

5 AWS Spot Reliability Myths Holding Back Your Savings
When you think about Spot, the first thing that comes to mind is inexpensive but unreliable. But in reality, Spot can be as reliable as On-Demand — and it can save you up to 70% on your compute cost.
In this blog post, we’ll review some of the reasons why Spot gets a bad reputation and debunk some common myths about Spot.
Before diving in, let’s talk numbers. We process $1+ billion of AWS spend through our platform; needless to say, we have a mission-critical workload.
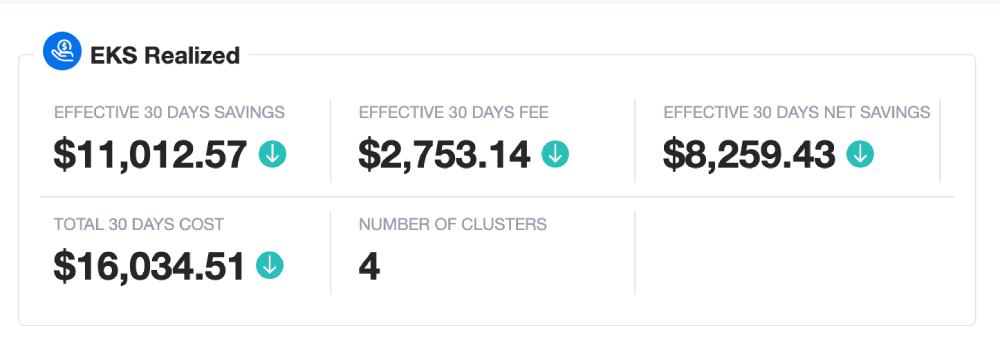
A screenshot from the nOps platform’s production environment shows we save over 51% of our own Kubernetes cost using Spot.
We’ll explain how, but first let’s briefly learn a bit more about Spot Instances.
What are Spot instances?
AWS Spot Instances are spare AWS capacity that users can purchase at a heavy discount.
Why is Spot perceived as unreliable?
Spot provides the highest potential savings over On-Demand. However, AWS can terminate these instances with a two-minute warning. This is known as a Spot Instance Interruption.
Here’s how Spot interruptions work:
Interruption Notification: AWS notifies you two minutes before your Spot Instance is interrupted. This notification comes as an event from the EC2 metadata service.
Interruption Reasons: Interruptions can occur for several reasons. For example, when AWS requires the capacity for other tasks (such as supplying On-Demand or RIs), it suspends Spot Instances to fulfill these requests. Or, the market price might surpass your maximum bid for the Spot Instance.
Handling Interruptions: You can choose how your Spot Instances respond to an interruption notice by specifying an interruption behavior (stop, terminate, hibernate) when you request your Spot Instances.
Spot Instance Rebalancing: AWS also provides a rebalancing recommendation when there is a higher chance of interruption. This allows you to proactively manage the Spot Instance, for example, by launching replacement instances.
Saving State: It is advisable to design your applications to be fault-tolerant so that they can save state and move to another instance if necessary.
Using Spot Instances effectively requires a different approach compared to On-Demand or Reserved Instances, as you must design your systems to handle possible interruptions and restarts.
Let’s dive into some of the common myths.
Myth 1: I don’t need Spot because I can cover all of my compute usage with Saving Plans and Reserved Instances
Often, teams think they can cover 100% of their compute by buying Saving Plans or Reserved Instances.
What we know from processing $1 billion of AWS spend is that it’s typically only cost-effective to cover about half of On-Demand usage with commitments.
Why? SPs and RIs apply hourly, and operate on a “use it or lose it” basis. If you commit to $10 every hour but only consume $6 of services in a particular hour, you will lose the remaining $4. Because you can’t cover spikes with commitments, most companies are left with 40-50% of compute usage On-Demand, the highest AWS pricing tier.
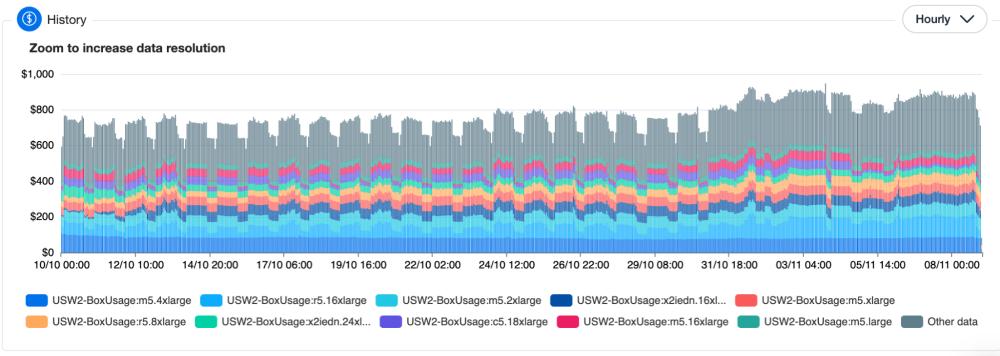
That means that the one and only way to get the lowest compute costs is to use a mix of Saving Plans, Reserved Instances, and Spot.
Related Content
The Ultimate Guide to AWS Commitments
Best practices and advanced strategies for maximizing AWS discounts
Download Now
Myth 2: Spot isn’t stable
Most of the organizations we’ve talked to believe Spot terminates at an alarmingly higher rate than it actually does (50% of the time!?) — but the reality is that less than 5% of Spot instances are terminated in any given month.
Here is a graph that shows real historical data charting the likelihood of Spot instance termination. The reality is that less than 5% of Spot instances are terminated in any given month.
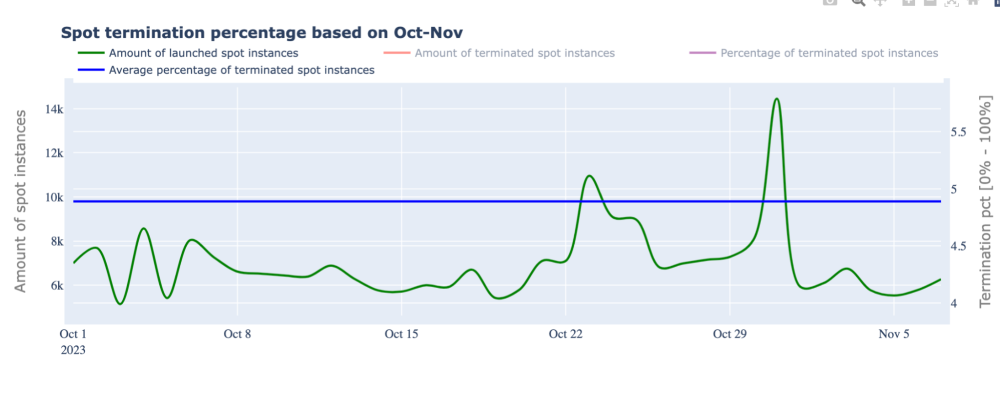
Furthermore, certain types of instances are much more likely to terminate than others.
AWS has tens of thousands of Spot capacity pools across regions, AZs, types, sizes and operating systems. As availability changes dynamically depending on supply and demand, Machine Learning algorithms can analyze historical data and current EC2 consumption to accurately predict Spot termination risk.
Because we process $1 billion in cloud spend, nOps has access to the data as well as a deep understanding of cloud infrastructure and workload requirements to reliably predict Spot market shifts.
Every 10 minutes, we analyze the Spot market to develop risk scoring for each instance type, so we can predict termination at a minimum of 60 minutes in advance, and continually move you onto less risky instance types. By predicting termination and replacing instances, Compute Copilot automatically provisions and scales your workloads in the most efficient way possible. The result is that you benefit from Spot pricing with the utmost confidence in reliability.
Myth 3: My workload can only work on a single-instance type
Many people have a restrictive view of their workload needs. You probably have minimum workload requirements; you don’t necessarily have maximum workload requirements. And when it comes to Spot, you can often get cheaper instance types – even if they are bigger. So, you don’t necessarily need to be locked down to a single-instance type without compromising on performance.
nOps Compute Copilot automatically selects diverse instance types based on your memory, CPU requirements, and architecture requirements.
Myth 4: Spot leads to downtime
Most compute in the cloud is dynamic and runs behind an Elastic Load Balancer or with Container Orchestration such as Kubernetes. These frameworks are designed to handle interruption; chances are that your application is scaling up and down already and handling it just fine.
Here is an example web workload.
Since it’s already handling interruption, why not run on Spot to save up to 70% of your compute cost?
Myth 5: You can only run stateless resources on Spot:
Not every workload is stateless in the cloud. Basic principles of high availability for stateless and data persistence workloads (persistent networking, persistent storage mounts, checkpointing, multi-az sharding/replication, and load balancing) allow these workloads to be effectively run on Spot. However, instance startup and restore times can still be challenging.
nOps Compute Copilot introduces advanced termination prediction, elegant replacement strategy, and instance diversification to solve these challenges. As a result, previously unfeasible workloads can now take advantage of the steep discounts Spot offers for available capacity.
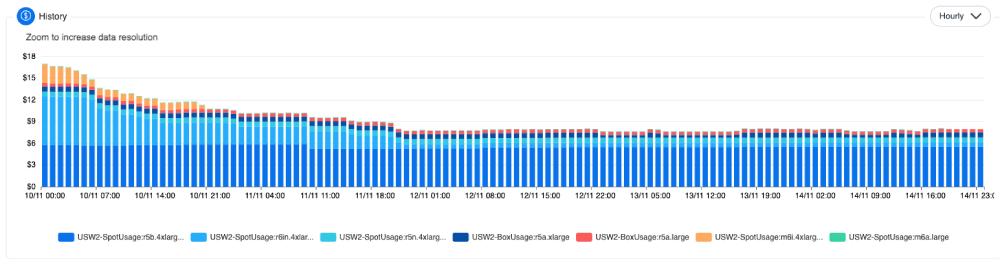
As one illustration, here is the nOps production environment Apache Druid high speed analytics database, which drives our most mission-critical workloads, running primarily Spot instances over time.
Spot pricing with On-Demand reliability: Compute Copilot
To truly optimize your AWS costs, it requires leveraging the right balance of Savings Plans, Reserved Instances, On-Demand, and Spot. Compute Copilot helps you find that right balance, automatically.
As macroeconomic conditions squeeze budgets and interest in Spot savings continues to grow, the nOps platform provides a simple and easy way for engineering teams to cost-optimize their compute.
Compute Copilot provides proprietary ML-driven management of Spot instances for the best price in real time. It continually analyzes market pricing and your existing commitments to ensure you are always on an optimal blend of instance types.
nOps was recently ranked #1 in G2’s cloud cost management category. Join our customers using Compute Copilot to save on Spot hands-free by booking a demo today!
5 AWS Spot Reliability Myths Holding Back Your Savings


























