DynamoDB Commitment Management Just Changed
For most of DynamoDB's life, there was exactly one way to commit your way to a discount, and it only worked on the part of your workload that already behaved itself. As of December 2025, that's no longer true. AWS Database Savings Plans extended commitment-based discounts to DynamoDB on-demand throughput for the first time, which means the fastest-growing, hardest-to-predict slice of your DynamoDB bill is finally addressable.
This reshapes how every team running DynamoDB at scale should think about coverage, and it exposes a gap that most organizations don't yet realize they have. This guide walks through the two commitment levers AWS now offers for DynamoDB, where each one wins, where each one strands you, and why the workloads with the most DynamoDB spend are usually the ones leaving the most savings on the table.
The shift hiding in plain sight: on-demand is now the default
To understand why the December 2025 change matters, you have to start with a change from a year earlier. In November 2024, AWS cut DynamoDB on-demand throughput pricing by 50% and reduced Global Tables replicated-write pricing by up to 67%. AWS was explicit about the intent: the change was meant to make on-demand the default and recommended mode for most DynamoDB workloads.
It worked. The price cut narrowed the per-request gap between on-demand and well-utilized provisioned capacity from roughly 10–12x down to 5–6x, which moved the break-even point substantially. Workloads sitting around 20–35% utilization, which previously justified the operational overhead of provisioned mode, became cheaper to simply run on-demand. AWS reinforced the direction in August 2025 by raising the provisioned-to-on-demand switching quota to four times per rolling 24-hour window.
The cumulative effect: more DynamoDB spend across the industry now lives in on-demand mode than at any point before, and the trend is one-directional. And until December 2025, none of that on-demand spend had any commitment discount available at all. It ran at full rates, full stop. That's the gap.
The two levers, and why they don't behave the same way
DynamoDB now has two commitment instruments that live in different capacity modes and optimize for opposite priorities.
Reserved Capacity: the deep discount with a narrow door
Reserved Capacity is the long-standing lever. Commit to a minimum level of provisioned read/write capacity for a one- or three-year term and receive a steep discount: roughly 54% on a one-year term and up to 77% on a three-year term. For a steady, predictable, high-utilization table, nothing else comes close on pure discount depth.
The catch is in the eligibility rules, which are tighter than most teams remember:
- Provisioned mode only. On-demand tables cannot use Reserved Capacity at all.
- Standard table class only. Standard-Infrequent Access tables are excluded.
- Single-region read/write capacity only. Replicated write capacity units (rWCU) for Global Tables, often a large share of a multi-region write bill, are not reservable.
- Storage, streams, backups, and data transfer are not covered. Reserved Capacity discounts provisioned throughput, nothing else.
- It's irreversible. Region, quantity, and term are locked at purchase. You can't cancel it, transfer it to another region or account, or get a refund. A re-architecture or a region migration leaves you paying for capacity you no longer use.
And the part teams underestimate most: choosing Reserved Capacity isn't a billing decision, it's a decision to run provisioned mode, which is a cost commitment, not a performance guarantee. The moment consumption exceeds your provisioned units, DynamoDB throttles immediately, with no grace period and no automatic spillover. Auto-scaling helps, but it reacts on a multi-minute lag and can't absorb a sudden spike. For a revenue-generating path, that throttling risk is exactly why so many teams chose on-demand in the first place.
Database Savings Plans: the flexible discount that finally reaches on-demand
Database Savings Plans (DSP), launched December 2025, work like other AWS Savings Plans: you commit to a fixed dollar-per-hour spend over a one-year term with no upfront payment, and AWS automatically applies discounted rates to eligible usage up to your commitment.
For DynamoDB specifically, DSP is significant for one reason above all others: it's the first commitment discount that reaches on-demand throughput. The estimated discount ranges:
- On-demand throughput: ~18%
- Provisioned capacity: ~12%
The discounts are shallower than Reserved Capacity, and DSP is currently 1-year only, with no 3-year option to match Reserved Capacity's deepest tier. But DSP makes up for depth with reach. A single dollar-per-hour commitment can simultaneously discount your provisioned tables, your on-demand tables, your Infrequent Access usage, and, critically, your Global Tables replicated writes, the exact spend Reserved Capacity can't touch. And because the commitment floats across services and regions rather than being pinned to a specific table, it keeps applying when your architecture shifts.
One rule that catches teams off guard
The two levers do not stack on the same capacity. AWS applies Reserved Capacity first; any remaining provisioned capacity is then eligible for Database Savings Plans. They're sequential layers, not additive discounts on the same unit. Any model that simply adds "77% plus 12%" is wrong, and it's the kind of error that erodes credibility with a finance team fast.
The pattern: your biggest DynamoDB workload is probably your weakest coverage
Here's the shape of a typical heavy-DynamoDB estate. There's a steady baseline: the throughput the application consumes 100% of the time. And there's a variable, spiky top: traffic that surges with product launches, events, time-of-day, or viral moments. The two layers have completely different economics.
The well-architected move is to split them: put the steady baseline in provisioned mode with Reserved Capacity to capture the deep discount, and keep the spiky top on on-demand because the cost of over-provisioning (or worse, throttling during a surge) outweighs the discount you'd capture. That's not a workaround. For high peak-to-average workloads, on-demand is the correct engineering decision.
The problem is what happens next. Most teams get the baseline-on-Reserved-Capacity part half-right and then stop. The spiky layer sits on full-rate on-demand because, until six months ago, there was no other option. Even teams that did everything right by the standards of early 2025 now have a layer of spend that became discountable in December and haven't acted on it.
So the organizations with the most DynamoDB spend, the ones running large, spiky, on-demand-weighted workloads, frequently have the lowest effective coverage on their single largest line item. Their biggest spend and their weakest commitment story are the same workload. That's the opportunity hiding in most DynamoDB bills today.
A decision framework: which lever for which spend
"Separate the layers" is easy to say and harder to operationalize, because DynamoDB doesn't hand you a neat label on each table. The property that does most of the sorting is a workload's peak-to-average ratio: how far its spikes run above its typical load. Utilization is a secondary check, and a slippery one: on an auto-scaled provisioned table, utilization is pinned near the scaler's target by design, so what really decides whether provisioned mode is viable is spikiness and how fast it arrives relative to auto-scaling's multi-minute reaction lag.
Lean provisioned + Reserved Capacity when spikes are shallow (a peak-to-average ratio under roughly 3:1) and the load is steady enough that auto-scaling can track it without throttling. This is always-on traffic: a backing store for a core service, a table with a flat daily curve. Here the deep Reserved Capacity discount (up to 77% on a 3-year term) is real and capturable. Size the commitment to the trough of the baseline, not its average, so scaling troughs never leave you paying for capacity you don't provision.
Lean on-demand + Database Savings Plans when the peak-to-average ratio exceeds roughly 5:1, or the traffic is genuinely unpredictable (event-driven surges, launch spikes, viral moments), where auto-scaling's lag means provisioned mode either throttles during the spike or over-provisions for it. On-demand is the correct call, and since December 2025 you can finally commit against it: DSP at ~18% on the floor of that usage. The same goes for two kinds of spend Reserved Capacity can't touch at all: Standard-Infrequent Access tables and Global Tables replicated writes, both covered from the same DSP commitment.
The messy middle is where the real money is, and where static rules fail. Two cases land here. One is the 3:1–5:1 ratio band: predictable enough to want a commitment, variable enough that any fixed one is wrong within a quarter. Think steady on weekdays, spiking on weekends, or a baseline creeping upward as a feature gains adoption. The other is a cost-versus-risk judgment call. After the November 2024 cut, provisioned's per-request edge at full utilization narrowed to roughly 5–6x (from 10–12x), putting the raw cost break-even near ~20% sustained utilization. Yet practitioners don't favor provisioned until ~40%, because the gap between is eaten by auto-scaling headroom and throttling risk. That ~20–40% band is the judgment zone: cost says provisioned, but operational risk may say on-demand. You accept a slightly higher bill to avoid throttling traffic you can't confidently predict. Neither case has an answer you set once: commit to the reliable floor and let the rest float, re-sorting as the floor moves.
That last category is what most DynamoDB estates are mostly made of, and it's the reason the next section matters.
Why a one-time purchase can't solve this
Even teams that recognize the gap tend to attack it the traditional way: analyze a few months of usage, forecast forward, and buy a large batch of commitments once a quarter to cover 70–85% of expected demand. That approach has a structural flaw for DynamoDB specifically: the workload shape keeps moving. Tables get added and retired. Traffic shifts between regions. A new game mode or feature launch changes the baseline overnight. A batch commitment sized to last quarter's curve is stranded the moment the curve moves, and there's no recourse until the term expires.
This is why the more effective model is intelligent layering: instead of one large commitment with a single maturity date, you hold many small commitments with staggered expirations, and you continuously decide whether to renew, increase, or let each one lapse based on current usage. Because each increment is small, you can push coverage aggressively, toward 90%+, without the downside risk of a single oversized bet going wrong. And because some portion of the layer is always near maturity, your effective lock-in stays low even when you're using 1-year terms. Done continuously, this approaches the discount depth of a longer commitment without the multi-year exposure.
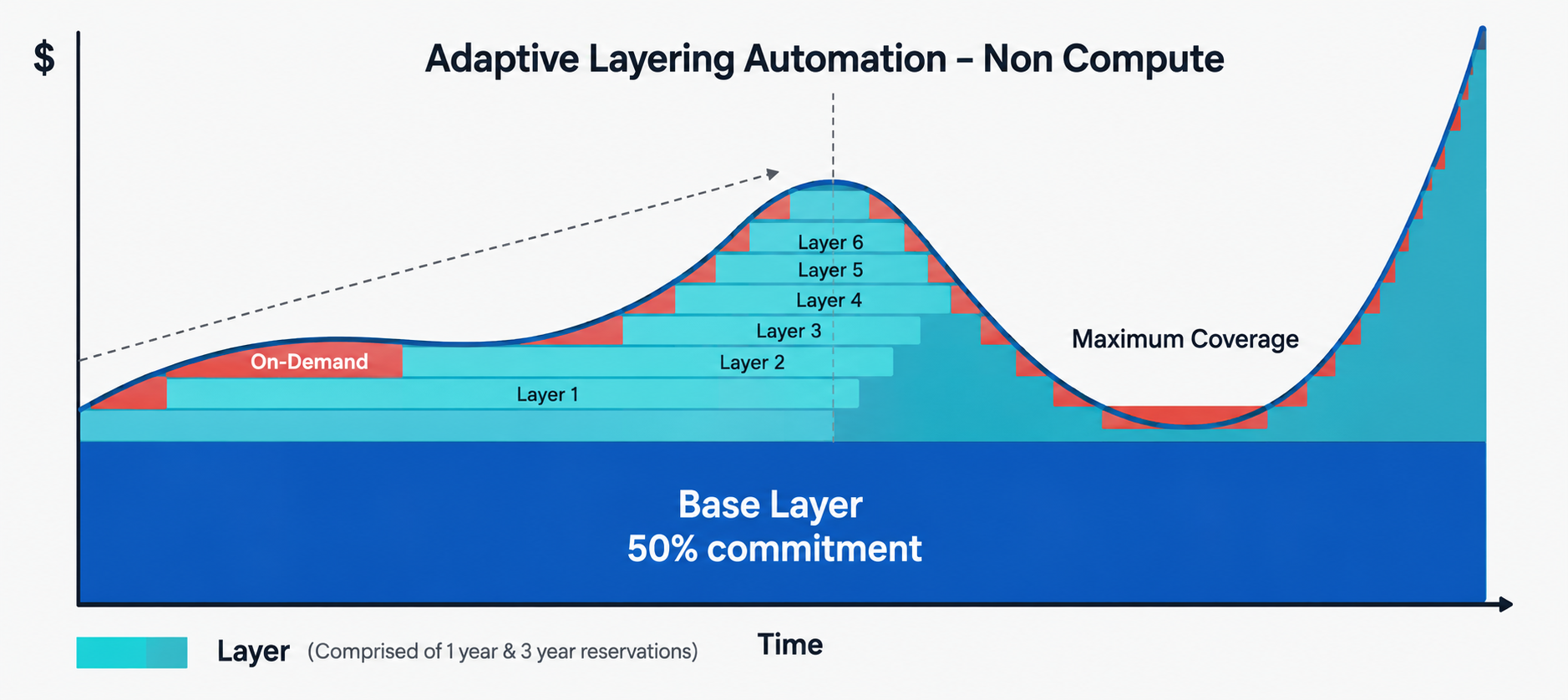
The metric that captures whether any of this is working is Effective Savings Rate (ESR): the real savings percentage across eligible spend, accounting for coverage, utilization, and discount depth together. nOps anonymized proprietary benchmark data puts the median organization around 18% ESR while top performers exceed 51%. The gap between those tiers has far less to do with how much you commit and far more to do with how closely your commitments track actual usage over time. For a workload as dynamic as DynamoDB, that tracking is the whole game.
What good DynamoDB commitment management looks like in 2026
Putting it together, the modern playbook for a serious DynamoDB estate looks like this:
- Separate the layers. Identify the genuinely steady baseline versus the variable top. They get different instruments.
- Reserve the floor. Put the predictable baseline in provisioned mode under Reserved Capacity, sized to the trough, not the peak, of that baseline.
- Cover the variable top with DSP. Apply Database Savings Plans to the on-demand layer, the Infrequent Access usage, and the Global Tables replicated writes that Reserved Capacity can't reach. This is the layer that had zero coverage before December 2025.
- Layer both, continuously. Don't size either layer once. Re-evaluate as the workload moves, repurchasing in small increments so coverage stays high and lock-in stays low.
- Never trade reliability for a savings slide. Don't push a spiky, latency-sensitive workload into provisioned mode just to capture a deeper headline discount. The right answer is to maximize savings within the reliability constraints your engineers have correctly set.
That last point matters more than any single percentage. The deepest discount in the world isn't worth throttling a production path during a traffic surge. Good commitment management meets your workload where it actually runs.
How nOps approaches DynamoDB commitments
This is precisely the problem nOps is built to solve. It selects the right instrument for each layer of spend, and manages them as a continuously rebalanced, layered portfolio that adapts as usage shifts.
- Coverage across both billing modes. nOps automatically manages commitments across DynamoDB provisioned and on-demand spend, applying Reserved Capacity where usage is genuinely steady and Database Savings Plans to variable, on-demand, and Global Tables replicated-write usage that Reserved Capacity can't cover.
- Continuous, layered rebalancing. Commitments are re-evaluated against real usage on an ongoing basis, keeping coverage high and lock-in low as tables, traffic, and regions change, instead of betting on a forecast that's stale the day you make it.
- Savings-first, fully aligned. nOps charges a percentage of the savings it generates. If we don’t save you money, you don’t pay.
Curious what your uncovered DynamoDB spend looks like? A 30-minute free savings analysis shows you your current Effective Savings Rate and where the opportunities are. Setup is 5 minutes with no agents or infra changes needed.
nOps manages $4 billion in cloud spend for its customers and is rated 5 stars on G2.