

How to Right Size AWS EC2: Tips, Tricks & Datadog Guide
As cloud bills continue to rise amid economic uncertainty, cost and resource optimization are becoming mission-critical. Many organizations are currently overspending, with EC2 (followed by RDS and S3) likely the most expensive item on your AWS bill.
That’s where right sizing comes in. By analyzing historical usage and performance, you can identify and right size instances that are not consuming all the resources that are currently available to them.
We’ve all been there: once in-demand applications become less busy, usage patterns evolve. And amid high-priority new features, oversized instances can easily go unnoticed.
Right sizing these resources to their proper level goes a long way toward taming cloud costs. In this blog post, we’ll take you through a comprehensive, hands-on guide with step-by-step instructions and tips for right sizing with Datadog metrics.
Why is it challenging to right size effectively?
There are two major challenges that make it difficult to right size effectively.
#1: Right sizing recommendations are frequently wrong. Vast amounts of right sizing recommendations are available through tools such as AWS Trusted Advisor. Yet, it is difficult to know which recommendations to accept.
Reliable recommendations require granular historical data on memory, utilization, network bandwidth, volume size, and more. This data is difficult to collect and analyze, and there isn’t a single source for all of the metrics that you need. As a result, right sizing recommendations are often untrustworthy.
#2: Acting on recommendations is time-consuming. Cumbersome resource investigation, ticketing processes, and manually editing Terraform means that a right sizing initiative can be an IT resource time sink. And as dynamic ecosystem and business needs continually change, you have to do it again.
Related Content
The Definitive Guide to AWS Rightsizing
Cut cloud waste and pay only for what you need
Download Now
How to use Datadog metrics to make effective right sizing decisions
Let’s start by solving problem #1. To make accurate and reliable right sizing decisions, you need: CPU, storage, networking and memory. While you can collect the first three through AWS CloudWatch, you’ll need a custom engineering solution or third-party tool to factor in memory data.
In the interest of simplicity and saving time, we recommend using an existing monitoring agent such as Datadog to gather the metrics you need. Here’s how to do it.
Step-by-step guide:
1. Sign up for Datadog
2. Integrate your cloud resources (e.g. EC2, RDS) with your Datadog account. Within 15-30 minutes, data will start flowing into Datadog
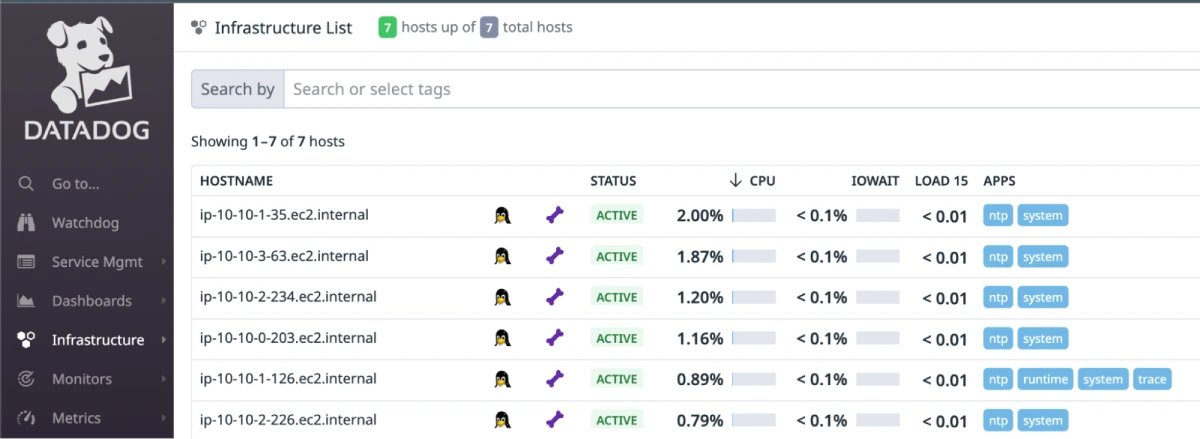
3. After integration, we generally recommend that you wait 30 days to get the data you need for solid recommendations. The longer you collect data, the more reliable of a decision you can make.
If your workload is predictable, it may not be necessary to wait a full 30 days — on the other hand, more variable workloads may need longer.
4. Go to the Datadog dashboard → Infrastructure → HOSTNAME → Metrics
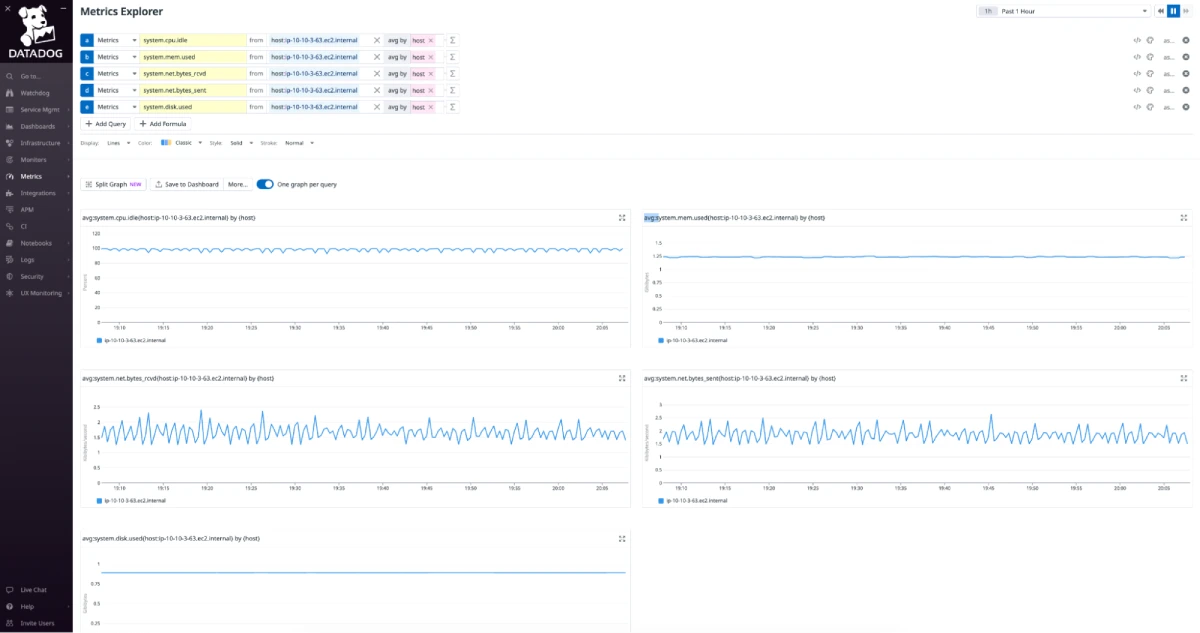
5. Evaluate 4 key metrics: vCPU, Memory, Storage and Network.
Compare the current usage of each metric against two baselines: one for your current instance type and another for the next smaller instance type. If your maximum usage is less than 80% of the smaller instance’s baseline (i.e., you’re using 20% less than what the smaller instance typically supports), it’s safe to consider downsizing to that smaller instance type.
Visible in the screenshot above, here are the Datadog metrics that you need to pay attention to in order to make good right sizing decisions.
- cpu.idle
- mem.used
- net.bytes_rcvd
- net.bytes_sent
- disk.used
Let’s dig into each metric in a little more detail.
cpu.idle is a strong CPU metric in Datadog. When inverted, it can give you the CPU utilization percentage — so you can make an informed decision as to whether the current CPU resource is fully utilized or if downsizing to a lower instance type is possible.
Example: Say that you have an m7g.2xlarge (8 cores) and your cpu.idle in Datadog is 65%, meaning the CPU utilization is 35%. Comparing this to an m7g.xlarge (4 cores, or 50% of the larger instance size), the 35% usage is well below the 50% threshold, meaning it can be downsized. (AWS typically recommends downsizing if utilization is at or below 40%).
Mem.used is another key metric, and it’s the simplest of all to use. Like CPU utilization if you are using 40% or less of your current memory capacity you can downsize to an immediate lower instance type. This applies to instance families like m7g, where each step down halves the resources.
However, if the next lower instance doesn’t halve resources, aim to use up to 80% of its capacity. Based on this utilization, decide if downsizing is appropriate.
Net.bytes_rcvd and net-bytes_sent measure network utilization, which is important for workloads relying on high bandwidth. To guage your network utilization, add bytes received and bytes sent together for total bandwidth used.
Note that Datadog measures in bytes, while AWS uses bits. To compare for right sizing, divide AWS’s figure by 8 to convert to bytes. Then, apply the same logic as with other metrics: if utilization is 40% or less of the current type, or up to 80% of the next lower type, downsizing might be appropriate.
Disc.used measures the utilization of ephemeral (nonpersistent) storage on instances, such as r7gd or lm4gn. This is not to be confused with EBS storage (persistent volumes, which are not affected by right sizing).
This metric shows the total used storage, which you should compare with both your current instance’s capacity and that of the next lower instance type. Follow the same 40/80% utilization guideline: if your usage is 40% or less of the current type or up to 80% of the lower type, downsizing may be a viable option.
6. Note that these recommendations hold as long as you are planning to right size within the same instance family. When right sizing outside the instance family, you also need to consider CPU architecture, storage type, storage speed, and other factors.
More right sizing tips and best practices
Here are more tips to keep in mind as you right size your EC2 instances.
Follow AWS recommendations for CPU and memory
AWS’s general rule for EC2 instances is that if your maximum CPU and memory usage is less than 40% over a four-week period, you can safely reduce capacity.
For compute-optimized instances, some best practices are to:
- Focus on very recent instance data (such as the previous month), as old data may not be actionable
- Focus on instances that have run for at least half the time you’re observing
- Ignore burstable (T2) instance families, as they are designed to run at a low CPU % for extended periods
Select the right instance type and family
AWS offers hundreds of instance types at different prices, comprising varying combinations of CPU, memory, storage, and networking capacity. You’ll want to select for the lowest price per unit of the metric most important for your workload.
You can right size an instance by migrating to a different machine within the same instance family or by migrating to another instance family.
When migrating within the same instance family, you need to consider vCPU, memory, network throughput, and ephemeral storage. If you opt for migration to a different instance family, ensure compatibility between your current and new instance types concerning virtualization type, network, and platform.
Turn off idle instances
One easy way to reduce operational costs is to turn off instances that are no longer in use. The AWS guideline states that it’s safe to stop or terminate instances that have been idle for more than two weeks.
Some key considerations for terminating instances include (1) who owns it (2) what is the potential impact of terminating (3) how hard is it to recreate.
Another simple way to reduce costs is to stop instances used in development and production during hours when these instances are not in use. Assuming a 50-hour work week, you can save 70% by automatically stopping dev/test/production instances during non-business hours. Many tools are available for scheduling, including Amazon EC2 Scheduler, AWS Lambda, and AWS Data Pipeline. Or, third-party tools such as nSwitch use AI to learn your usage patterns and automate the process for you.
Monitor your resource usage over time
To achieve cost optimization, right sizing becomes an ongoing process. Even if you right size workloads initially, changing performance and capacity requirements can result in underused or idle resources that drive unnecessary AWS costs.
As you monitor current performance, identify the following usage needs and patterns so that you can take advantage of potential right sizing options:
- Steady state –When workloads maintain consistent levels over time, and you can forecast compute needs accurately, Reserved Instances offer significant savings.
- Variable, but predictable – If your load changes predictably, consider EC2 Auto Scaling to handle predictable fluctuations in traffic.
- Dev/test/production – These can generally be turned off during non-business hours. (You’ll need to rely on tagging to identify dev/test/production instances.)
- Temporary – For temporary workloads that have flexible start times and can be interrupted, consider using an Amazon EC2 Spot Instance.
Right sizing with nOps
Right sizing can save substantially on AWS costs — but engineers often don’t take action on recommendations because (1) they don’t trust them, and (2) implementing right sizing recommendations is time consuming.
nOps’s right sizing solution was created to address these challenges. By integrating with your Datadog and Terraform, nOps performs all of the calculations described above automatically, and allows you to implement recommendations with one click.
As a result, you get all the cost-saving benefits of right sizing with zero engineering effort.
Here’s how it works.
1. Plug in Datadog to collect all of the metrics needed for trustworthy recommendations. (Essentially, the metrics recommended above). The platform analyzes your instances and takes all the relevant info into account, such as the metrics necessary for your particular operating system.
2. We take the maximum value recorded for each metric.
For each instance in your environment, we make the following calculations:
- Max Disk usage
- Max Network usage
- Max RAM utilization
- Max CPU utilization
3. We perform our right sizing algorithm. The algorithm compares maximum recorded usage against the capacity of a lower instance type, multiplied by a threshold value that accounts for potential future usage spikes. AWS Recommends using 80% of the lower size’s capacity as a benchmark. In our experience, a threshold as high as 90% may be suitable in the case of low-risk environments like UAT and QA.
We continuously monitor a 30-day sample of your utilization data and match your resource requirements to the latest offerings in the AWS pricing catalog, ensuring the best fit for your specific use case.
The nOps Advantage
Complete confidence in recommendations. Datadog’s comprehensive logging and monitoring platform provides nOps’s state-of-the-art ML engine with the exact data needed for highly accurate right sizing recommendations. Recommendations are visualized in an easy-to-scan dashboard which proves reliability and accuracy to engineers beyond a shadow of a doubt — giving them the confidence to take action.
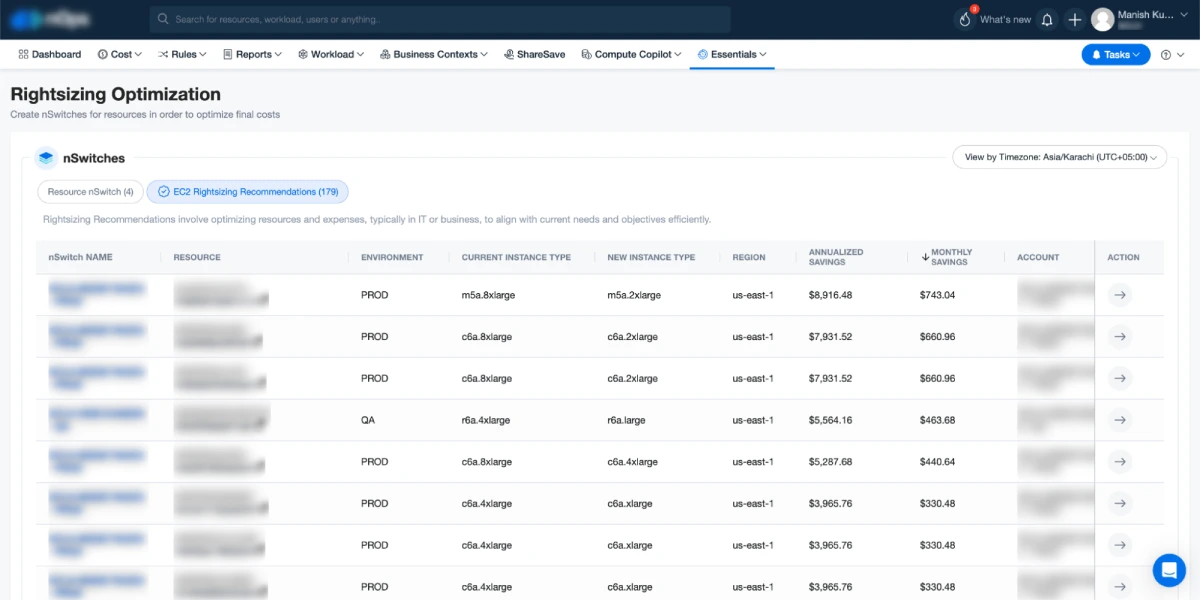
Save lots of time. With the platform, it takes five seconds to make a changeset, accept the changeset, and push it out. nOps integrates with your Terraform and Eventbridge to automate away all the work and complexity, freeing up engineers to focus on building. One click to accept the recommendation and you are done.
Significant cost savings. When engineers don’t act on right sizing recommendations, underutilized and idle resources continue to drive unnecessary AWS costs — leading to thousands in missed savings accumulating every day. By making it pain-free, nOps empowers engineers to actually right size within seconds.
Hands-off resource optimization. nOps is aware of your full AWS ecosystem and commitments. Once you accept right sizing recommendations, nOps can manage your compute with our Compute Copilot to ensure you are always on the optimal blend of RI, SP and Spot for cost and reliability.
nOps was recently ranked #1 in G2’s cloud cost management category. Join our customers using nOps to slash your cloud costs and leverage automation with complete confidence by booking a demo today!
How to Right Size AWS EC2: Tips, Tricks & Datadog Guide


























