Skip to content
Skip to content



- Blog
- EKS Optimization
- From Managed Services to Kubernetes: Migration Benefits
From Managed Services to Kubernetes: Migration Benefits
Last Updated: September 11, 2025, EKS Optimization
Managed services like Redis Cloud, Amazon RDS, Confluent Cloud and Elastic Cloud let you stand up caching, databases, streaming and search with minimal effort—no servers to provision, no failover scripts to maintain. That simplicity works well for straightforward workloads, but at scale you often need deeper customization than these black-box platforms allow.
When usage climbs, you’ll run into opaque quotas, rigid throttles and limited tuning options that turn reliable pipelines into operational chokepoints. At that inflection point, it makes sense to re-architect your data tiers—migrating caches, databases, streaming and search off hosted services and onto Kubernetes.
This article breaks down what goes wrong, why managed services aren’t enough, and the benefits of Kubernetes migration.
The Problem – When Managed Services Fall Short
Although managed services shield you from early operational complexity, as your workload grows, you’ll quickly run into a series of production headaches.
Escalating costs: Pay-per-unit pricing (GB, IOPS, vCPU) with built-in markups from different cloud providers makes large workloads prohibitively expensive.
Rigid quotas: Fixed caps on connections, IOPS or partitions prevent smooth scale-up under bursty traffic.
Opaque throttling: Black-box rate limits and credit systems throttle without clear metrics, leading to sudden stalls.
Vendor-driven upgrades: Scheduled maintenance windows and forced version bumps interrupt critical pipelines.
Limited customization: Provider-locked configurations block low-level tuning and extension modules.
Fragmented observability: Aggregated, inconsistent metrics make it hard to diagnose bottlenecks or validate SLAs.
Most importantly, someone still has to manage all of this. You need a dedicated DevOps team constantly monitoring metrics, troubleshooting performance issues, and staying on top of updates. Even though the service is “managed,” the human effort doesn’t go away—in fact, it often increases as teams try to work around limited visibility and uncertainty about how the platform will behave under real-world workloads.

Let’s take a look at how these problems manifest in some common managed services.
Service Type | Example | Why it Breaks at Scale |
Caching | Redis Cloud | Memory costs spike and you can’t rebalance shards under load. |
Relational DB | Amazon RDS (MySQL/Postgres) | IOPS throttling stalls replicas and slow failovers extend outages. |
Streaming | Confluent Cloud (Kafka) | Partition rebalance operations pause all consumer processing. |
Search | Elastic Cloud | Shard relocation during upgrades creates latency spikes and under-replication. |
Kubernetes Migration: What You Gain
Migrating your critical data tiers onto Kubernetes doesn’t just lift the hard limits of managed platforms—it fundamentally transforms how you operate and evolve at scale. Here’s what engineering teams unlock when they make the shift:
More Transparent Cost Control
Rather than paying opaque markups on GB, IOPS or vCPU, you bill directly for the nodes and pods you run. You can right-size resource requests, leverage spot/preemptible instances for non-critical workloads, and immediately identify waste via pod-level cost metrics—for much less guesswork and approximations in your cost data.

Elastic, Automated Scaling
Kubernetes’ Horizontal Pod Autoscaler and Cluster Autoscaler work in tandem to respond to real traffic patterns. Pods spin up or down based on CPU, memory or custom metrics (e.g. queue length), and nodes are added or removed when necessary. That means you no longer need to anticipate peak capacity or manually provision new VMs—bursty traffic simply absorbs the available pool, then shrinks back without intervention.Fine-Grained Configuration & Extensibility
With full control over Docker images and Kubernetes manifests, you can enable specialized modules (Lua scripts in Redis, PostGIS in Postgres, custom Kafka connectors), tweak memory and eviction policies at runtime, or inject side-car containers for logging and security. You’re no longer limited to the subset of features a managed provider offers.Zero-Downtime Upgrades on Your Schedule
Rolling update strategies let you push new versions one pod at a time, gated by readiness and liveness probes. You decide when and how to upgrade—testing release candidates in a canary subset before promoting them cluster-wide—rather than waiting on a managed service’s upgrade calendar or risking a forced, untested bump.End-to-End Observability & Alerting
By running exporters and side-cars alongside each service instance, you capture node- and pod-level metrics, logs and distributed traces. Combined with Prometheus, Grafana and service meshes, you gain deep visibility into I/O tails, replication lag and network hops—turning every performance question into a precise data query instead of a hunch.Custom Topologies & Disaster Recovery
Kubernetes lets you define multi-AZ or even hybrid-cloud clusters with affinity rules, taints/tolerations and network policies. You can script custom failover workflows via Operators, snapshot volumes on your own cadence, and orchestrate cross-region restores using Velero or built-in backup CRDs—meeting recovery-time and recovery-point objectives that managed offerings can’t guarantee.Vendor Independence & API Consistency
Your entire cluster runs on standard Kubernetes APIs and CRDs—so moving between clouds or on-premises as part of your multi cloud strategy is a matter of switching your kubeconfig, not re-wiring service calls. You avoid lock-in to one provider’s proprietary interfaces, keeping your architecture future-proof.
The Result
Teams that have migrated their managed caches, databases, streams and search workloads onto Kubernetes consistently report dramatic improvements across operational and performance metrics. Below is a representative before-and-after snapshot of what you can expect:
Metric | Managed Service | Kubernetes Deployment |
Failover Time | ~ 5 – 10 minutes (manual DNS/API failover) | < 15 seconds (pod restart + StatefulSet reattach) |
Upgrade Downtime | 30 – 60 minutes (maintenance window) | 0 minutes (rolling updates with readiness probes) |
Scale-Up Latency | 1 – 2 hours (new VM + data sync) | < 5 minutes (HPA + Cluster Autoscaler) |
Resource Utilization | ~ 40 % average CPU/RAM | ~ 70 % average (autoscaled, rightsized pods) |
Operational Overhead | Dozens of scripts & manual runbooks | Single set of YAML + Operators |
Observability Depth | Aggregated, coarse-grained metrics | Pod- and node-level metrics, distributed tracing |
Feature Release Cadence | 1 – 2 releases/day | 5 – 10 releases/day (GitOps + automated rollouts) |
The Kubernetes Migration Process: Basic Steps
Below is a streamlined, service-agnostic recipe for moving from a hosted platform (Redis Cloud, RDS, Confluent Cloud, Elastic Cloud) into a self-managed Kubernetes deployment. Adapt each step to your chosen Operator or Helm chart.
1. Export or Snapshot Your Data
Databases: Take a logical dump (e.g. pg_dump, mysqldump) or use managed-service snapshot export for data migration.
Caches & Streams: For Redis, use redis-cli –rdb; for Kafka, mirror topics with kafka-mirror-maker.
Search: Create a snapshot via the Elasticsearch Snapshot API.
2. Install the Operator or Helm Chart
bash # Example: Redis Operator via Helmhelm repo add spotahome https://spotahome.github.io/charts helm install redis-operator spotahome/redis-operator |
Repeat for Postgres (Zalando), Kafka (Strimzi), Elasticsearch (Elastic Cloud on Kubernetes), or Bitnami charts.
3. Define Your Custom Resources
Create a CR manifest that declares cluster size, version, resources and storage. For example, Postgres:
Yaml: apiVersion: db.example.com/v1 kind: PostgresCluster metadata: name: example-db spec: instances: 3 version: “13” resources: requests: cpu: “500m” memory: “1Gi” persistence: storageClass: “gp2” size: “20Gi” |
Apply it
Bash: kubectl apply -f example-db-cr.yaml |
4. Configure PersistentVolumes & Probes
- Include volumeClaimTemplates in your CR or StatefulSet spec for dynamic PV provisioning.
- Define readinessProbe and livenessProbe (e.g. a SQL ping or redis-cli ping) so Kubernetes can manage health and rolling updates.
5. Restore Data into Kubernetes
Blue/Green approach:
Deploy new pods alongside the managed service.
Restore snapshots or streams into them.
Switch your application’s connection string to the new service.
Direct cut-over:
Pause writes on the managed service.
Restore the data dump into Kubernetes.
Repoint DNS or environment variables to the new service.
6. Enable Autoscaling and ResourceQuotas
Bash kubectl autoscale statefulset example-db \ –cpu-percent=70 –min=2 –max=5 |
Also define a ResourceQuota in your namespace to prevent noisy-neighbor issues.
7. Test Failover & Scaling
Bash # Simulate pod failure kubectl delete pod example-db-0 # Verify automatic recovery and data integrity kubectl get pods -w |
Then update the CR (spec.instances: 5) and confirm new pods join correctly with data in place.
8. Monitor, Tune & Decommission
- Monitoring: Hook up Prometheus exporters and Grafana dashboards to track replication lag, CPU/memory usage, I/O latency, etc.
Tuning: Adjust resource requests, pod counts, and storage settings based on observed metrics.
Decommission: Once you’re confident in stability and performance, deprovision the managed service to stop its billing.
Kubernetes Migration Process: A Few Key Resources
To get started, here are some battle-tested Operators and Helm charts for popular managed-to-Kubernetes migrations:
- Redis Operator (spotahome/redis-operator): https://github.com/spotahome/redis-operator
PostgreSQL Operator (zalando/postgres-operator): https://github.com/zalando/postgres-operator - Strimzi Kafka Operator: https://strimzi.io/
- Elasticsearch Operator – Elastic Cloud on Kubernetes: https://github.com/elastic/cloud-on-k8s
- Bitnami Helm Charts (Redis, PostgreSQL, Kafka, Elasticsearch): https://github.com/bitnami/charts
Each of these projects includes example manifests and upgrade guides to help you declare your desired cluster topology, backups and scaling behavior directly in Kubernetes. Additional resources can be found on the Cloud Native Computing Foundation (CNCF) website.
nOps is a complete Kubernetes solution: Visibility, Management & Optimization
nOps is the only solution on the market offering end-to-end, comprehensive Kubernetes monitoring and optimization capabilities are all in one platform. It rightsizes containers to match usage, efficiently binpacks and places nodes, and once clusters are optimized, implements the optimal pricing strategy. At every level, you use less and pay less for what you use – all with complete EKS visibility.
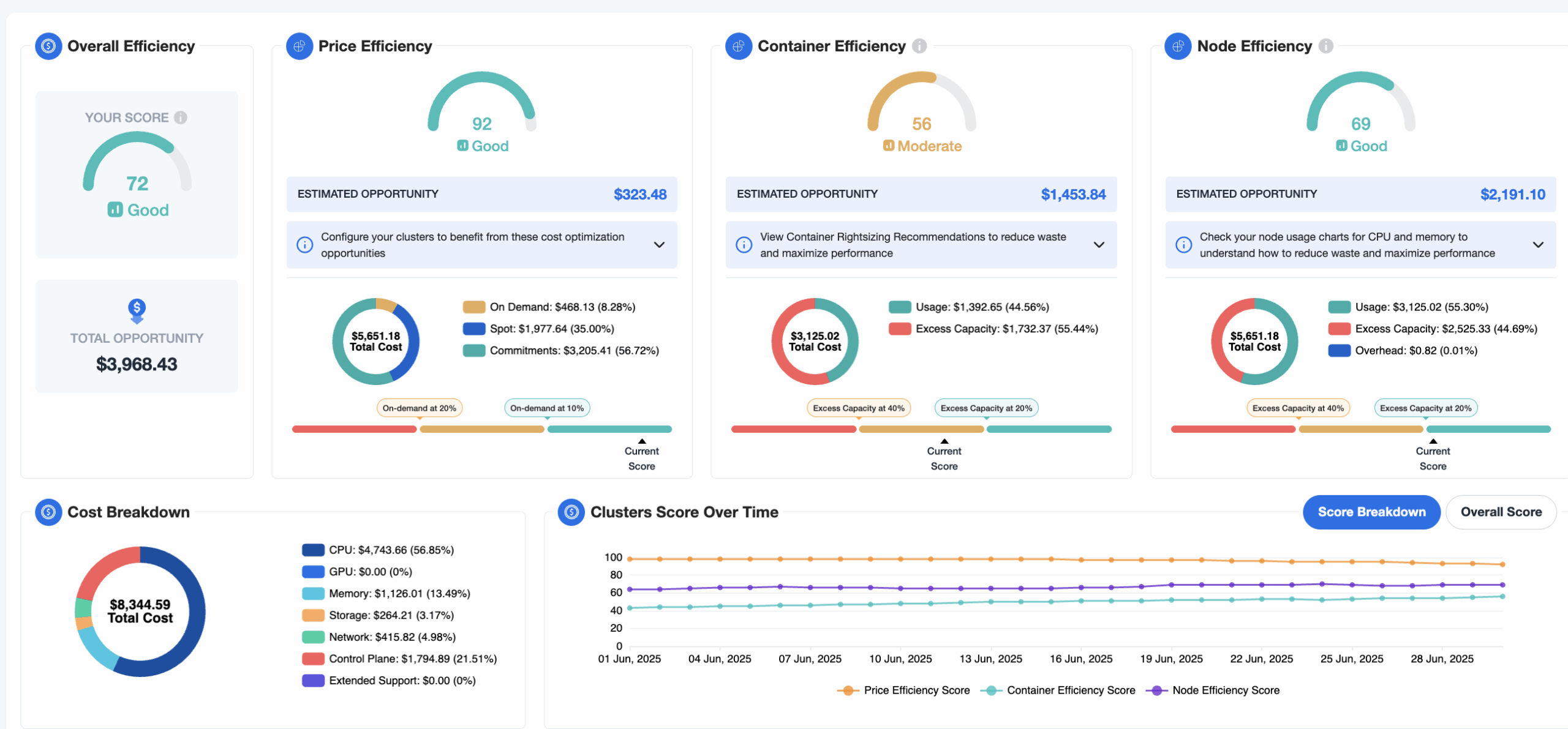
Key features include:
Critical metrics & Benchmarking for pricing optimization, utilization rates, waste optimization down to the pod, node or container level
Container Cost Allocation: nOps processes massive amounts of your data to automatically unify and allocate your Kubernetes costs in the context of all your other cloud spending.
Container Insights & Rightsizing: View your cost breakdown, number of clusters, and the utilization of your containers to quickly assess the scale of your clusters, where operational costs are coming from, and where the waste is.
Autoscaling Optimization: nOps continually reconfigures your preferred autoscaler (Kubernetes Cluster Autoscaler or Karpenter) to keep your workloads optimized at all times for minimal engineering effort and maximum cost efficiency.
Spot Savings: automatically run your workloads on the optimal blend of On-Demand, Savings Plans and Spot instances, with automated instance selection & real-time instance reconsideration
nOps was recently ranked #1 with five stars in G2’s cloud cost management category, and we optimize $2+ billion in cloud spend for our customers.
Join our customers using nOps to understand your cloud costs and leverage automation with complete confidence by booking a demo with one of our AWS experts.

Demo
AI-Powered Cost Management Platform
Discover how much you can save in just 10 minutes!
Frequently Asked Questions
Here are some common questions about the Kubernetes ecosystem, Elastic Kubernetes Service (EKS), Azure Kubernetes Service (AKS) and Google Kubernetes Service (GKS).
How To Migrate Docker Container To Kubernetes
To migrate a Docker container to Kubernetes, start by containerizing your app with a Dockerfile if you haven’t already. Then write a Kubernetes Deployment YAML that references your Docker image. Define services, volumes, and config as needed. Apply the manifests with kubectl apply to deploy your containerized app to the cluster.
Does Kubernetes Deal with Migrations?
Kubernetes does not handle application data migration (like database schema changes) automatically. However, it can run cloud migration jobs as part of your deployment process using tools like:
Init containers for setup tasks
Jobs or CronJobs for one-time or scheduled migrations
Helm hooks to trigger migration scripts during deploys
So Kubernetes orchestrates how migrations run—but you define what to migrate.
What is the role of the Kubernetes API Server?
The Kubernetes API server is the central control plane component that exposes the Kubernetes API. It handles all communication between users, CLI tools, and other Kubernetes components—validating requests, updating cluster state in etcd, and serving as the front door to your cluster’s management.