Skip to content
Skip to content



Optimizing your ASGs only goes so far — for the biggest discounts, moving your usage onto discounted Spot instances can help you save significantly. AWS Spot instances can save you up to 90% in costs compared to On-Demand instances. And contrary to common belief, it is possible to use Spot instances reliably in workloads beyond stateless workloads.
However, there are challenges involved in using Spot, such as handling interruptions, knowing how much to use with your existing Reserved Instance and Savings Plan commitments, and more. Let’s discuss how you can handle some of these challenges effectively while using Cluster Autoscaler.
- Leverage Managed Node Groups to reduce operational overhead: We recommend using Managed Node Groups (rather than Unmanaged Node Groups) to manage worker nodes in the cluster. Managed Node Groups automate the provisioning and lifecycle management of nodes, allowing you to (1) update, create, or terminate nodes with a single operation, and (2) automatically drain nodes and try to ensure graceful node termination.
Using Managed Node Groups is generally better when leveraging Spot instances in an EKS cluster because they provide built-in support for diversifying Spot instance types within the same node group. By spreading the workload across different instance types, you can reduce the impact of Spot instance interruptions on your application for better reliability.
To create a Managed Node Group you can use the eksctl CLI and define the necessary parameters like instance type, minimum and maximum nodes, etc., in a YAML configuration file. Here’s an example for reference:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: your-eks-cluster
region: your-region
managedNodeGroups:
- name: managed-ng
minSize: 2
maxSize: 5
instanceTypes:
- t3.small
- t3.medium
To apply the configuration and create the Managed Node Group, you can run the following eksctl command:
eksctl create nodegroup -f your-config.yaml
When you create a Managed Node Group using the eksctl CLI, an Auto Scaling Group (ASG) is created automatically as part of the Managed Node Group configuration. The ASG is responsible for managing the underlying EC2 instances that constitute the nodes in the managed node group. Cluster Autoscaler communicates with the ASG to adjust the DesiredCapacity and perform scaling operations.
- Create node groups specifically for Spot Instances: One way you can leverage Spot Instances in your EKS cluster is by creating node groups that only use Spot Instances. This is a good option when the workloads that will run in the node group do not require an On-Demand base capacity. Here’s an example of how to accomplish this via a config file:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: your-eks-cluster
region: your-region
managedNodeGroups:
– name: managed-spot-ng
instanceTypes: [“c3.large”,”c4.large”,”c5.large”,”c5d.large”]
spot: true
In this file, we just set the Spot option to true for the node group in which you want to use Spot Instances. You can tweak other settings like desiredCapacity and instanceType based on your specific needs.
- Use a Mixed Instance Policy: Mixed instance policies enable you to deploy a combination of On-Demand and Spot instances within the same node group. This is a good option for when you want to specify an On-Demand base capacity for your node group.
To accomplish this, you’ll need to update the Auto Scaling Group associated with your node group. In the AWS Console, navigate to EC2 Auto Scaling Groups, and specify the percentage of Spot and On-demand Instances in the Instance Purchase Options section.
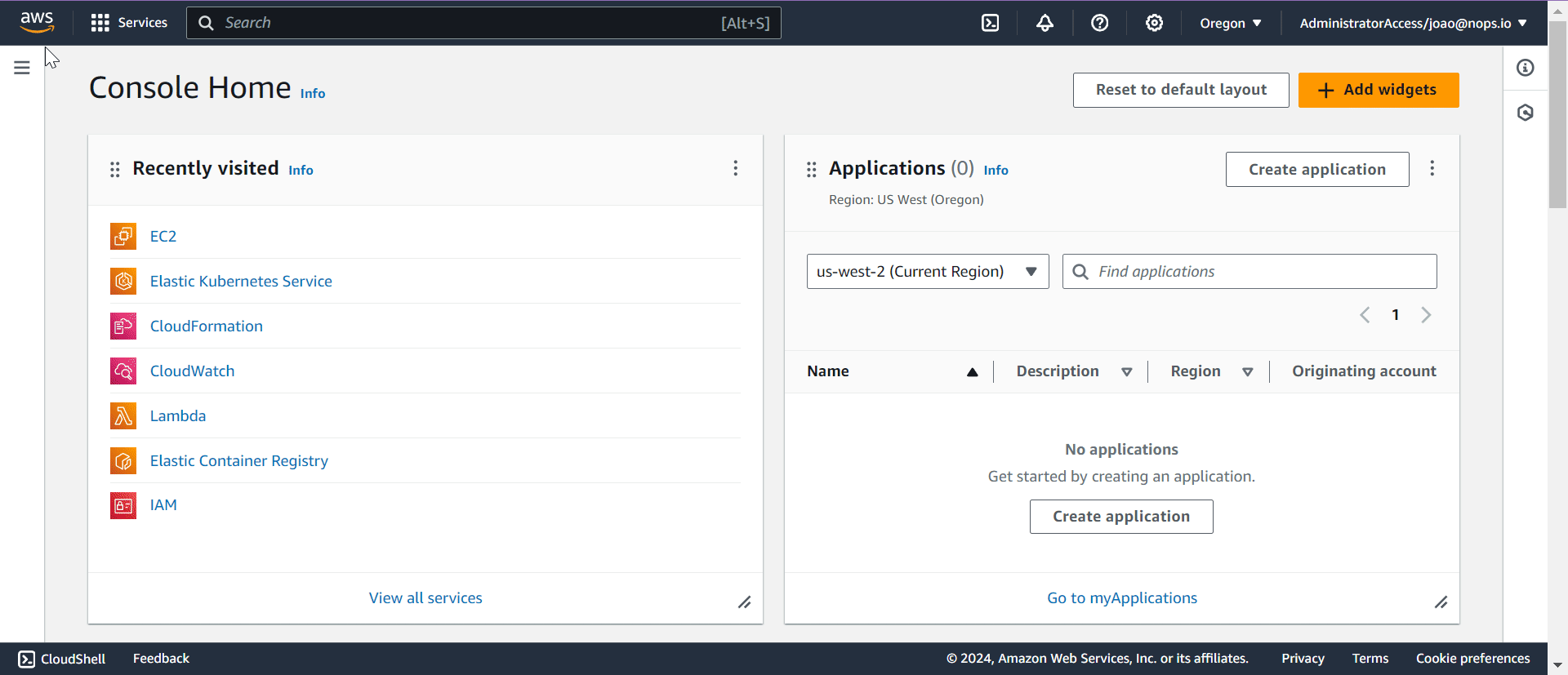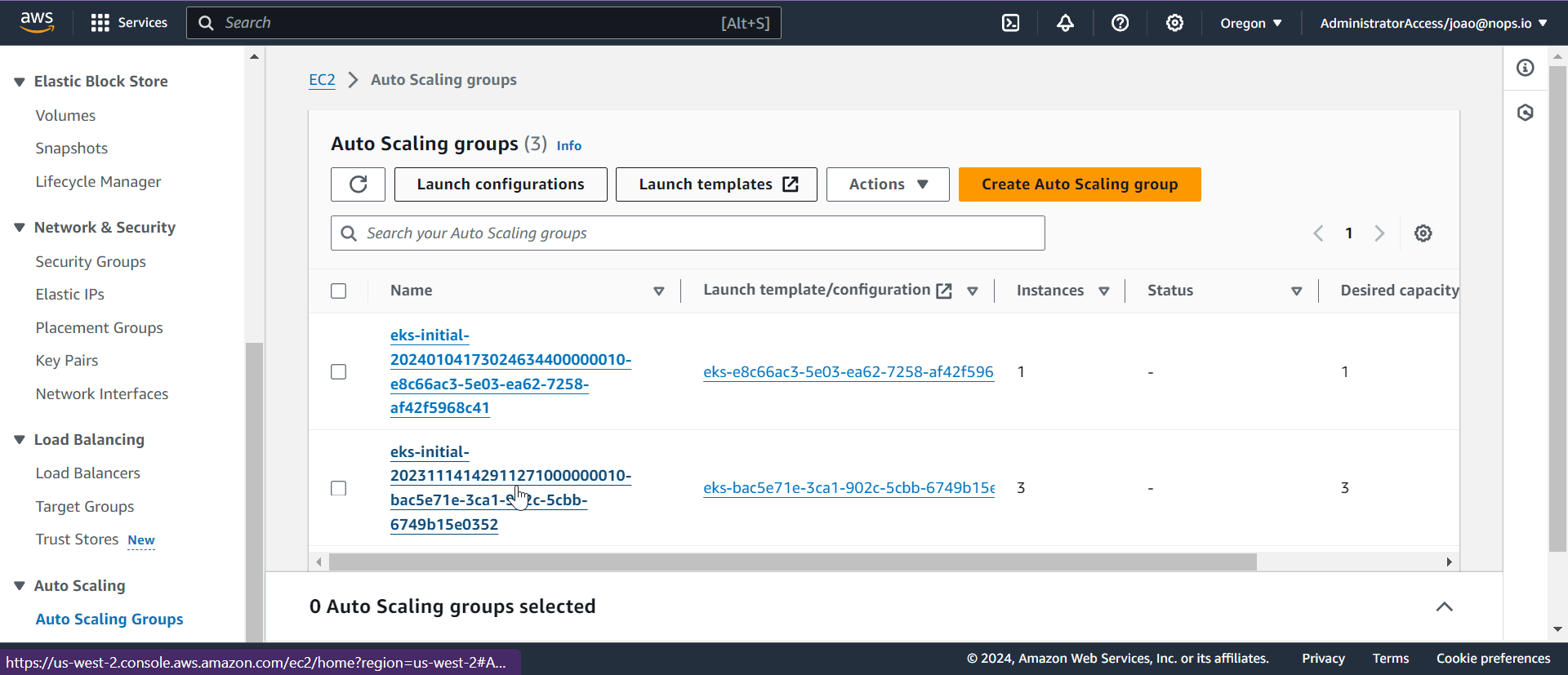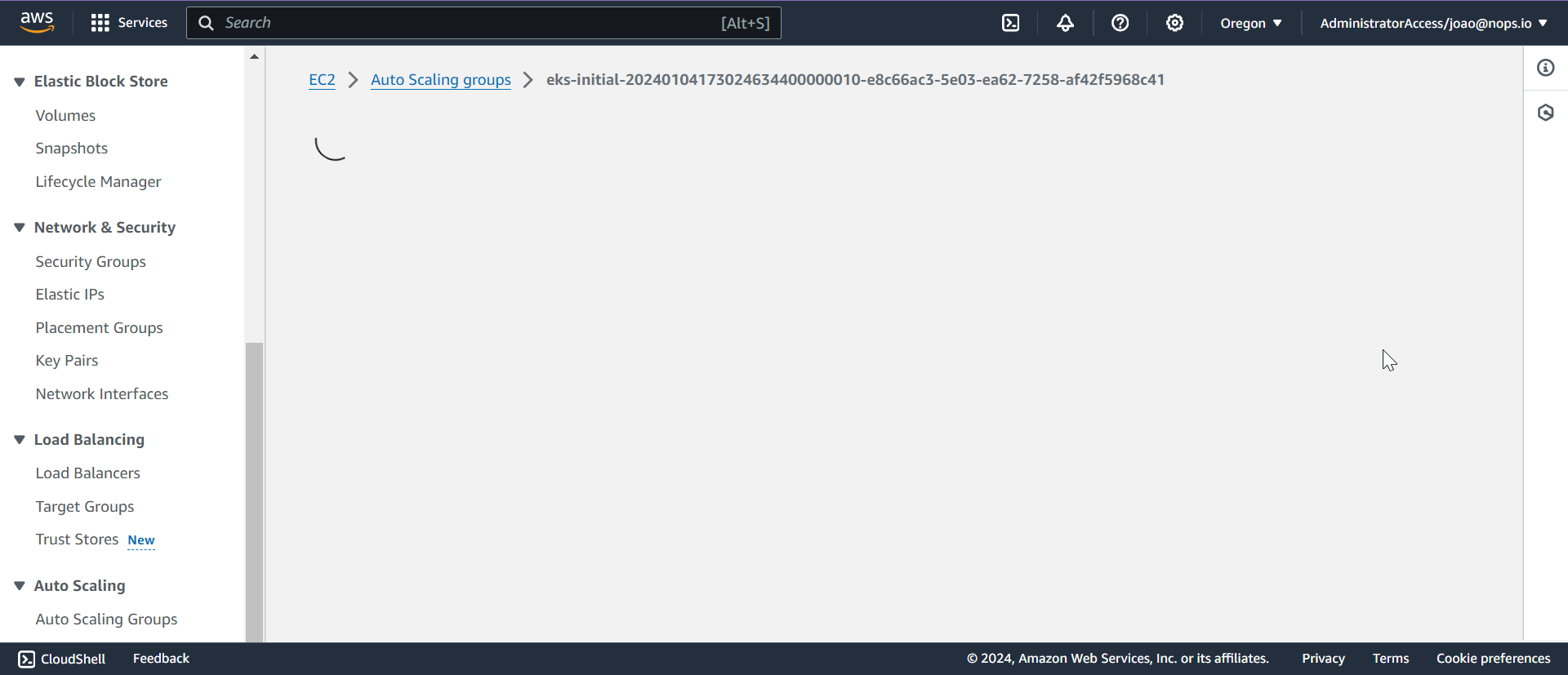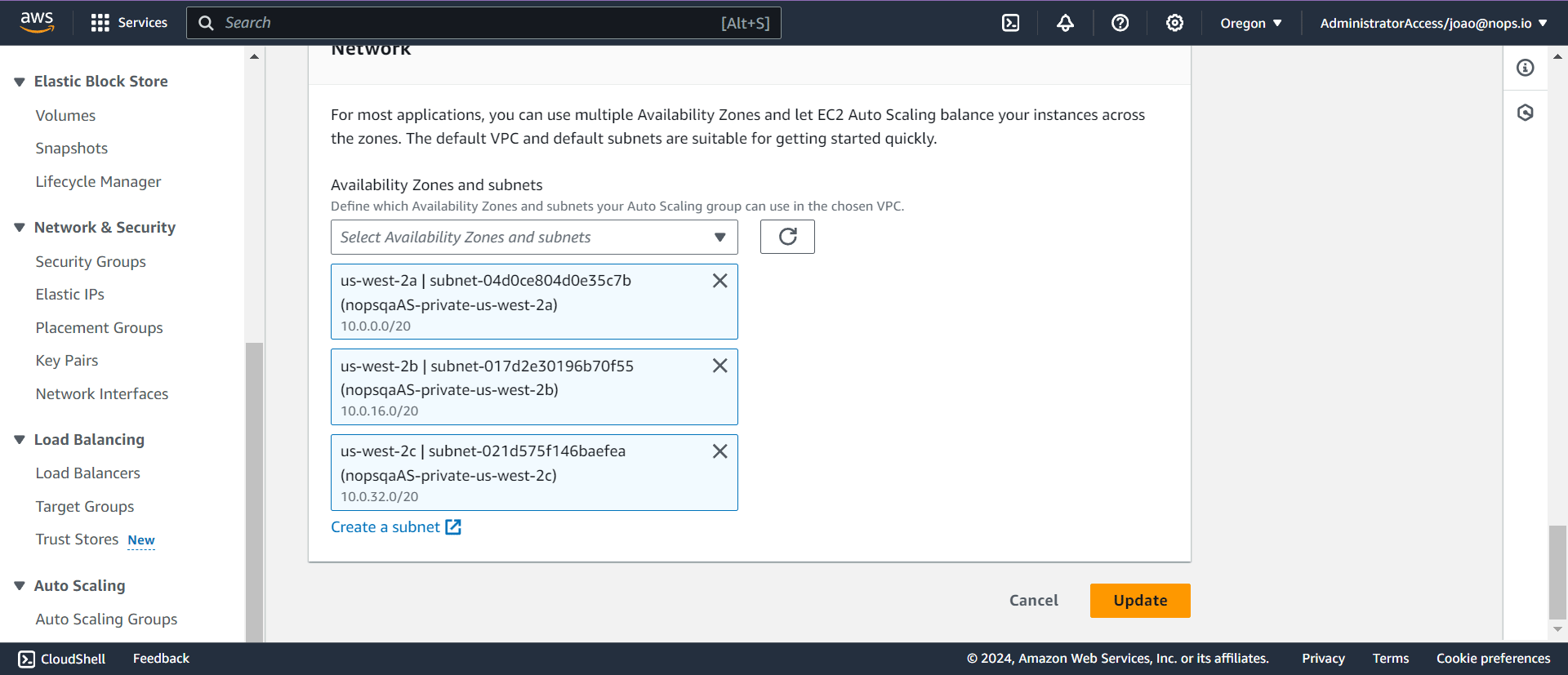
When implementing the MixedInstancePolicy, ensure the selection of a diverse range of instance types that demonstrate uniformity in terms of CPU, memory, and GPU configurations.
When scaling the ASG, instances are added or removed based on demand. It can be problematic when instances have different capacities — leading to uneven distribution on workloads and overloading or underutilizing specific instances. This can impact the overall performance and responsiveness of the applications running on the EKS cluster, as well as lead to wasteful spending when the cluster could be using cheaper instances instead.
While uniformity in terms of CPU, memory, and GPU configurations is essential, embracing a diverse range of instance types is also crucial for cost savings, especially when incorporating Spot instances into the cluster. Selecting only one instance type, or a small number of instance types, might mean that you don’t have adequate options available in the Spot market to leverage for reliable cost savings.
- Configure Pod Disruption Budgets: A Pod Disruption Budget allows you to limit the number of concurrent disruptions a group of pods can experience. When it comes time for Cluster Autoscaler to scale down the cluster, PDBs ensure that node removals doesn’t disrupt too many pods simultaneously and degrade service.
In sum, you can combine Cluster Autoscaler and Pod Disruption Budgets to balance efficient resource utilization and high availability. The Autoscaler ensures that your cluster has the right amount of resources, and PDBs ensure that the removal of nodes doesn’t impact the availability of your applications.
A Pod Disruption Budget is especially beneficial when running workloads on Spot, because it can minimize the impact of Spot instance interruptions for the same reasons detailed above.
To configure a Pod Disruption Budget, you can use a YAML file to define the desired specifications. Below is an example YAML snippet illustrating a basic Pod Disruption Budget configuration:
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: example-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: your-app-label
Basic Pod Disruption Budget Configuration
In this example, the minAvailable field sets the minimum number of pods that must remain available during disruptions. The selector field specifies the labels used to select the pods affected by the disruption budget. Replace “your-app-label” with the appropriate label for your pods. This YAML snippet provides a foundation for configuring a PDB tailored to your specific deployment needs. Other important configurations that you might need to use are:
- maxDisruptions:
Limits the total number of disruptions that can occur simultaneously. This parameter helps prevent excessive simultaneous pod terminations.
spec:
maxDisruptions: 1
- disruptionsAllowed:
If set to 0, this effectively prevents any voluntary disruptions. This can be useful in scenarios where you want to temporarily freeze any planned disruptions.
spec:
disruptionsAllowed: 0