Skip to content
Skip to content


- Blog
- EKS Optimization
- Cluster Autoscaler Vs Karpenter: The Essential Guide
Cluster Autoscaler Vs Karpenter: The Essential Guide
When it comes to resource management and autoscaling in Kubernetes, you have two main options: Cluster Autoscaler or Karpenter.
Cluster Autoscaler is the most widely used autoscaler, whereas Karpenter has emerged as a powerful alternative offering many advantages over the traditional solution.
This article will explore the primary differences between Karpenter and Cluster Autoscaler, the advantage and disadvantages of each, and which solution is right for your EKS workloads.
What is Cluster Auto Scaler and how does it work?
Cluster Autoscaler (CAS) automatically scales your Kubernetes clusters based on the custom metrics you define. It monitors the resource utilization of nodes in your Kubernetes/EKS Cluster, and scales up or scales down the number of nodes in a node group accordingly leveraging Amazon Auto Scaling Groups (ASGs).
Cluster Autoscaler evaluates both node usage and factors like pod priority and PodDisruptionBudgets to determine whether to add nodes.
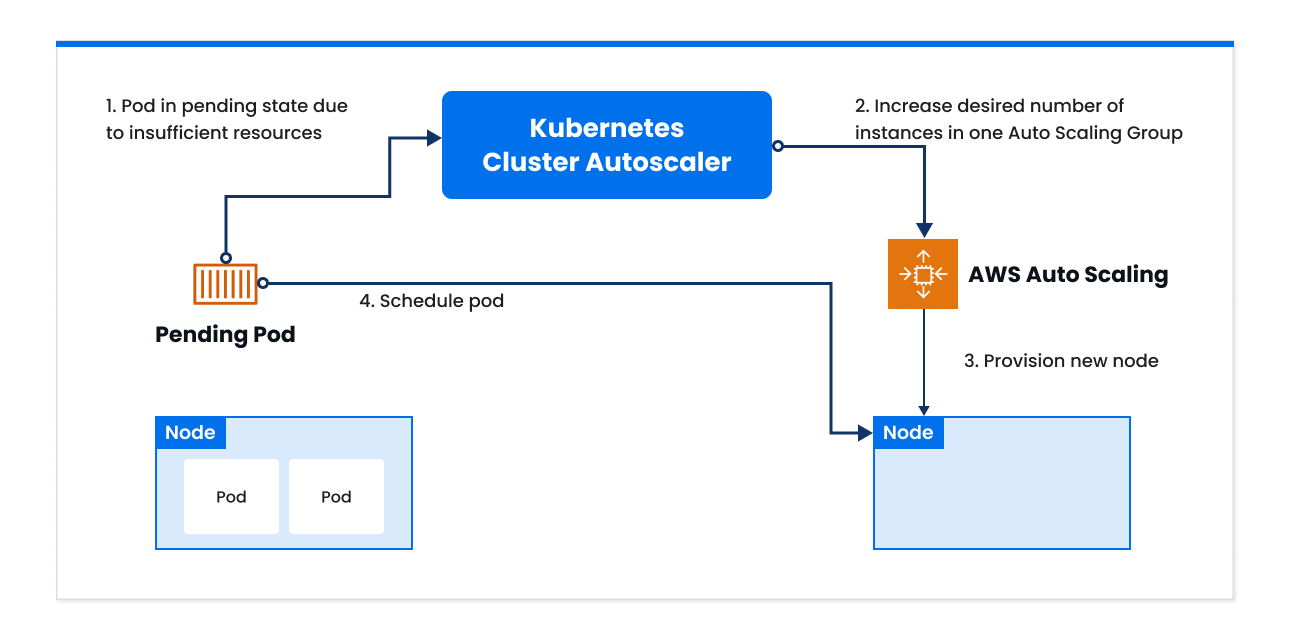
Cluster Autoscaler (CAS) was revolutionary when it was released in 2017. Before Cluster Autoscaler, there was no automated way to manage scaling. We had to manually spin up a machine, install the Kubernetes framework, and attach it manually via the CLI or Kubernetes dashboard — and it wasn’t too long ago that this was the standard process.
Some key benefits of Cluster Autoscaler include:
- Automatic Scaling
- Cost Efficiency
- Improved Resource Utilization
- Supports Multiple Cloud Providers
- Flexible Configuration
What is Karpenter and how does it work?
Karpenter is an open source, flexible, high-performance EKS cluster autoscaler developed by AWS in 2021.
This advanced node scheduling and scaling technology enhances pod placement for optimal resource utilization, proactively and dynamically provisioning nodes in anticipation of actual workload needs. This helps you avoid overprovisioning, waste, and unnecessary costs.
Karpenter addresses pre-defined node group constraints, enabling more fine-grained control over resource utilization. Unlike Cluster Autoscaler which works with Auto Scaling Groups, Karpenter works directly with EC2 instances. It employs application-aware scheduling, considering pod-specific requirements like taints, tolerations, and node affinity for additional customization and flexibility. This helps you customize scaling behaviors based on your specific needs for better performance and availability.
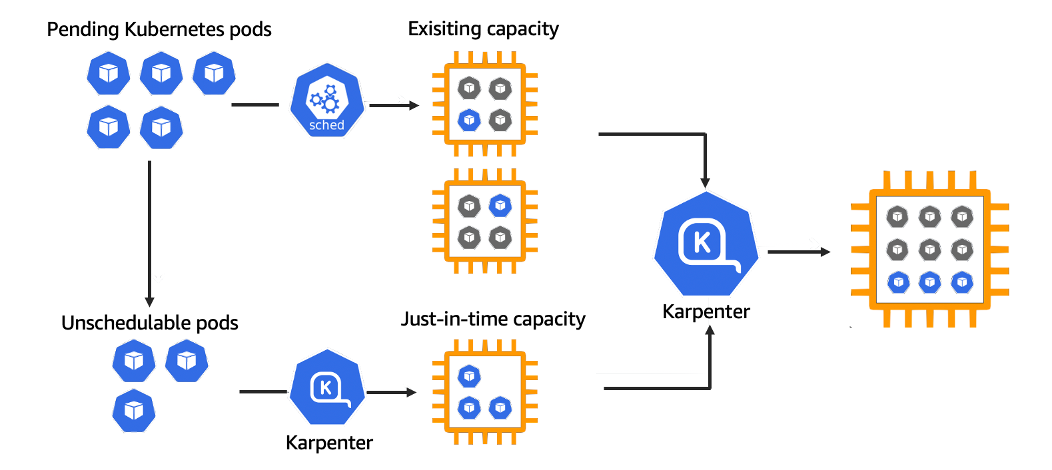
What’s better: Karpenter or Cluster Autoscaler
Karpenter is a significant advancement over Cluster Autoscaler. Cluster Autoscaler is more complex and time-consuming to configure, it scales less efficiently and proactively, and it is limited in features compared to Karpenter.
Before the introduction of Karpenter, Kubernetes users had to adjust cluster computing capacity, either through Kubernetes Cluster Autoscaler (CAS) or Amazon EC2 Auto Scaling Groups to prevent wasted node capacity. But Cluster Autoscaler doesn’t make scaling decisions, it simply spins up a new node of a predetermined size if the CPU and memory of the pending pod will not fit on the current nodes. This means if the nodes are oversized, a lot of money can be wasted from underutilized infrastructure — or if too small of a node is chosen, costs increase due to overhead.
With the help of Karpenter, it becomes possible to combine all the resource requests for unscheduled pods and automate decision-making for provisioning nodes and terminating existing nodes. This, in turn, leads to decreased infrastructure costs and scheduling latencies.
Karpenter also has a high-level API that allows users to manage the low-level details of scaling resources according to the current demand. The most significant benefit of Karpenter is that it can ensure that applications always have the resources they might need to handle traffic peaks, all the while decreasing costs using a strategy of launching right-size nodes and culling unused resources.

The limitations of Cluster Autoscaler
If you have the following challenges with EKS Cluster Autoscaler, you might want to consider Karpenter:
1. Resource underutilization driving up EKS bills
In case there is not enough load generated in the Kubernetes workload, the Cluster Autoscaler may not even get triggered to add new nodes to the cluster – which can in turn lead to underutilization of cluster node resources. In most situations, all the memory of the nodes and CPU cores are also not used to their full capacity, which also causes underutilization.
2. Too much manual overhead
With Cluster Autoscaler, creating node groups, managing node groups, and managing EKS clusters requires a lot of manual effort. When deployments need specific CPU architecture or different CPU- based instance types, new node groups have to be manually created when deployed.
Karpenter is much more efficient at scaling and makes it easy to quickly take action to adjust resources and continuously improve optimization. Engineering teams can spend much less time finding appropriate instances of resolving scaling issues.
3. Difficult to use with EC2 Spot instances
Spot instances offer up to 90% discounts, but finding the right balance between price and reliability can be a nightmare with Cluster Autoscaler. In contrast, Karpenter is natively integrated with Spot, automatically selects the right instance types, provisions faster and more effectively, and adjusts capacity based on real-time workload requirements, minimizing the risk of interruption while maximizing cost efficiency. It can also incorporate intelligent fallback strategies, launching On-Demand instances when Spot availability is low, ensuring continuous application uptime.
4. Performance bottlenecks and downtime
In case an error occurs when creating a node in a node group, Cluster Autoscaler would not find out about it until the timeout. This can cause an invariable delay in scaling out, resulting in performance bottlenecks and impact on application responsiveness, especially during high-demand periods when timely scaling is critical. Karpenter, on the other hand, immediately detects node creation failures and reattempts provisioning in real-time.
The limitations of Karpenter
While Karpenter is a huge upgrade from Cluster Autoscaler, particularly with the recent graduation to 1.0, it still has the following limitations:
1. Lack of Commitment Awareness
Karpenter does not account for existing Reserved Instances (RIs) or Savings Plans. This can lead to inefficient usage and wasted prepaid capacity, especially if it aggressively provisions Spot or On-Demand instances that bypass your existing commitments.
2. Limited Multi-AZ and Multi-Arch Awareness
While Karpenter supports provisioning across Availability Zones and CPU architectures, it doesn’t actively optimize for diversification or resilience strategies (e.g., spreading workloads to mitigate Spot interruption risks or balancing across AZs for HA).
3. No Native Rightsizing
Karpenter provisions instances based on current workload requirements but doesn’t continuously re-evaluate or rightsizing already-running pods or nodes. You’ll need to combine it with another tool (like VPA or external rightsizers) for full optimization.
4. Spot Best Practices Are Not Automated
Karpenter doesn’t orchestrate diversification or interruption rate awareness for Spot Instances out of the box. If you want to avoid large-scale Spot interruptions, you’ll need to implement custom logic or use another tool.
5. Lack of Visibility
Karpenter doesn’t include visibility tools. Without insight into termination rates or node performance, you don’t know how well you’re running and how much you’re saving compared to before.
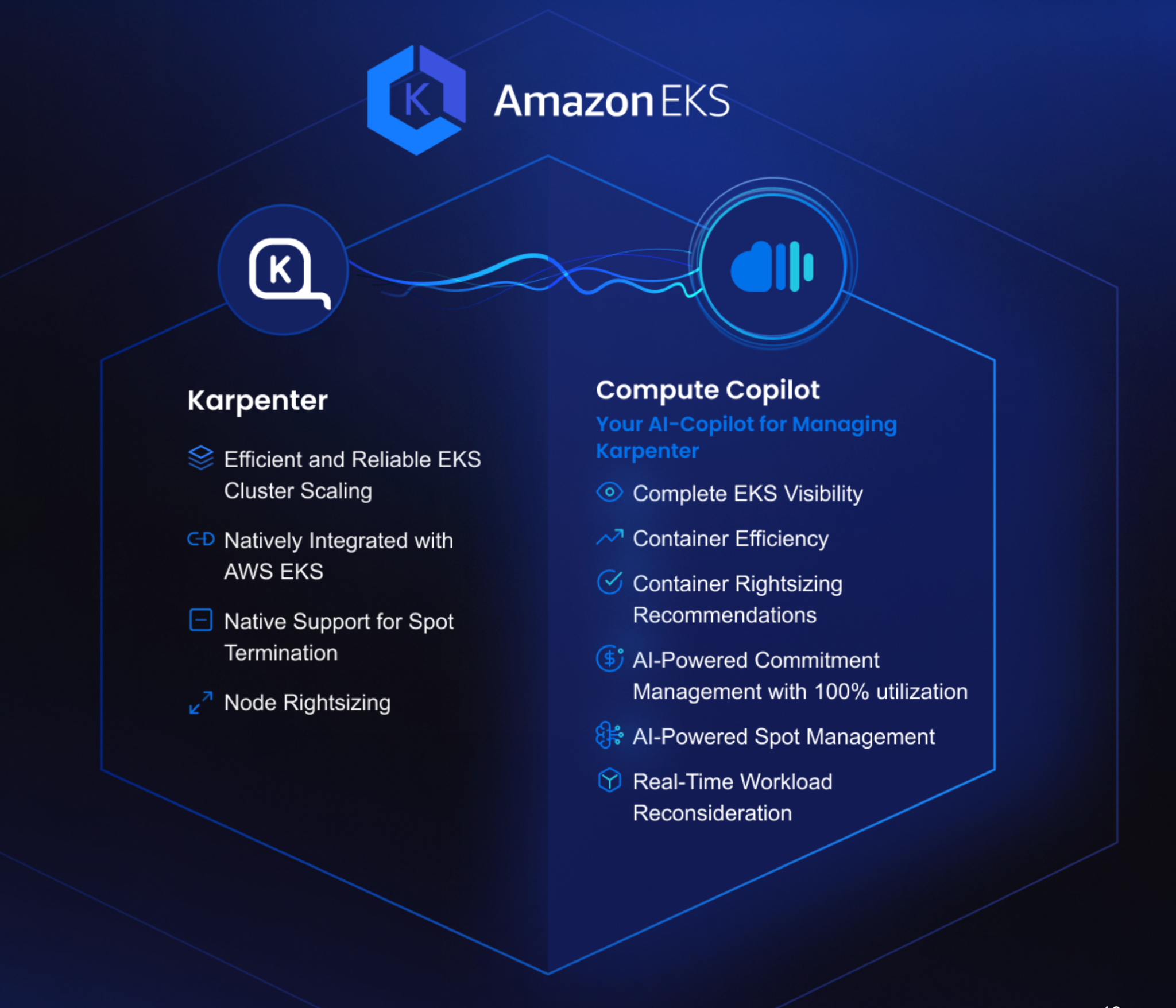
To solve all of these limitations, nOps built a solution to help you get the most out of Karpenter.
Key Differences Between Cluster Autoscaler vs Karpenter
| Karpenter | Cluster Autoscaler | |
| Resource Management | Karpenter is proactive and cost-efficient. Based on the resource requirements of Kubernetes workloads, it can provision capacity directly, i.e. automatically provision instances that match the actual resource requirements of a pending workload. This helps ensures there is no overprovisioning or under provisioning of resources. | Based on the resource utilization of existing nodes, Cluster Autoscaler takes a reactive approach to scale nodes. It adjusts the number of nodes in a cluster based on the resource requirements of the Kubernetes workloads. |
| Node Management | Karpenter scales, provisions, and manages nodes based on the configuration of provisioners. Karpenter reviews the resource requirements of all the unscheduled pods and then selects the instance type which fulfills the resource requirements. | Cluster Autoscaler manages nodes based on the resource demands of the present workload. It does not select specific instance types based on pod resource requests. Instead, it works with predefined node groups and scales the number of nodes within those groups. |
| Node removal | Karpenter provides fine-grained control over node termination through its Time-To-Live (TTL) settings. This is useful when you need to manage node lifecycles based on factors such as cost considerations, usage patterns, maintenance, etc. | Cluster Autoscaler adjusts node counts within predefined groups based on workload demands, focusing on scaling nodes up or down without fine-grained controls. |
| Autoscaling | Karpenter offers more effective and granular scaling functionalities based on specific workload requirements, monitoring resource utilization and dynamically scaling according to actual usage. | Cluster Autoscaler is more focused on node-level scaling, and as a result it scales less quickly and effectively. |
| Scheduling | Karpenter supports advanced scheduling and affinity rules to help you better manage workload placement and resource allocation in your cluster. If you have specific requirements for workload distribution or need to enforce strict resource constraints, Karpenter provides the flexibility you need. | With Cluster Autoscaler, scheduling is more simple as it is designed to scale up or down based on the present requirements of the workload. It doesn’t schedule workloads based on AZs, resource requirements, costs, etc. |
| Spot | Karpenter can automatically provision a mix of On-Demand and Spot instances, dynamically choosing the most cost-effective options that meet your workloads’ resource demands. | Cluster Autoscaler does not directly manage Spot instances or automatically optimize costs based on instance type selection. |
Why we love Karpenter
| Efficient and Reliable EKS Cluster Scaling | Simplified EKS Management | Open Source and multi-cloud supported by CNCF & AWS |
| Extensible Configurations Define classes of nodes and associate pools for control over which types of instance resources are being used for each of your applications. Resource requests Never let your cluster run low on CPU or memory capacity by ensuring safe thresholds for your cluster by configuration Topology Spread & Pod affinity/anti-affinity Ensure your cluster does not have down time based on the loss of a node or availability zone Resource Weighting Ensure the most efficient resources for your configuration are used more frequently for scaling your cluster | Simple Helm Chart Upgrades Apply a new helm chart to upgrade your version of Karpenter ensuring simple, version-controlled improvements Configured in one service Control your node configuration with one configuration rather than using multiple proprietary services for scaling and configuration | CNCF Open Source Project Accepted by the CNCF community as a supported project within the Kubernetes ecosystem ensuring high quality and innovation Multi-cloud Supported Karpenter has expanded to allow its use across additional clouds such as Azure while becoming more platform agnostic AWS Certified Originally developed by AWS, Karpenter is supported both by the general open source community and dedicated AWS resources |
How to migrate to Karpenter
Migrating to Karpenter is easy, and takes only 20 minutes on average. You simply install Karpenter on your cluster, configure a few provisioning specifications based on your needs, and it seamlessly takes over the node provisioning process. This means there’s minimal disruption to your existing operations.
For detailed instructions, check out our complete ebook guide to migrating to Karpenter.
Let nOps Copilot manage Karpenter for you
How nOps Enhances Karpenter
nOps Compute Copilot is your AI-powered copilot for managing Karpenter. It gives you unparalleled visibility into EKS efficiency and automatically optimizes your Karpenter, delivering the most reliable, efficient, and cost-effective EKS autoscaling possible.
- AI-Powered and Continuous Cost Savings: nOps Copilot is aware of all your commitments and the Spot market, so you get the optimal blend of discounts with maximum stability and reliability.
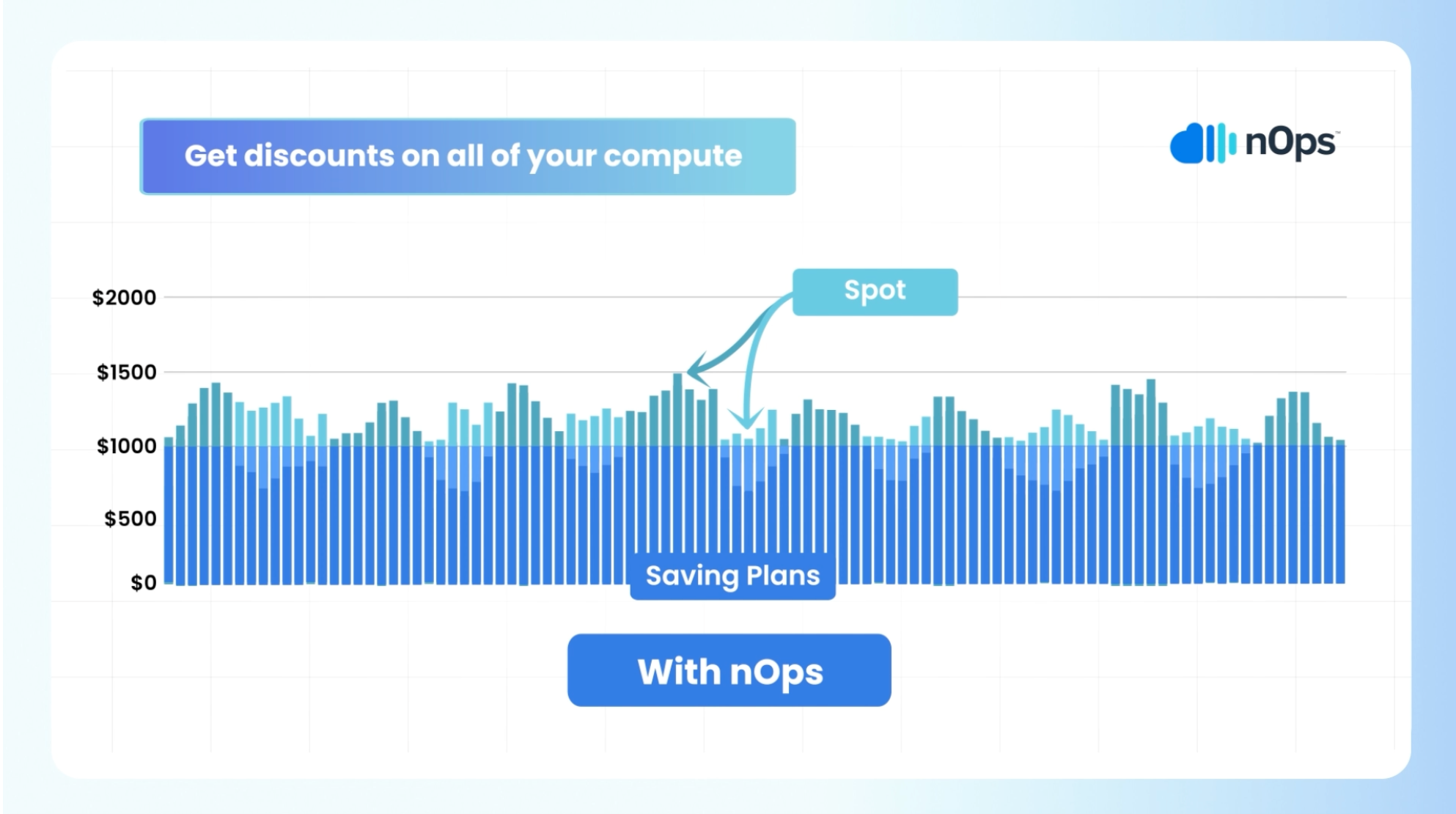
- Effortless Scalability, Efficiency, and Reliability: Compute Copilot adds AI-powered intelligence to Karpenter so your teams don’t need to worry about managing Karpenter and can focus on building and innovating.
- nOps is Invested in Karpenter’s Success: nOps has been optimizing and working with the Karpenter community since early beta versions and will continue to support the latest updates as they are released.
To maximize EKS cost and performance, automation is key. nOps helps engineering teams to more easily and effectively leverage the power of Karpenter, Spot and AWS commitments for cost savings and reliability, freeing them to focus on building and innovating.
New to Karpenter? No problem! The Karpenter experts at nOps will help you navigate Karpenter migration. We also support multiple autoscaling technologies like Cluster Autoscaler and ASGs.
nOps was recently ranked #1 in G2’s cloud cost management category and we are an official AWS Spot-ready partner. Book a demo to find out how to save in just 10 minutes!
Frequently Asked Questions
Let’s dive into a few commonly asked questions about Karpenter, Kubernetes and Spot.
Does Karpenter use autoscaling groups?
No. Karpenter bypasses traditional Auto Scaling Groups by provisioning EC2 instances directly via the EC2 Fleet API. This gives it full control over instance types, capacity, and pricing in real time, enabling faster and more flexible scaling without being bound to predefined ASG configurations.
Is Karpenter faster than Cluster Autoscaler?
Yes. Karpenter can launch new instances in seconds by reacting to pending pods immediately, while Kubernetes Cluster Autoscaler checks periodically and only adds nodes from fixed node groups. Karpenter’s direct EC2 API integration and dynamic provisioning result in significantly lower provisioning latency.
What are the alternatives to Cluster Autoscaler?
Alternatives include Karpenter (for dynamic provisioning), AWS Fargate (for serverless pods), and commercial tools like Ocean by Spot or CAST AI. Karpenter and Karpenter alternatives offer different trade-offs in provisioning speed, cost optimization, and management complexity beyond the node group-based approach of Cluster Autoscaler EKS.
What is the difference between EKS auto and Karpenter?
EKS Managed Node Groups (EKS Auto) use Auto Scaling Groups with fixed instance types and scaling logic. Karpenter provisions nodes on-demand using custom scheduling logic, selecting the best instance type and price based on real-time requirements. This allows more granular scaling decisions and faster response to changing workload demands.
Last Updated: April 28, 2026, EKS Optimization
Last Updated: April 28, 2026, EKS Optimization