Mastering Spot in EKS: Lifecycle of a Spot Refresh, PDBs, & Best Practices
When you think about AWS Spot instances in EKS, the first thing that comes to mind is interruption. But in reality, Spot can be as reliable as On-Demand — with discounts reaching up to 90%!
At nOps, we process $1.5+ billion of AWS spend; needless to say, we have a mission-critical workload. And we regularly save 50-60%+ of our own Kubernetes cost using Spot.
Find out how you can, too. In this blog post, we’ll walk you through the node refresh lifecycle (what happens when Spot refresh occurs for EKS clusters), and how to handle these refreshes to confidently and reliably run workloads on Spot.
What is a Spot Refresh?
In any computing environment, machines and services can fail; networks can go offline; and sometimes machines have to be taken offline for maintenance. Accordingly, most commercial software packages (i.e. databases and applications) are designed to be tolerant to shutdown and restart, without loss of data.
In a cloud environment, compute vendors offer steep discounts for using interruptible resources, otherwise known as “Spot”, to even out demand spikes. In AWS, this is available on a market, where the fungible nature of the compute instances allows AWS to set prices through competitive bidding between users. While this can enable significant cost savings, it also introduces the possibility that an instance will be interrupted. Let’s talk about what happens when this occurs.
Interruption Protocol
In the event of a Spot Instance interruption, the default AWS behavior is to notify you 2 minutes in advance via EventBridge, allowing an installed Node Termination Handler to cordon and drain any affected node.
In addition, AWS can issue Instance Rebalance and AZ Rebalance notifications, to give advanced warning when trend lines indicate that either an instance type or an AZ are expected to see a pricing spike.
Let’s discuss what happens to workloads in the unlikely event of a node recall, because it’s a very carefully controlled process that is designed to give processes every opportunity to gracefully shut down and preserve data.
Voluntary and Involuntary Disruptions
When we talk about disruptions, we have to acknowledge that some are totally unavoidable. Among those are system crashes, kernel panics, OOM events, or network partitions.
There’s not much we can do about those, but fortunately they’re very rare in practice. What we can do is turn an involuntary disruption into a voluntary one using our ML Spot Termination Prediction algorithm.
This allows us to identify nodes that will be lost due to Spot market identifications early, while there’s time to safely store any critical data or drain remaining connections. However, we must also provide some information to the API server to make sure it knows which pods to evict in what order. The primary tool we can use to manage voluntary evictions is the Pod Disruption Budget. Let’s talk about how to use these effectively.
Pod Disruption Budgets
The Kubernetes API offers a PodDisruptionBudget API which is the key to unlocking the power to manage pod evictions. The way it works is surprisingly simple. To begin, we want to make sure it lives in the same namespace as our sensitive deployment.
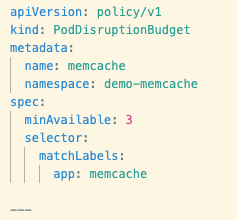
To identify the controller of our pods (Deployment, StatefulSet, etc.) we use a label, much like Deployments use labels to manage their Pods. It’s important to remember that the combination of labels should be unique among controllers in this namespace, and that no more than one Pod Disruption Budget (PDB) will describe each pod. We then need to name it and set the policy.
Pod Disruption Budget Specs
The core component of a PDB is the policy itself, specified as the spec map. The optional keys for this map are either maxUnavailable or minAvailable which describe either the max that the number of deployed pods that can be missing or the minimum that must always be present respectively for a voluntary eviction call to be processed. If the specification is not met, then the eviction call will be refused and the caller will be asked to retry later. But PDBs are a powerful tool, and it’s important to be careful about how we use them.
Related Content
The Ultimate Guide to Karpenter
Maximizing efficiency, stability, and cost savings in Kubernetes clusters
Download Now
Best Practices for PDBs
When writing up your own PDBs, it’s important to consider the following:
- Is there a quorum? How many pods are required to maintain quorum?
- How do missing pods affect SLA and response times?
- What is the maximum number of pods that can be missing and still provide adequate service?
In addition, it’s important to remember these caveats:
- A PDB with no Selector will affect every pod in its namespace.
- PDBs use the spec.scale value in the controller’s definition to determine what a full set contains.
- Without this information, maxUnavailable specifications are not available.
- If there is no budget for unavailable pods, there can be no voluntary evictions.
- Pods will have a terminationGracePeriodSeconds that will determine how long the kubelet will wait after sending SIGTERM before deleting the pod’s cgroup.
- The default is 30 seconds.
- When selecting Spot instances, it’s crucial to pick the instance families that offer the highest reliability to get the most out of your Spot placements. This is where nOps can help.
Early Warning & Spot Reliability Scoring
A two-minute warning may not be adequate for many workloads. That’s why nOps used statistical analysis and Machine Learning to build an early warning system that detects price anomalies and can predict preemption in the dynamic Spot market with more than a 60-minute notice.
Using this system, we’re able to guarantee that the availability of services running in AWS Spot-backed clusters can be assured. In the event of a predicted price spike, our agent will cordon and drain nodes that are at an elevated risk of interruption during the next hour.
nOps Compute Copilot Proactively Manages Spot for You
At nOps, our class-leading ML is able to get the best prices and the highest reliability for Spot. We offer a fully turnkey solution, providing you with a simple management dashboard to configure your savings. Once configured, it intelligently provisions all your compute automatically so you get the best pricing available without sacrificing any reliability. And with awareness of all your commitments, it ensures you’re on the most reliable and cost effective blend of Spot, Savings Plans, Reserved Instances, and On-Demand. Let’s summarize how using Compute Copilot makes saving with Spot easy and hassle-free.
Without nOps | With nOps |
You only have a 2-minute Spot termination warning | Copilot’s ML automatically predicts Spot termination 60 minutes in advance |
Your containers must be able to sustain sudden Spot termination with zero impact | Copilot continually moves your workloads onto diverse instance types, gracefully draining nodes in the process |
Spot market pricing & availability is constantly changing | Copilot automatically selects the safest, cheapest Spot instances for you, or On-Demand if needed |
Here are the key benefits:
- Effortless cost savings. Copilot automatically selects the optimal instance types for you, freeing up your time to focus on building and innovating.
- Enterprise-grade SLAs for the highest standards of reliability. Run production and mission-critical workloads on Spot with complete confidence.
- No vendor-lock in. Just plug in your preferred AWS-native service (EC2 ASG, EC2 for Batch, EKS with Karpenter or Cluster Autoscaler…) to start saving effortlessly, and change your mind at any time.
- No upfront cost. You pay only a percentage of your realized savings, making adoption risk-free.
nOps manages over $1.5 billion in cloud spend and was recently ranked #1 in G2’s cloud cost management category. Join our customers using nOps to slash your cloud costs and leverage Spot effortlessly by booking a demo today.