickSight for intuitive data visualization and AWS Glue for efficient ETL processes. This connectivity enhances data management and analysis across AWS services such as Apache Spark, enabling the running of Spark applications directly from its console without setup or management of resources. This feature simplifies data analytics with an intuitive notebook experience, supporting Python and Athena notebook APIs for efficient large-scale data processing.
Pay Per Query:
With Athena, costs are directly tied to query execution rather than underlying infrastructure. You only pay for the SQL queries you run, optimizing cost-efficiency, especially for intermittent querying needs.
Open Architecture:
Athena is built on the distributed SQL query engine Presto, and Trino. Its architecture allows you to query a diverse range of standard data formats directly in S3, including JSON, CSV, Parquet, Avro, ORC.... for querying structured, semistructured and unstructured data.
Encryption Support:
Athena supports querying encrypted data stored in Amazon S3, including both server-side encryption with AWS Key Management Service (SSE-KMS) and client-side encryption, and also allows you to encrypt query results before storing them in S3, providing robust security options for sensitive data.
Considerations & Limitations of Athena
You might avoid using AWS Athena when your workload requires complex data manipulation, indexing, or consistent high performance, as these are better handled by solutions like Amazon Redshift, which offers optimized query performance and advanced database features.
Here are some limitations of AWS Athena to keep in mind:
Limited Data Optimization: Athena's optimization is restricted to the query level. Data already stored in S3 cannot be optimized, limiting potential performance improvements.
Lack of Indexing: Unlike traditional databases, Athena does not support indexing. This absence can increase the operational load, especially when dealing with large datasets, leading to potential performance issues during query execution.
Partitioning Requirements: Efficient queries in Athena often require data partitioning. However, managing these partitions to ensure optimal performance can be complex and time-consuming. For example, scanning every 500 partitions can add a second to your query time.
No Data Manipulation Language (DML): Athena lacks built-in support for Data Manipulation Language operations such as INSERT, UPDATE, and DELETE. This limitation means Athena is purely a query service, and any data manipulation needs to be handled externally.
Resource Sharing: Athena operates on a multi-tenant model, meaning resources are shared among all users. This can lead to fluctuating performance, particularly during peak usage times.
Time-Outs on Large Tables: Queries on tables with thousands of partitions can time out, especially if partitions are not of the string type. This can require additional management to prevent such issues.
Unsupported SQL Statements: Several standard SQL features and statements, such as CREATE TABLE LIKE, UPDATE, MERGE (for non-transactional table formats), and stored procedures, are not supported in Athena. This limits its functionality compared to more traditional databases.
Hidden Files: Files in S3 that begin with a dot (.) or an underscore (_) are treated as hidden by Athena, potentially causing issues if these files contain relevant data.
Row and Column Size Limitations: The maximum size for a row or column in Athena is 32 megabytes. Exceeding this limit can result in errors, particularly when working with large datasets in formats like CSV or JSON.
When do I need Athena vs Redshift vs EMR?
The choice of whether to use Athena, EMR and Redshift largely depends on type and format of data, data sources, and how complicated your use case is. In general, Athena is better for quick ad-hoc queries on S3, whereas other solutions are better for larger and more complicated use cases.
When to use Amazon Athena: interactive query service
Use Amazon Athena when you need to run interactive ad-hoc SQL queries on data stored in Amazon S3 without having to manage any infrastructure or clusters. Athena is ideal for quickly analyzing unstructured, semi-structured, and structured data, including formats like CSV, JSON, Parquet, and ORC. With Athena, you can start querying data immediately using ANSI SQL, making it perfect for situations where you need fast, on-the-fly insights—like troubleshooting web logs. It integrates with AWS Glue for a centralized metadata store, enabling easy data management, and with Amazon QuickSight for straightforward data visualization.
When to use Amazon EMR to analyze data
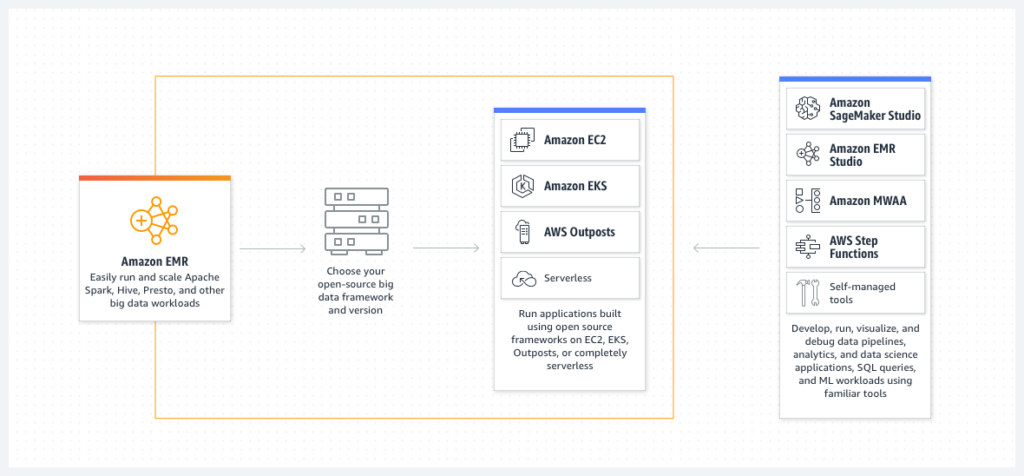
Choose Amazon EMR if you need to process and analyze large datasets using distributed data processing frameworks such as Hadoop, Spark, or Presto. EMR is highly flexible, allowing you to run custom applications and code while controlling compute, memory, storage, and software configurations. This makes it an excellent choice for complex data processing tasks, including machine learning, graph analytics, and large-scale data transformations. If you require full control over the environment and need to run scalable, customized processing jobs on big data, EMR is the right tool.
When to use Amazon Redshift to analyze data
Use Amazon Redshift when you need to aggregate data from multiple sources, like inventory, financial, and sales systems, into a unified format for long-term storage and detailed analysis. Redshift is optimized for running complex queries on highly structured data, particularly those involving multiple joins across large tables. It’s the best choice when you need to build sophisticated business reports from historical data, leveraging its powerful query engine to handle large-scale, multi-table queries efficiently. For in-depth analytics on structured data over long periods, Redshift is your go-to service.
Athena vs Microsoft SQL server
Amazon Athena is a serverless query service for running SQL queries on data stored in S3 without infrastructure management, while Microsoft SQL Server is a relational database management system that requires dedicated resources and is optimized for handling transactional and analytical workloads on structured data sources (making it more comparable to Redshift).
How to get started with Amazon Athena
To get started with Amazon Athena, create a bucket in Amazon S3 using the same AWS Region and account as Athena (e.g., US East (N. Virginia)) to hold your query results and configure it as your query output location. For the specific steps, you can consult the AWS documentation linked below.
Amazon Athena pricing, simplified
Let's break down exactly how much Amazon Athena will cost you, depending on your use case.
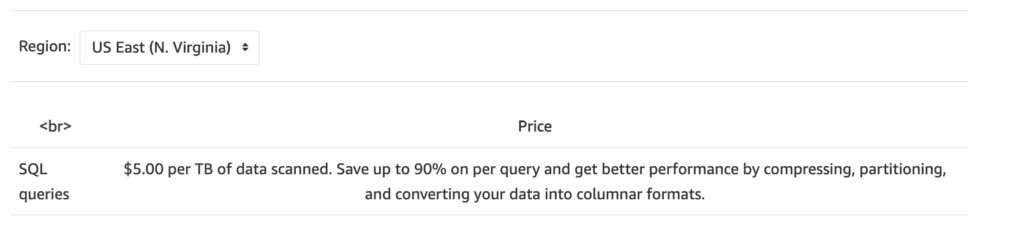
SQL Queries:
What it is: Amazon Athena allows you to run SQL queries directly on data stored in Amazon S3 without needing to set up servers.
Cost Basis: You are charged based on the amount of data scanned by each query.
Price: $5.00 per terabyte (TB) of data scanned (note: depends on AWS region)
Cost-Saving Tips: Compressing, partitioning, and converting your data to columnar formats (like Parquet) can reduce the amount of data scanned, potentially saving up to 90% on costs.
Minimum Charge: Each query has a minimum charge of 10 MB.
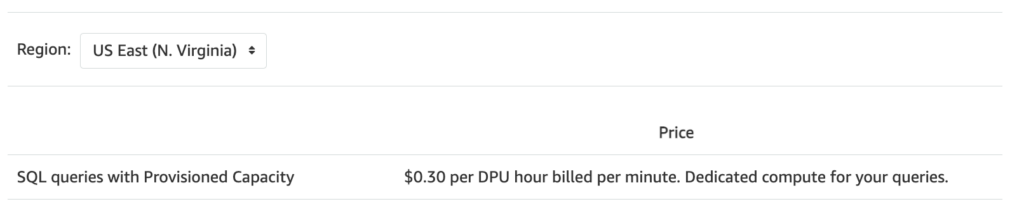
Provisioned Capacity:
What it is: Provisioned Capacity in Athena provides dedicated compute resources (DPUs) for consistent performance in running SQL queries.
Cost Basis: You pay for dedicated compute resources (Data Processing Units or DPUs) rather than per query.
Price: $0.30 per DPU hour, billed per minute.
Use Case: Ideal for predictable workloads where consistent performance is needed.
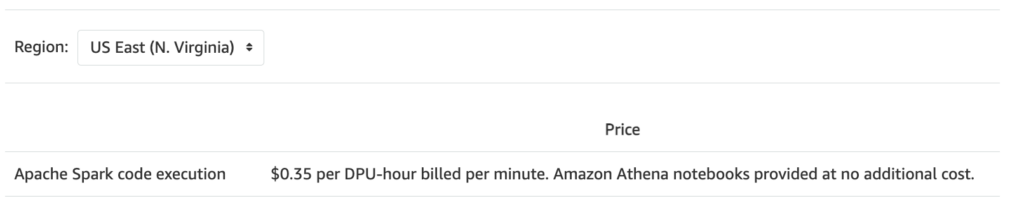
Apache Spark:
What it is: Athena for Apache Spark enables you to run distributed data processing tasks using Apache Spark on data stored in Amazon S3.
Cost Basis: You pay for the time your Spark application runs, based on the DPUs used.
Price: $0.35 per DPU hour, billed per minute.
Minimum Resources: Spark sessions start with at least two nodes (notebook and Spark driver).
Additional Costs
What it is: Additional costs related to using Athena includes charges for S3 storage and AWS Glue Data Catalog.
S3 Charges: Athena queries data stored in S3, so you'll incur standard S3 storage, request, and data transfer fees.
Glue Data Catalog: If using AWS Glue for metadata, standard Glue pricing applies.
Federated Queries: When querying data sources not stored in S3 using an Amazon Athena federated query, additional Lambda function costs may apply.
Understand and optimize Amazon Athena with nOps
If you’re looking to save on Amazon RDS, nOps Business Contexts makes it easy and painless to get the info you need to understand your spend, make informed decision on purchase commitments, and reduce Athena costs.
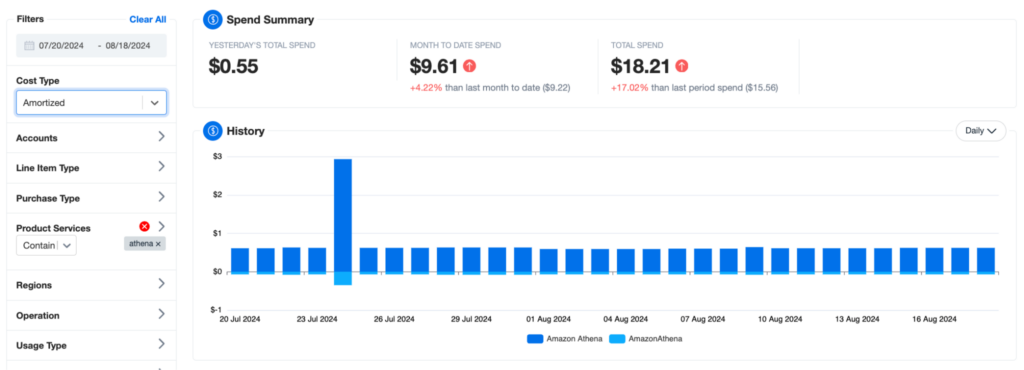
Business Contexts transforms millions of rows of contextless data into the who, what, when and why of cloud spend — making it easy to get 100% visibility of your cloud costs and usage so your bills are never a surprise or mystery.
Allocate 100% of your AWS costs, including EKS. Kubernetes costs are often a black box — no longer with nOps. Understand and allocate your unified AWS spend in one platform.
Automated resource tagging. You don’t need to have all your resources tagged to allocate costs. Create dynamic rules by region, tags, operation, accounts, and usage types to allocate costs back to custom cost centers.
40+ views & filters. Map hourly costs by any relevant engineering concept (deployment, service, namespace, label, pod, container…) or finance concept (cost unit, purchase type, line item, cost allocation tag…).
Custom reports & dashboards for the whole team. Monthly reporting and reconciliation can take hours; with nOps only minutes. Tailor dashboards and Slack/email reports to your needs, whether you’re a CFO or VP of Engineering.
The best part? nOps is an all-in-one solution for all of your cloud optimization needs: automated commitment management, rightsizing, resource scheduling, workload management, Spot usage, storage optimization, and more.
Join our customers using nOps to understand your cloud costs and leverage automation with complete confidence by booking a demo today!