

Elevating AWS Cost and Usage Analytics (CUR) through Apache Druid at nOps
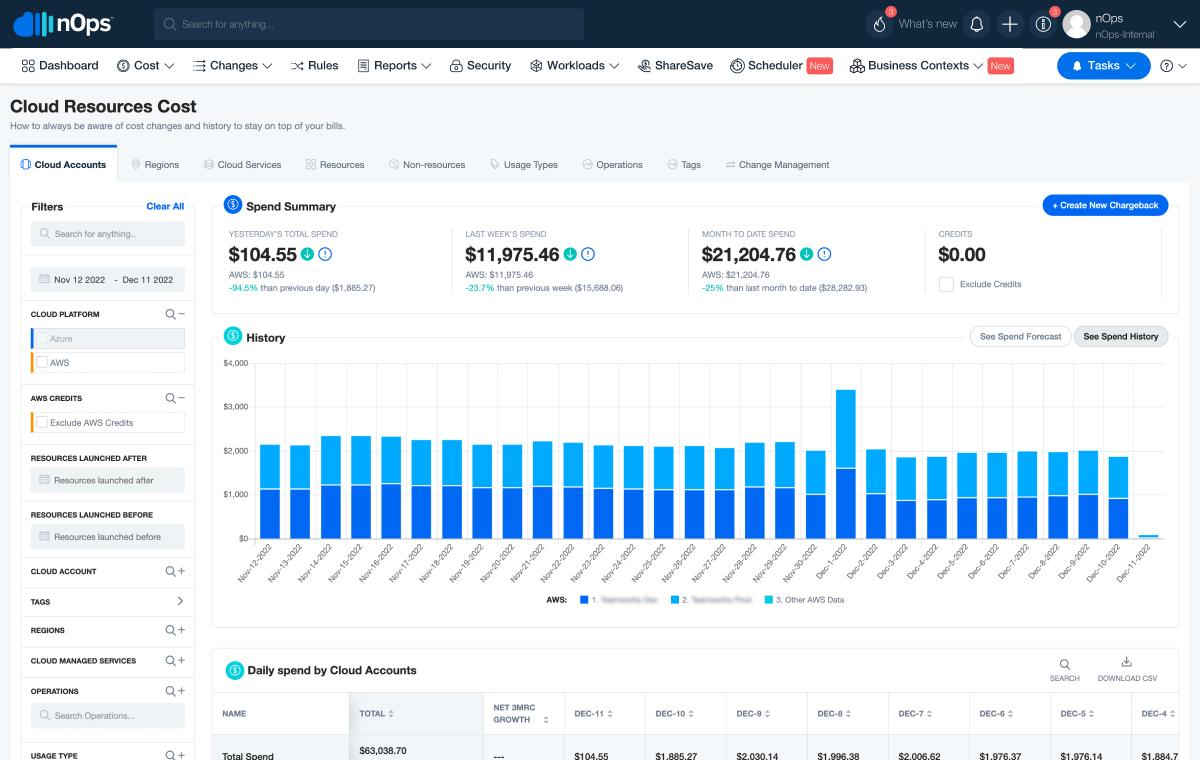
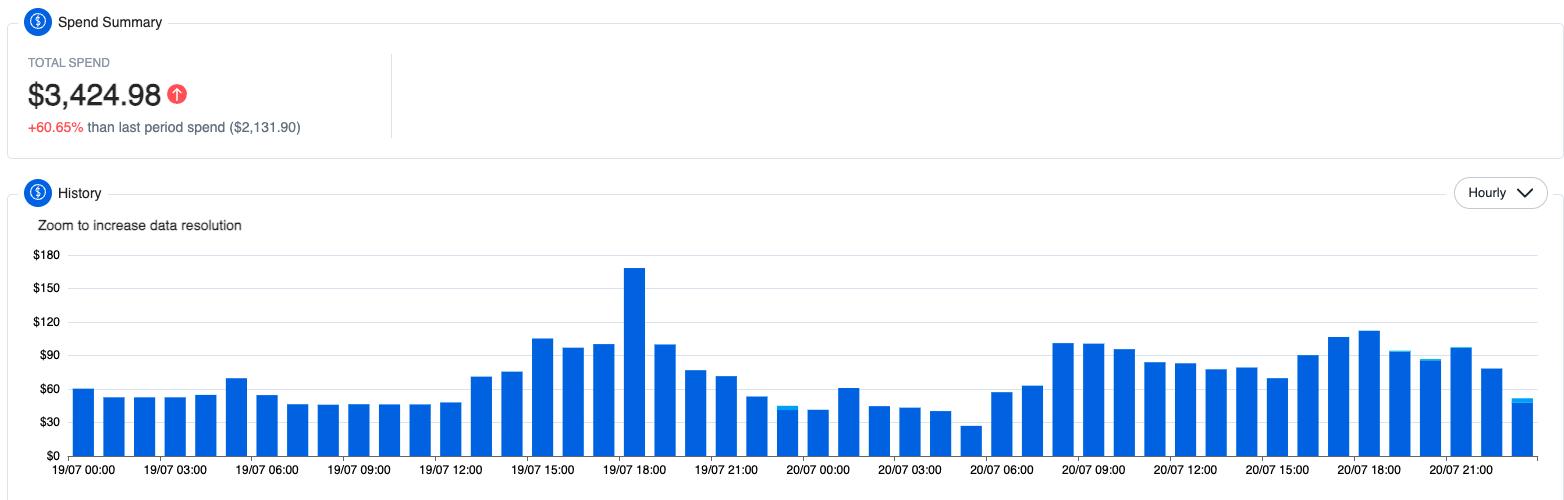
Every billable action in any given AWS account is recorded in the Cost and Usage Report (CUR) on an hourly basis, per ARN. Thus, CUR stands as the starting point for all FinOps analysis. Each CUR is based on a calendar month, so as the month progresses, the row count increases. By the end of July 2023, across all our clients, we had a total of 3.4 trillion rows. Thanks to Apache Druid, all of this data is accessible on our platform in under a second.
This is just one of the reasons how powerful Druid is and why we at nOps are utilizing it for the processing. This blog post aims to delve into the historical technological advancements that lead to Apache Druid. Simultaneously, we’ll explore why we at nOps chose Apache Druid as our primary front-end data presentation layer. Read through!
Big Data
Apache Druid and Parquet are built for trillions of rows of data. It is worth noting that, in practice, there has always been the big data problem: the strict row limit imposed by Excel (1,048,576). This limit is quickly surpassed in an average 1 hour resolution Cost and Usage Report. There are better other options for data formats but they cannot be opened in familiar applications. It should be noted that .csv and .json theoretically do not have a row (or column) limit but, after a certain point, it becomes untenable.
Apache Parquet is an open-source column-oriented file format developed as a joint effort between Twitter and Cloudera in 2013. It has a very efficient compression algorithm as well as dictionary encoding. Which means that the column names and data types do need to be constantly re-checked (as is often the case with legacy row-originated file formats). The parquet itself is made up of many ~1GB partitions. This allows safe parallel reads and writes. This is the reason why AWS offers the CUR .parquet format and also why Druid can natively ingest it.
Druid reads Parquet natively which is one of many reasons why we chose to use Druid here at nOps. Additionally, one of the key advantages of using Druid is its ability to swiftly and reliably ingest large volumes of data. We have leveraged this capability to enhance our cost analysis feature. Not only does it allow for more accurate and reliable cost data ingestion, but it also ensures that this vital information is available to our customers in the quickest time frame. In short, Druid helps us make cloud cost optimization more efficient and time-sensitive for our customers.
OLAP vs. OLTP
There are two primary types of database technology: OLAP (OnLine Analytics Processing) and OLTP (OnLine Transaction Processing). Both terms were coined in 1993 by database legend Edgar F. Codd. Interestingly, 1993 was also the year CERN made the Web protocol code royalty-free, launching the modern internet. Online, and The Internet at large, was a very new concept to the general public.
An OLAP database is optimized for high volumes of reads; an OLTP for high volumes of writes. This is why OLAP is used most often in analytics settings (such as our Business Context page). Apache Druid is an example of a cutting-edge OLAP. It is even more robust than previous OLAP technology since, by design, Druid has separated ingestion from compute. This means that the front-end user does not sense any slow down as the back-end data is updating.
Going even further back in history: online databases implies the existence of offline databases. In the past, data was stored using onsite magnetic tape drives, with tapes being swapped out as needed. Later, during the pre-broadband era, CD-ROM subscription services offered fresh data through physical discs delivered by mail, like LexisNexis or Microsoft Encarta.
New approaches to database design and technology are constantly being explored. This is out of necessity. Not only does the total amount of data keep increasing, so does the demand for analytics of said data. That’s where Apache Druid enters, potentially the best solution when dealing with terabytes (or even more) of data.
Druid’s scalable architecture empowers us to easily handle the always-increasing size of customer data, ensuring consistent performance and a top-notch user experience irrespective of the data size.
Related Content
The Ultimate Guide to Karpenter
Maximizing efficiency, stability, and cost savings in Kubernetes clusters
Download Now
Rows vs. Columns
There are two main ways a Database Management System (DBMS) can store data: by row or by column. Though column-oriented has always been explored in a research setting, the majority of what became popular was row-oriented databases. While both orientations guarantee the same query results, they have distinct long-term advantages. Row-based databases are ideal for applications, while column-oriented ones are better suited for analytics. DBMS can be deployed in either situation but if it’s a mismatch it probably won’t scale.
Postgres and MySQL are popular examples of row-oriented databases. These are best suited for simple applications that collect slower-moving user-generated data (e.g. an online shopping cart). Data is read/written using specialized row-based algorithms that have been refined over the last 20+ years. In this case, there is very little demand to reinvent the wheel. On the other hand, Cassandra and Snowflake are examples of column-oriented databases. The analytics advantages of columnar DBMS are drastic as aggregations (SUM, AVG, MIN, MAX) are very fast when only one column at time needs to be considered. The width (number of columns) of a table in this setting also matters less but would slow down a row-oriented database.
MongoDB is technically a column-oriented DB but is also a perfect example of a non-relational key-value database; where the key is a unique id and the value is often a json blob. This ostensibly solves the problem of adding new columns to a backend SQL table every time a new feature is added. Though, in practice, it is difficult to do any analytics using a key-value DB.
Apache Druid is column-oriented but also has its own file format based on segments. Each segment is a few million rows and is split by event timestamp. Less-accessed segments (e.g. last year) are automatically rebalanced and moved to deep storage. This keeps more frequency used (e.g. current month) data readily available. Such precision not only optimizes resource utilization but also enhances query performance.
Leveraging Druid’s lightning processing capabilities and unparalleled speed, we have now introduced Hourly Resolution for any Cost and Usage Report, regardless of its size. This achievement signifies sub-second response times for trillions of records, catering to thousands of users. With Hourly Resolution, we are enabling the detection of hourly usage cycles of resources, thereby aiding in making informed decisions about when to activate or pause resources based on usage patterns.
Dimensions vs. Metrics
According to database architecture best practice, there is a philosophical split between what is named and what is measured.
A dimension is anything that has a discrete value (e.g. a list of names or addresses). Whereas a metric is anything that has a continuous value (e.g. temperature or distance). The astute reader might notice that some kinds of data could be put into either category (e.g. price). The reason that these were traditionally separated in a database is because the dimension table would typically be much shorter in row count then the dimension table. By keeping dimension tables short and versioning the longer metric tables (e.g. my_measures_2020 , my_measures_2021, etc) is one of the tricks database administrators would use to keep query time reasonable.
Druid takes note of this philosophy and exploits it in an interesting way: since it is a columnar database, every dimension column can be hashed. Therefore every query that is asking for name = ‘bob’ has a faster, predefined path to take. As a result there is no need to make separate dimension and metrics tables in Druid. This is possibly the single greatest advancement in OLAP design since column-orientation came into vogue. This is one of the strongest reasons why we chose Druid at nOps. Because of the fast query processing capability of Druid, nOps Business Contexts makes cost visibility and allocation so much easier and faster. Druid allows our customers to instantly explore their data without waiting for reports to be built and sent, making data analysis quicker and more interactive.
Data Warehouse vs. Real-Time Analytics Database
A data warehouse is what it sounds like: a storage space for many different data sources. It is great for combining things into reports. Snowflake is a popular example of a data warehouse. It attempts to stay economical by way of separating compute from storage. The best case scenario for using Snowflake is for final reports that are done on a schedule. If, on the other hand, the data is being sliced and filtered on the front end, then a data warehouse is not the best option.
This is all in contrast with Apache Druid, which is a Real Time Analytics Database. It offers very fast response time for many queries per second. This means that thousands of users can slice-and-dice terabytes of data in less than a second. If needed it also supports real-time data streams (e.g. Apache Kafka).
For the curious: Druid architecture uses three main types of nodes:
- Data node which handles ingestion and processing in local storage.
- Query node which the application interacts with and then manages the result set.
- Orchestration node which manages the overall health of Druid nodes.
Each of these types of nodes autoscale as more data is being ingested or more queries are being run. This approach to division of responsibility makes Druid very reliable and tunable. As more resources are required, more nodes come to life.
Druid also has a concept of deep storage which is how data segments are moved around as the overall cluster scales out. This deep storage feature is also how data is persisted in case the Druid cluster is down. As mentioned above, less used data naturally migrated to deep storage, thus solving many problems that plagued traditional databases. This is good for us since the current month’s CUR is often being accessed more than the previous N months.
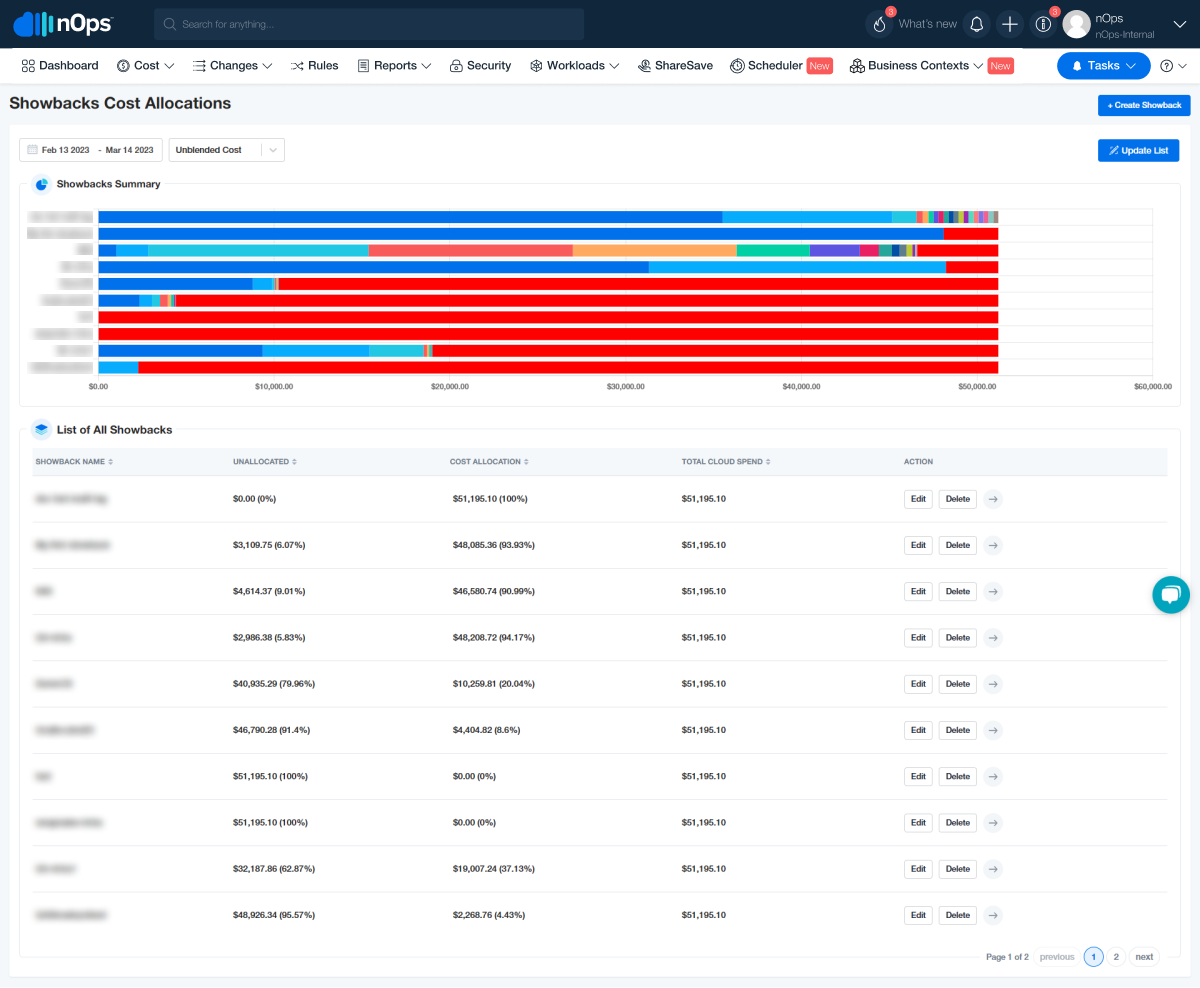
We at nOps leverage Druid’s capability of deep storage, to enhance Business Contexts further, enabling our customers to instantaneously update Showbacks and refactor at any given time. This definitely offers a competitive advantage to our customers in the decision making.
Distributed Nature Of Druid
Druid utilizes a distributed architecture, utilizing cloud-native object stores like Amazon S3 as its primary data storage solution. This approach offers several compelling benefits, including cost-effectiveness and scalability, as object stores are highly elastic and charge users only for the resources they consume. Additionally, object stores inherently provide built-in redundancy and distribution, ensuring data safety and availability without compromising data retrieval performance.
The data distribution and replication processes in Druid are intelligently automated through its “coordinator” process. This coordinator continually monitors the health of existing nodes in the data serving layer while accommodating new nodes that join the cluster. When new nodes are added, the coordinator efficiently orchestrates the data fetch process from the deep storage to these new nodes, streamlining the data re-distribution and replication tasks.
To better illustrate the advantage of Druid’s automated approach, let’s compare it with another popular distributed data processing system like ClickHouse. When adding a node to a ClickHouse cluster, the process involves multiple manual steps:
ClickHouse | Druid |
Add a node to the cluster | Add a node to the cluster. Druid handles the rest automatically, redistributing and replicating data as needed. |
Rename existing tables and create new tables with the old names (ReplicatedMergeTree) | |
Move the data from the old table to a detached subdirectory within the directory containing the new table data | |
Re-attach the data to the table by running ALTER TABLE ATTACH PARTITION on all newly added nodes |
This automation in Druid significantly reduces the administrative overhead and complexity associated with cluster management, making it a preferred choice for organizations seeking a distributed, efficient, and hassle-free data processing solution.
nOps Leverages Apache Druid To Enhance Its Cost Optimization Offerings!

While there are numerous ways to present data online, only Apache Druid met our rigorous standards. Apache Druid stands out for three main reasons: its fast data handling, its smart column-based design, and its scalable distributed setup. These strengths make Druid the perfect choice for allowing us to enhance our cost optimization features like Business Contexts.
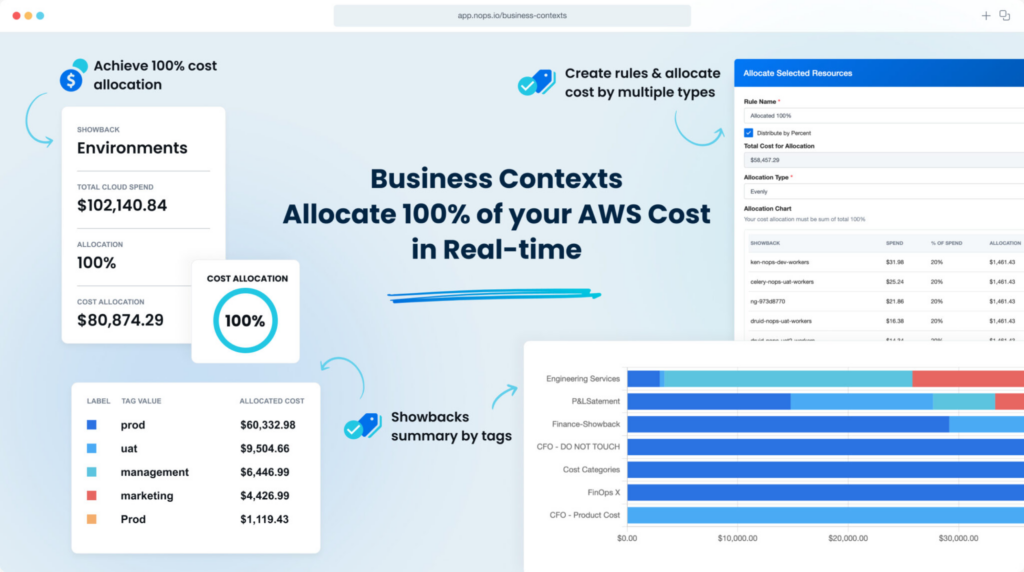
nOps Business Contexts that not only helps you monitor cloud usage or tag resources but is a comprehensive platform for exploring and analyzing your cloud spend.
- It gives our users the unparalleled ability to access and allocate every dollar of their cloud spend in real-time.
- We allow users to access years worth of cloud billing data in an interactive environment, which could easily amount to millions or billions of rows of data across thousands of billing dimensions.
- It allows you to track and attribute costs, including usage types, operations, and meaningful item types, with the power to amortize fixed expenses.
- It facilitates building powerful reports for stakeholders, providing a detailed view of your cloud infrastructure and costs, enhancing decision-making and cloud management strategies.
At nOps, we have been at the forefront of the cloud cost management industry, processing billions of dollars in cloud spend and helping organizations of all sizes to manage their AWS infrastructure more effectively. Utilizing Druid as the biggest strength, we aim to let engineers focus just on engineering; while nOps focus on FinOps for your organization.
After exploring many options and various business use cases it became clear that Apache Druid was the solution available.
Let us help you save! Sign up for nOps or Book a demo call today.
Elevating AWS Cost and Usage Analytics (CUR) through Apache Druid at nOps
























