

What is AWS Batch
Learn what AWS batch is, how it works, when it's useful, and best practices.
What is Batch Computing?
Batch computing is the automated processing of large volumes of data or tasks in groups. Optimized for non time-sensitive jobs, it allows high computation workloads such as Machine Learning, AI, data processing, image or video processing, and financial modeling to run efficiently as background operations, maximizing resource utilization and throughput.
What is AWS Batch?
AWS Batch is a fully managed service that simplifies and automates batch computing workloads across EC2, Fargate, and other AWS cloud services. With AWS Batch, developers, scientists and engineers no longer have to install and manage batch computing software or server clusters used to run your jobs.
The two main functions of AWS batch are:
Job scheduler. Users can submit jobs to AWS Batch by specifying basic parameters such as GPU, CPU, and memory requirements. Batch queues job requests and manages the full lifecycle from pending to running, ensuring completion. If a job fails, Batch will automatically retry it — useful in the case of unexpected hardware failures or Spot instance terminations.
Resource orchestrator engine. Batch scales up compute resources when there are jobs in the queue and scales down once the queue is empty — so you only pay for the compute and storage you use.
How does it work?
Let’s break down how AWS Batch works and how to run Batch jobs.
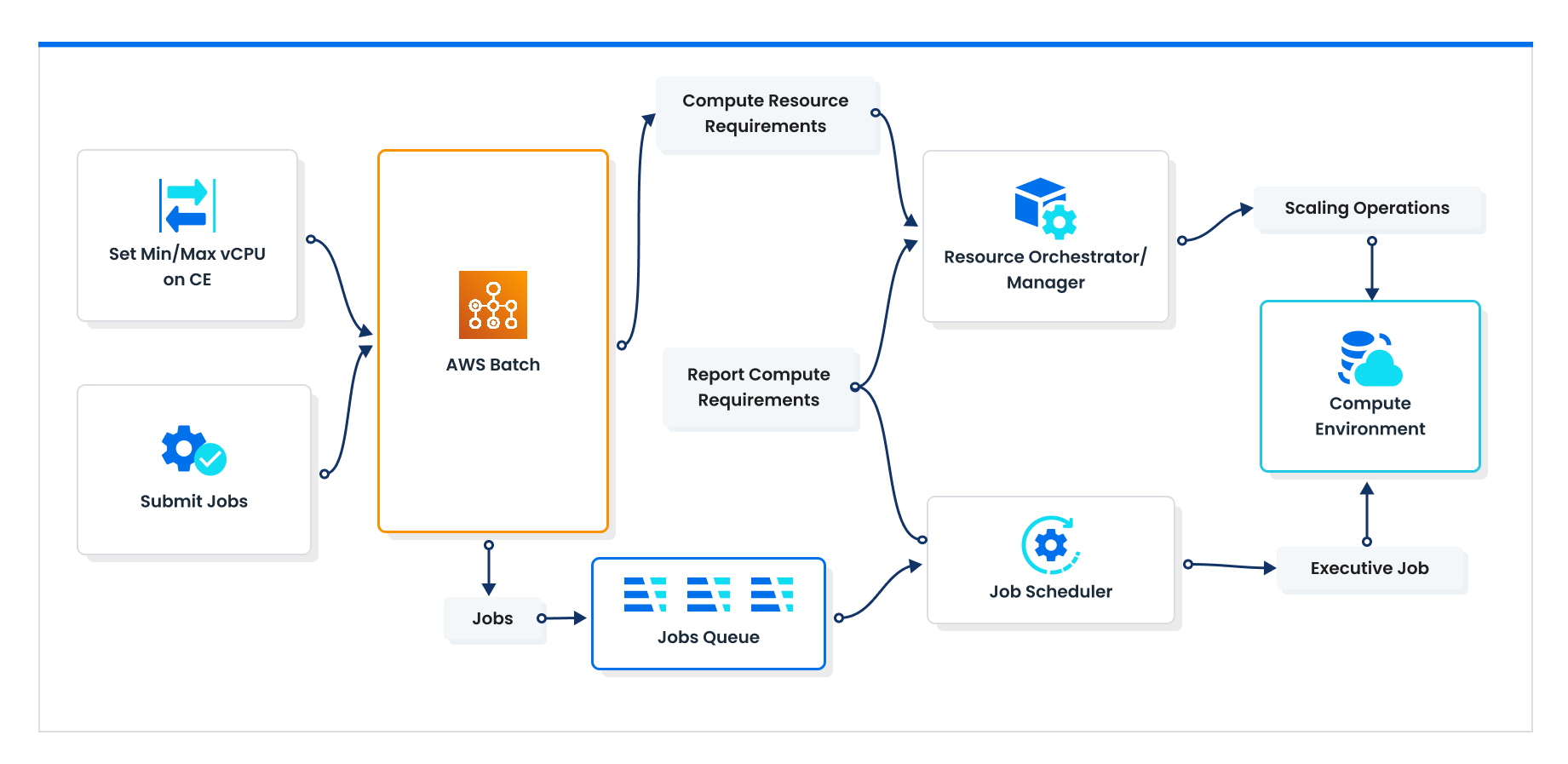
Initially, you set constraints on the capacity Batch is allowed to use, including defining job requirements like vCPU, memory, and instance type.
Jobs submitted to Batch are placed in a job queue.
The job scheduler periodically reviews the job queue, assessing the number of jobs and their requirements to determine necessary resources.
Based on this evaluation, the resource manager orchestrates the scaling of compute resources up or down as needed.
The resource manager reports back to the job scheduler, informing it of the available capacity. The schedule then begins assigning workloads to the compute environment, continuously running this process in a loop.
AWS Batch: important terms
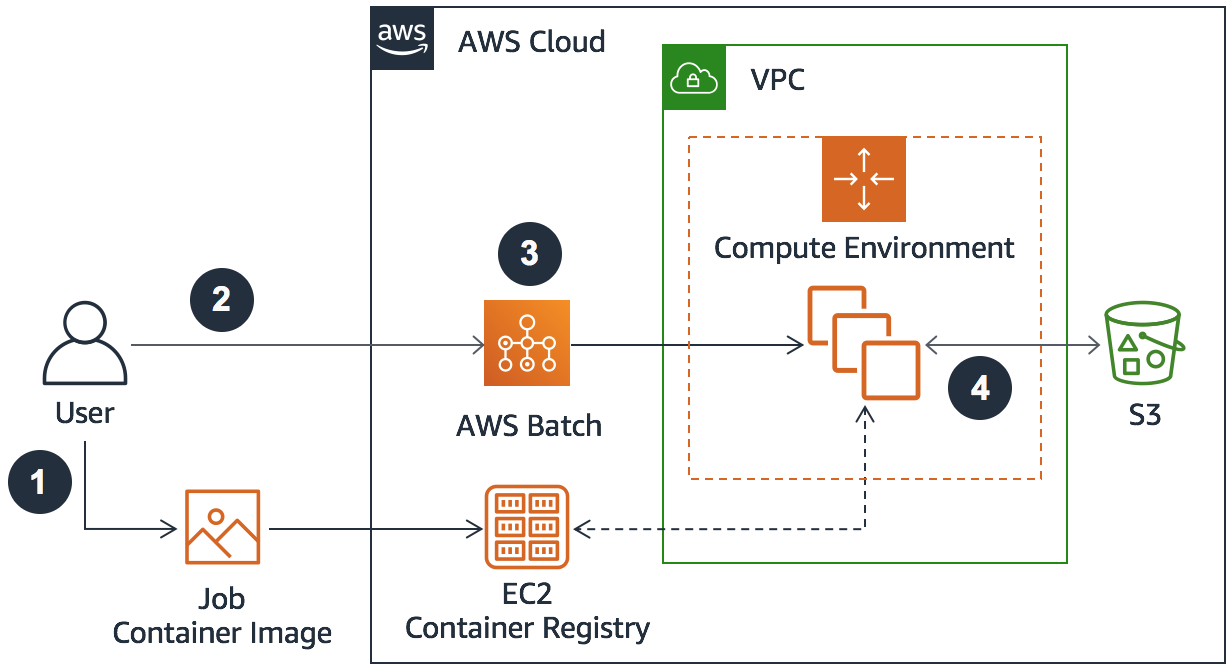
Job: A unit of work that you submit to AWS Batch.
Job Definition: Specifies how jobs are to be run. Job definitions include the Docker image, the command, the environment variables, memory, and vCPU requirements. Additional job definition settings can specify retry strategies for job failures and timeouts to control the duration of execution.
Job Queues: Act as a repository where jobs await allocation to a compute environment based on their priority and resource requirements. You can leverage multiple queues with different priority levels.
Compute Environment: The hardware that runs the AWS Batch jobs. You can configure compute environments with specific types of instances, desired and maximum vCPUs, instance roles, and other parameters.
Within a job queue, the associated compute environments each have an order used by the scheduler to determine where jobs that are ready to be run will run. If the first compute environment has a status of VALID and has available resources, the job is scheduled to a container instance within that compute environment. Otherwise the scheduler attempts to run the job on the next compute environment.
Job Scheduler: Responsible for prioritizing jobs in the queue and assigning them to compute resources. It optimizes the order to run jobs based on dependency rules and resource availability.
Resource Manager: Manages the allocation and deallocation of resources within the compute environment. It scales compute resources up or down based on the requirements and availability, ensuring that resources are optimally utilized.
AWS Batch Best Practices
Let's dive into some fundamental best practices for leveraging AWS Batch effectively. For additional information, you can consult the AWS Documentation or AWS Compute Blog
Understand what workloads are suitable for batch:
AWS Batch is best for workloads that are not time-sensitive and can handle some startup delay due to batch scheduling.
For extremely short-duration jobs, it's recommended to binpack multiple tasks into a single job so the jobs run 3-5 minutes each.
If tasks need to be run immediately (such as within a few seconds), Batch is probably not the right choice — consider other AWS services like ECS or EKS.
Identify potential issues early:
Before ramping up to large-scale processing, verify and adjust your Amazon EC2 and EBS quotas to handle your expected load. Start with a lower capacity, like 50,000 vCPUs, and scale up while monitoring for bottlenecks or performance issues using tools such as Amazon CloudWatch.
This stepwise approach will help you to understand system limits and plan capacity increases without disruptions.
Optimize containers and AMIs:
For effective batch processing, optimize your containers to be as lightweight as possible. Containers larger than 4GB should be structured carefully with evenly sized layers to enhance retrieval efficiency. Utilize Amazon ECR for reliable scaling in high-load environments. Offloading infrequently updated files to the AMI and using bind mounts can significantly reduce container sizes, leading to faster startup times and more efficient batch job execution.
Know when to use Fargate vs ECS vs EKS
You should use AWS Fargate for running your AWS Batch jobs when you want the provisioning of compute resources to be completely abstracted from the underlying ECS infrastructure. This is ideal for situations where you don't require specific instance configurations or large-scale resource deployments.
On the other hand, if your workloads need specific processor types, GPUs, or other particular configurations, or if they are extremely large in scale, running your jobs on ECS would be more suitable. Additionally, for environments standardized on Kubernetes, integrating AWS Batch with EKS can help streamline your batch workloads.
In terms of performance, Fargate typically allows faster initial job starts during scale-out since it eliminates the need to wait for EC2 instances or Kubernetes pods to launch. However, for larger and more frequent workloads, ECS or EKS might offer faster processing times because AWS Batch can reuse existing instances and container images to execute subsequent jobs.
Know when to use Fargate vs EC2:
Choose AWS Fargate for jobs that need to start quickly (under 30 seconds) and fit within the resource limitations of 16 vCPUs and 120 GiB of memory. Fargate simplifies operations by removing the need to manage servers and perform capacity planning.
For jobs that require specific instance types, higher throughput, custom AMIs, or more extensive resources like GPUs, opt for Amazon EC2 within AWS Batch for greater control and customization.
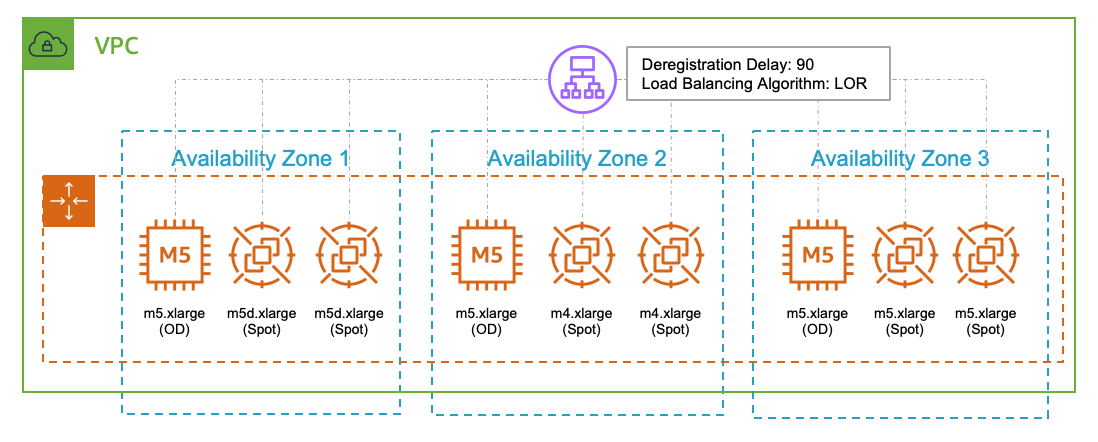
Leverage Spot instances for cost savings:
AWS Batch is ideally suited for EC2 Spot Instances due to batch jobs' ability to handle interruptions by resuming or restarting without loss, which complements Spot's cost-effective, interruption-prone nature. The flexibility of batch tasks with non-urgent completion times maximizes the financial benefits of Spot Instances, which offer significant cost savings compared to On-Demand rates.
For maximum savings on Spot, you can plug in nOps Compute Copilot to your AWS Batch. It's fully aware of your commitments and makes it easy to save with no upfront costs.
AWS Batch Frequently Asked Questions
Running your first job? Here are some frequently asked questions for getting started.
What are the benefits of using batch computing with AWS Batch?
Batch computing enhances operational efficiency by allowing the scheduling of job processing during less expensive or more available capacity periods. This approach minimizes idle compute resources by automating job scheduling and execution, thus driving higher resource utilization.
Additionally, AWS Batch supports job prioritization, aligning resource allocation with business objectives to effectively manage workload demands.
Why aren't my AWS Batch jobs going anywhere?
Even if job submission is successful, it will take some time to scale up. The Job Scheduler ensures scaling only to the capacity it can manage in that time frame, and no more than that.
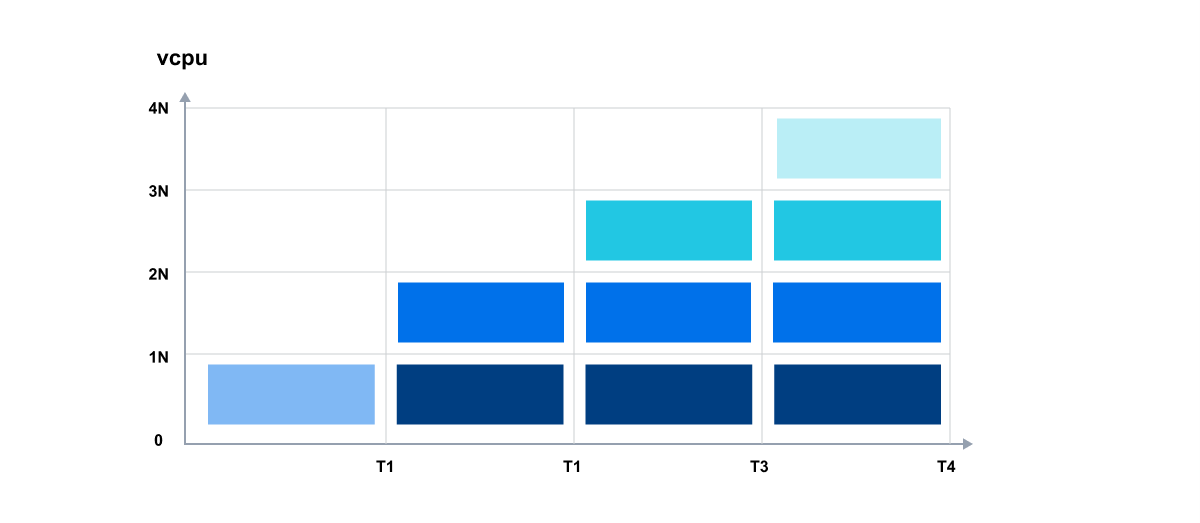
What happens if I submit a new Job while there’s a scaling event already happening?
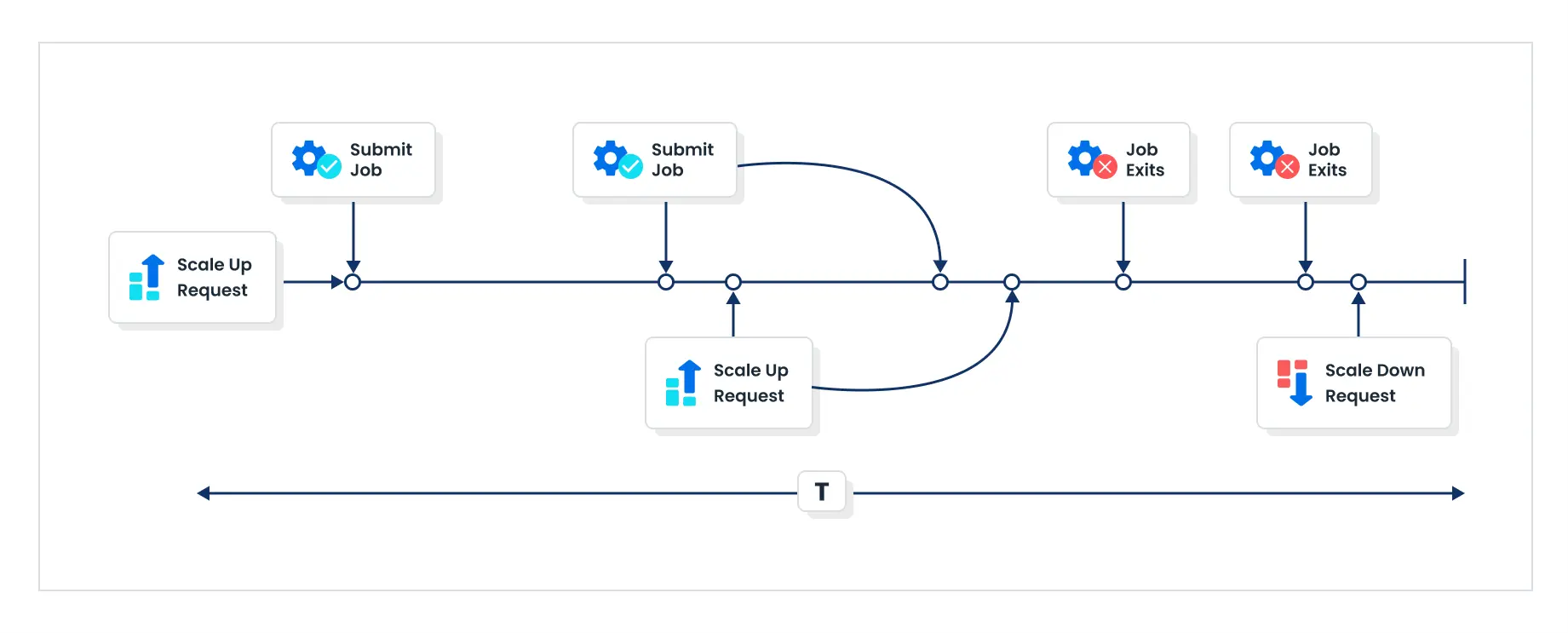
When a job is submitted in Batch and triggers a scale-up request, the system responds by increasing capacity. If another job is submitted during the same time period, AWS Batch can handle an additional scale-up request even within the ongoing interval.
What is the pricing for AWS Batch?
There is no additional charge for using AWS Batch. You do pay for the AWS Resources that you create to store and run your batch jobs.
This means that your pricing will depend on the specifics of the compute resources you choose, including whether you use On-Demand Instances, Reserved Instances, Spot Instances, or AWS Fargate.
Optimize AWS Batch workloads with nOps
Are you already running on AWS Batch and looking to automate your workloads at the lowest costs and highest reliability?
nOps Compute Copilot helps companies automatically optimize any compute-based workload. It intelligently provisions all of your compute, integrating with your AWS-native Batch, EKS, ECS or ASGs to automatically select the best blend of SP, RI and Spot.
Save effortlessly with Spot: Engineered to consider the most diverse variety of instance families suited to your workload, Copilot continually moves your workloads onto the safest, most cost-effective instances available for easy and reliable Spot savings.
100% Commitment Utilization Guarantee: Compute Copilot works across your AWS infrastructure to fully utilize all of your commitments, and we provide credits for any unused commitments.
Our mission is to make it faster and easier for engineers to optimize, so they can focus on building and innovating.
nOps manages over $1.5 billion in AWS spend and was recently ranked #1 in G2’s cloud cost management category. Book a demo to find out how to save in just 10 minutes.