 Skip to content
Skip to content


- Blog
- EKS Optimization
- How We Made Spark on Kubernetes Cheaper (and Safer to Run)
How We Made Spark on Kubernetes Cheaper (and Safer to Run)
Introducing Spark Container Rightsizing in nOps
If you run Apache Spark on Kubernetes, you’ve probably lived this cycle: jobs fluctuate wildly, data skew melts a few hot executors, and the only sure-fire way to hit SLAs is to crank up requests “just in case.” For many teams, that means hundreds of GBs per container — massive waste when the average executor barely touches those peaks. And in Kubernetes, the blast radius is bigger than one job: overprovisioned requests degrade bin-packing cluster-wide and push up your EKS bill.
Today we’re launching Spark application rightsizing in nOps Container Rightsizing (powered by our ML recommendations engine + a customized Vertical Pod Autoscaler). It rightsizes Spark driver and executor pods at startup, lines up Spark runtime knobs with container resources, and never disrupts running jobs.
The target audience is platform engineers and DevOps leaders who use the Spark Operator and want real cloud savings without risky mid-run flips.
What you’ll learn in this post
- Why manual rightsizing fails for Spark-on-K8s (and costs real money)
- What we changed in our VPA to make Spark rightsizing safe
- Exactly how it works, with YAMLs, a flow, and code excerpts
- Limitations, best practices, and what’s next for Compute Copilot
The Problem: Why manually rightsizing Spark on K8s is hard (and expensive)
Spark workloads aren’t static. Input volumes change daily; joins and aggregations can suddenly create data skew, where a handful of tasks run orders of magnitude longer. That skew drives OOMs, spill, and unpredictable tails — so teams hedge with oversized executors and drivers. (Databricks Documentation)
Heaps and overheads are tricky. Spark memory isn’t just “executor memory.” Containers need heap + overhead (off-heap, PySpark memory, and more), so naïve request math underestimates real needs. To be safe, teams over-allocate — leading to even more cost.
Kubernetes punishes guesswork. Requests drive scheduling and bin-packing. Oversized requests inflate nodes and waste money; undersized requests risk throttling and crashes during Java warm-up spikes. Across dozens of pipelines, manual tuning doesn’t scale.
Spark-on-K8s architecture magnifies every sizing discrepancy. A driver pod spawns executor pods; each executor’s requests affect cluster packing. Wrong by 2–3X on executors? Your node fleet feels it.
The nOps Approach: Startup-only, Spark-aware rightsizing
nOps Compute Copilot extends our VPA fork to rightsize Spark at pod creation — never mid-run — so jobs stay stable while you save.
What's New
Spark-aware detection & targeting
We recognize SparkApplication resources (sparkoperator.k8s.io/v1beta2) and match the driver and executor pods created by the Spark Operator using its conventions (including the app-name label). This ensures we rightsize the right containers at the right time.Update policy: Initial for safety
Spark VPAs render with updateMode: Initial, so recommendations apply only at pod admission — no evictions, no surprise restarts in the middle of a stage.Executor env alignment
In addition to setting CPU/memory requests & limits, we inject executor container env vars that your images or spark-env.sh can consume to align Spark runtime parameters with the container:SPARK_EXECUTOR_CORES = ceil(recommended cores, min 1)
SPARK_EXECUTOR_MEMORY = recommended memory in MB with a small JVM headroom for small heaps. This keeps runtime parallelism and memory plans consistent with what Kubernetes actually grants. (Spark supports config via files/env through SPARK_CONF_DIR and spark-defaults.conf.)
How It Works
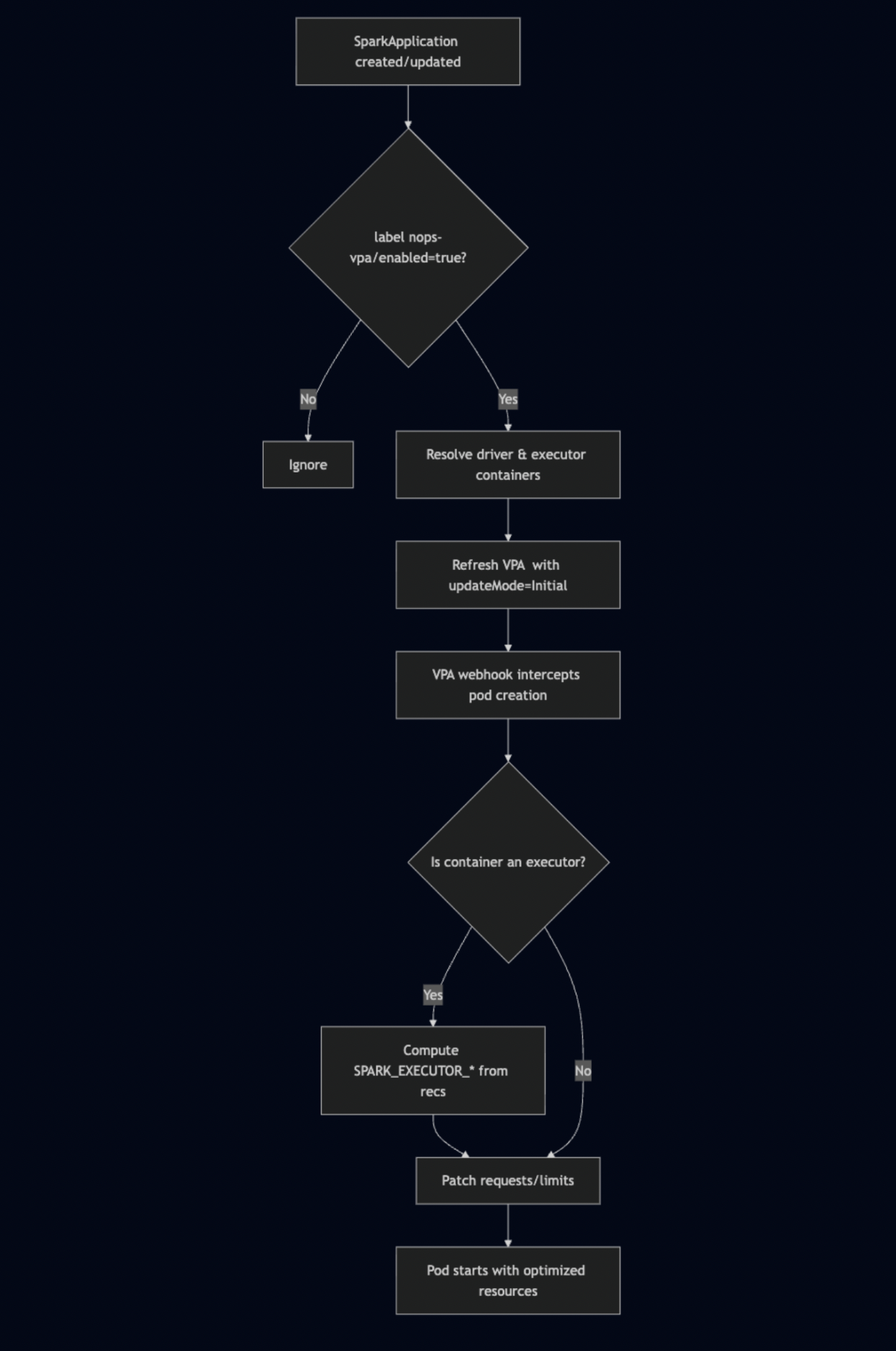
Under the hood, the VPA admission webhook mutates pods at creation time using current recommendations – exactly when Spark’s driver/executor pods are born via the operator. No mid-flight changes, no evictions.
You can check out the full documentation here.
Configure it in two ways
1) “Basic” SparkApplication
apiVersion: sparkoperator.k8s.io/v1beta2 kind: SparkApplication metadata: name: my-spark-job namespace: spark-apps labels: nops-vpa/enabled: "true" annotations: nops-vpa/policy: "Dynamic" # Dynamic | Maximum savings | High Availability spec: type: Scala mode: cluster image: "spark:3.4.0" # ... driver/executor sections as usual ... - nOps generates a VPA for this app set to Initial.
- At admission, the webhook applies CPU/memory recommendations; executors also get SPARK_EXECUTOR_* envs for alignment.
2) Advanced: per-container policies & sidecar control
apiVersion: sparkoperator.k8s.io/v1beta2 kind: SparkApplication metadata: name: complex-spark-job namespace: spark-apps labels: nops-vpa/enabled: "true" annotations: nops-vpa/policy.spark-kubernetes-driver: "High Availability" nops-vpa/policy.spark-kubernetes-executor: "Maximum savings" nops-vpa/container.monitoring-sidecar: "disabled" spec: type: Scala mode: cluster image: "spark:3.4.0" driver: sidecars: - name: monitoring-sidecar image: "prometheus/node-exporter" executor: sidecars: - name: logging-agent image: "fluent/fluent-bit" - Drivers and executors can follow different policies.
- Sidecars can be opted out of rightsizing with annotations.
- Selection relies on widely used Spark Operator patterns, keeping your config idiomatic.
Validation: Both “hello world” and nuanced cases are covered, mapped to operator semantics.
What’s inside: implementation highlights
Spark-aware env math (executors)
// Pseudocode of the executor env calculation cores := ceil(cpuRecommendationCores) if cores < 1 { cores = 1 } memMB := bytesToMB(memoryRecommendation) if memMB <= 2048 { memMB -= 300 } // JVM headroom for small heaps if memMB < 512 { memMB = 512 } env["SPARK_EXECUTOR_CORES"] = fmt.Sprintf("%d", cores) env["SPARK_EXECUTOR_MEMORY"] = fmt.Sprintf("%dm", memMB) Why the headroom? Spark container memory = heap + overhead (off-heap, PySpark, etc.). A small buffer in small heaps reduces GC/overhead pressure while keeping requests tight.
Startup-only VPA
spec: updatePolicy: updateMode: "Initial" This guarantees no mid-run restarts caused by rightsizing, aligning with Spark’s operational reality, where executors must remain stable throughout stages.
Why this improves upon manual rightsizing
- Fewer “just-in-case” buffers: We size to observed behavior rather than worst-case guesswork.
- Predictable stability: Initial-only updates eliminate surprise evictions that could topple long stages.
- Cluster-wide savings: Right requests → denser bin-packing → smaller node footprint over time
- Less toil: No more per-job trial-and-error across a sprawl of pipelines.
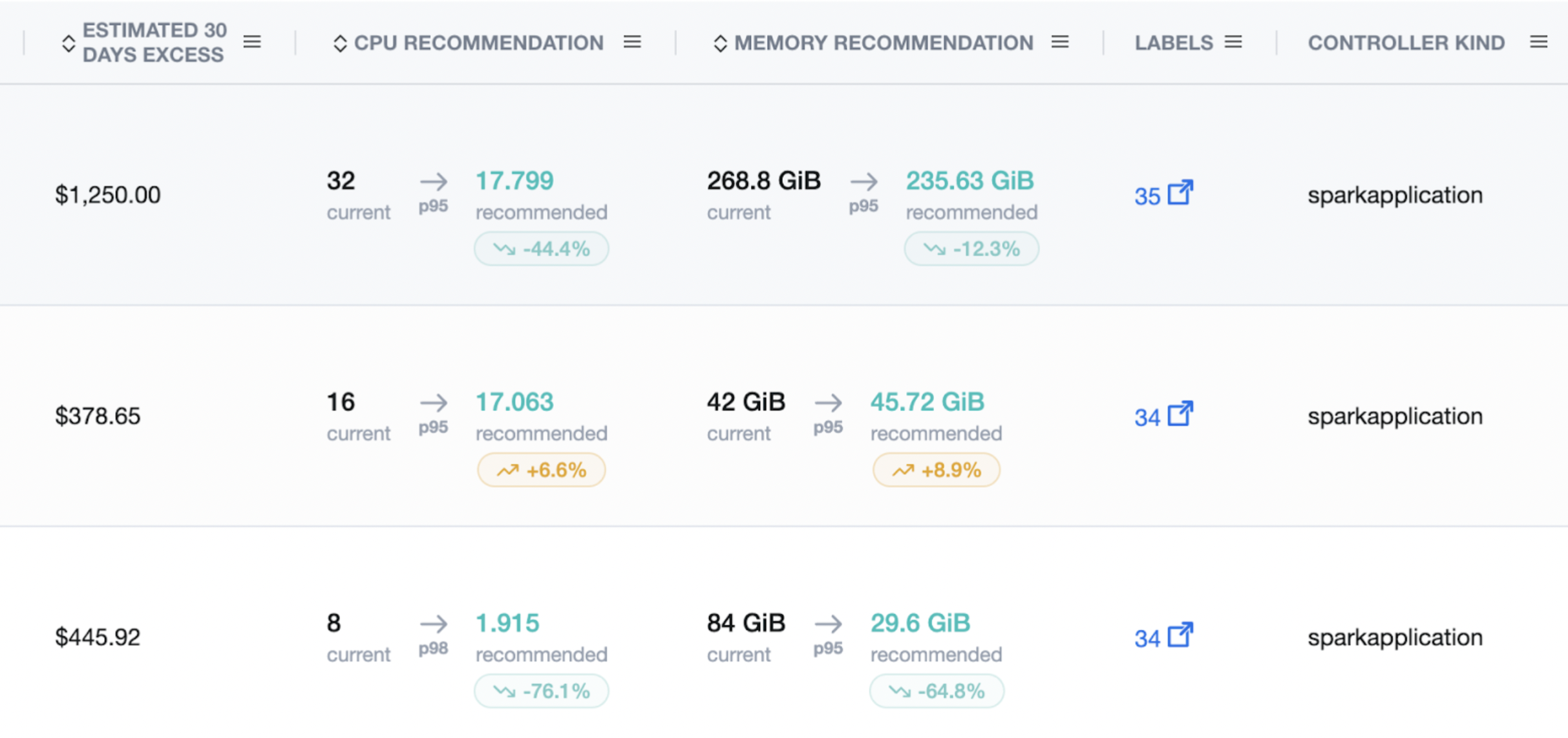
Example: What alignment looks like
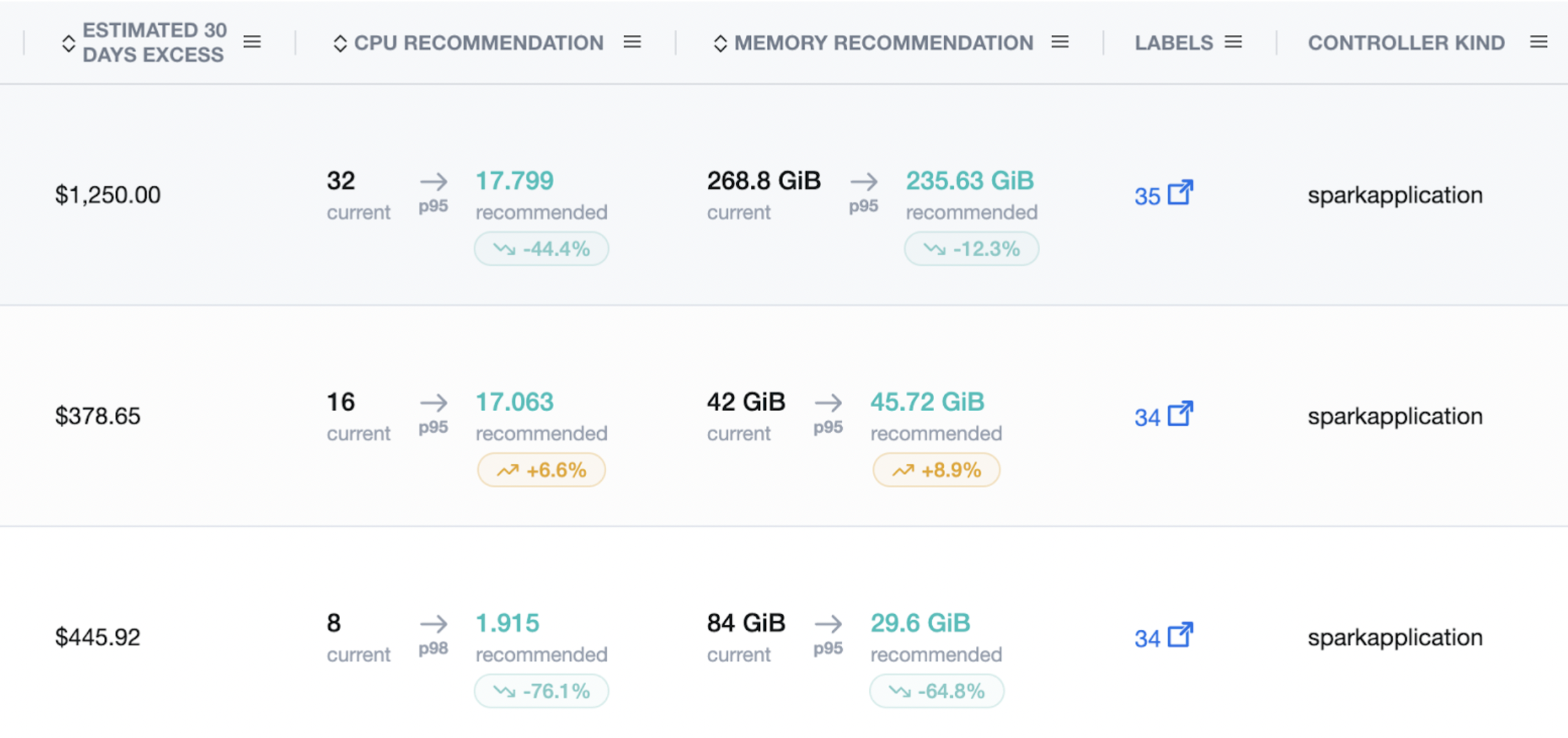
Before
- Executor requests: 8 vCPU / 84Gi (safety padding)
- Spark runtime: default cores/memory mismatch, frequent spill
After (nOps)
- Recommender → 1.9 vCPU / 29.6Gi
- Admission sets container requests/limits ≈ 2 cores / 29 Gi
- Executor env: SPARK_EXECUTOR_CORES=2, SPARK_EXECUTOR_MEMORY=29000m
- Better packing, fewer GC stalls, same (or faster) wall-clock
Operational notes & best practices
- Spark Operator required (apiVersion: sparkoperator.k8s.io/v1beta2). The operator creates the driver pod, which then creates executors; we intercept at admission time. (kubeflow.github.io)
- Don’t expect mid-run changes. Initial mode means new pods get fresh recommendations; running pods are left alone — by design. (Google Cloud)
- Memory is more than heap. If you already set spark.executor.memoryOverhead or PySpark memory, keep those in mind; our small-heap headroom complements Spark’s overhead model. (Apache Spark)
- Labels & selection. Operator-added app labels (e.g., sparkoperator.k8s.io/app-name) make it easy to query pods for a given SparkApplication. (AlibabaCloud)
Current limitations
- Admission-time only. No in-place resize for running driver/executors. That’s intentional to protect long stages. (Google Cloud)
- Executor-focused env injection. We align executor runtime knobs via env; you can opt sidecars out via annotations.
- Heuristic headroom. The small-heap buffer is fixed today; advanced memory overhead is still managed through Spark configs. (Apache Spark)
What's Next
- Configurable JVM overhead policy (annotation or policy-level)
- Forward compatibility with new Spark releases and operator updates (4.x+)
The Bottom Line
Spark on Kubernetes gives you flexibility – but it shouldn’t demand guesswork or gold-plated requests. With Spark Container Rightsizing in nOps Compute Copilot, you get startup-only, Spark-aware sizing that aligns runtime behavior with what Kubernetes actually allocates – cutting waste without risking stability. If you’re ready to stop overpaying for “just in case,” turn on Container Rightsizing in nOps UI (or use IaC nops-vpa/enabled=true), pick a policy, and let Compute Copilot do the heavy lifting.
Try it on your next SparkApplication and see how much headroom you can safely give back to your cluster.
How to Get Started
If you're already on nOps...
Have questions about Spark Rightsizing? Need help getting started? Our dedicated support team is here for you. Simply reach out to your Customer Success Manager or visit our Help Center. If you’re not sure who your CSM is, send our Support Team a message.
If you're not yet on nOps...
nOps was recently ranked #1 with five stars in G2’s cloud cost management category, and we optimize $2+ billion in cloud spend for our customers.
Join our customers using nOps to understand your cloud costs and leverage automation with complete confidence by booking a demo with one of our AWS experts.
