Skip to content
Skip to content


- Blog
- EKS Optimization
- What’s New in Kubernetes 1.33 “Octarine” AI, ML, Security Enhancements & More
What’s New in Kubernetes 1.33 “Octarine” AI, ML, Security Enhancements & More

As AI and multi-cloud adoption accelerate, features like dynamic resource allocation, sidecars, NUMA scheduling, and automatic scaling without disruption mean that Kubernetes is handling things users don’t even see.
Let’s dive into the key changes, what they look like, and why they matter (or you can click on the feature below to jump to the relevant section).
| Feature | Stage | Why It Matters |
| Sidecar Containers | Stable | Simplifies lifecycle management for proxies/loggers; reduces operational complexity |
| In-place Resource Resize for Pods | Beta | Enables vertical scaling without restarts or downtime |
| Dynamic Resource Allocation (DRA) | Beta | Improves GPU and hardware resource scheduling for AI/ML workloads |
| NUMA-Aware Scheduling | Beta | Boosts performance by placing workloads near memory for AI/HPC |
| Asynchronous Preemption | Beta | Enhances scheduler responsiveness under heavy AI/ML cluster loads |
| ClusterTrustBundles | Beta | Eases multi-cluster trust management and internal certificate handling |
| AdminNetworkPolicy | Beta | Allows platform-wide network enforcement independent of namespace controls |
| Pod Replacement Policy | Alpha | Reduces update disruption by controlling pod replacements based on conditions |
| Volume Populators | GA | Simplifies PersistentVolume setup with pre-loaded data sources |
| Topology-Aware Routing (PreferClose) | GA | Optimizes network traffic by routing within the same zone |
| .kuberc File for kubectl | Alpha | Customizes kubectl defaults per user for easier CLI usage |
Top 3 Highlights of Kubernetes 1.33
1. Sidecar Containers Are Now Stable
Sidecar containers — used for logging agents, proxies, and metrics collectors — are now officially supported and stable in Kubernetes. Sidecars now have well-defined behavior for restart policies, readiness probes, and OOM handling.
Until now, developers had to use workarounds to manage sidecar lifecycle with main containers. With sidecars stable, Kubernetes ensures predictable startup and shutdown behavior, reducing operational complexity for service meshes, observability, and custom networking.
Here’s an example of a sidecar configuration:
apiVersion: v1 kind: Pod metadata: name: my-app spec: containers: - name: main-app image: my-app-image - name: sidecar-logger image: logger-image lifecycle: preStop: exec: command: ["/bin/cleanup-logs"] 2. In-place Resource Resize for Vertical Scaling of Pods (Beta)
Kubernetes 1.33 allows the Vertical Pod Autoscaler (VPA) to update CPU and memory resource allocations without restarting pods.
Traditionally, resizing required deleting and recreating pods, causing disruptions. In-place VPA means you can now dynamically rightsize resource usage for running applications without downtime — ideal for scaling real-world production workloads smoothly.
Example configuration:
apiVersion: autoscaling.k8s.io/v1 kind: VerticalPodAutoscaler metadata: name: my-vpa spec: targetRef: apiVersion: "apps/v1" kind: Deployment name: my-deployment updatePolicy: updateMode: "Auto" 3. Dynamic Resource Allocation (DRA) Improvements (Beta)
The DRA API, critical for GPU and hardware accelerators, has been refined in v1.33. The new beta version simplifies how Kubernetes allocates special hardware resources like GPUs and high-speed network cards.
As AI/ML and HPC workloads become mainstream, dynamically allocating GPUs is essential. DRA now makes it easier to schedule workloads that need hardware devices without manual intervention or waste.
Example resource claim:
apiVersion: resource.k8s.io/v1beta1 kind: ResourceClaim metadata: name: gpu-claim spec: resourceClassName: nvidia-a100 Machine Learning & AI Updates

As AI and HPC workloads grow more complex, Kubernetes 1.33 brings key improvements to scheduling, device management, and resource efficiency, including:
Dynamic Resource Allocation (DRA) Beta Improvements
The DRA improvements in Kubernetes 1.33 bring simpler APIs, broader compatibility, and better support for AI/ML applications that rely on GPUs, FPGAs, and custom devices.
The update makes DRA easier to adopt for third-party schedulers and better integrates it with Kubernetes core features.
NUMA-Aware Scheduling (Beta)
Non-Uniform Memory Access (NUMA) aware scheduling enables Kubernetes to place workloads closer to their memory, improving performance for AI, ML, and high-performance computing (HPC) workloads.
Why It Matters:
Asynchronous Preemption (Beta)
Why It Matters:
Security Updates

ClusterTrustBundles (Beta)
Why It Matters:
Admin Network Policy (Beta)
Why It Matters:
Strengthens Kubernetes network security by allowing platform administrators to enforce policies even when namespace-level NetworkPolicies are missing.
Example:
apiVersion: networking.k8s.io/v1alpha1 kind: AdminNetworkPolicy metadata: name: deny-egress spec: priority: 100 ingress: - action: Allow Platform Simplification and Operations

Pod Replacement Policy (Alpha)
A new PodReplacementPolicy allows users to control whether pods are proactively replaced based on pod conditions, making updates less disruptive.
Volume Populators (GA)
Volume Populators allow users to pre-populate PersistentVolumes with content from custom sources — like datasets for ML models.
Why It Matters:
Topology-Aware Routing (GA)
kubectl .kuberc File (Alpha)
kubectl now supports a .kuberc file that stores default arguments and config, making it easier for users to customize kubectl behavior across clusters.
Takeaways from Kubernetes 1.33
As enterprises increasingly run critical and AI-heavy workloads on Kubernetes, these improvements make clusters easier to scale, safer to operate, and better aligned with modern cloud-native applications.
As teams increasingly adopt Kubernetes, they face challenges in configuring, monitoring and optimizing clusters within complex containerized environments.
Most teams manage these complexities with a combination of manual monitoring, third-party tools, and basic metrics provided by native Kubernetes dashboards — requiring them to switch between different tools and analyze data from multiple sources.

nOps is a complete Kubernetes solution: Visibility, Management & Optimization
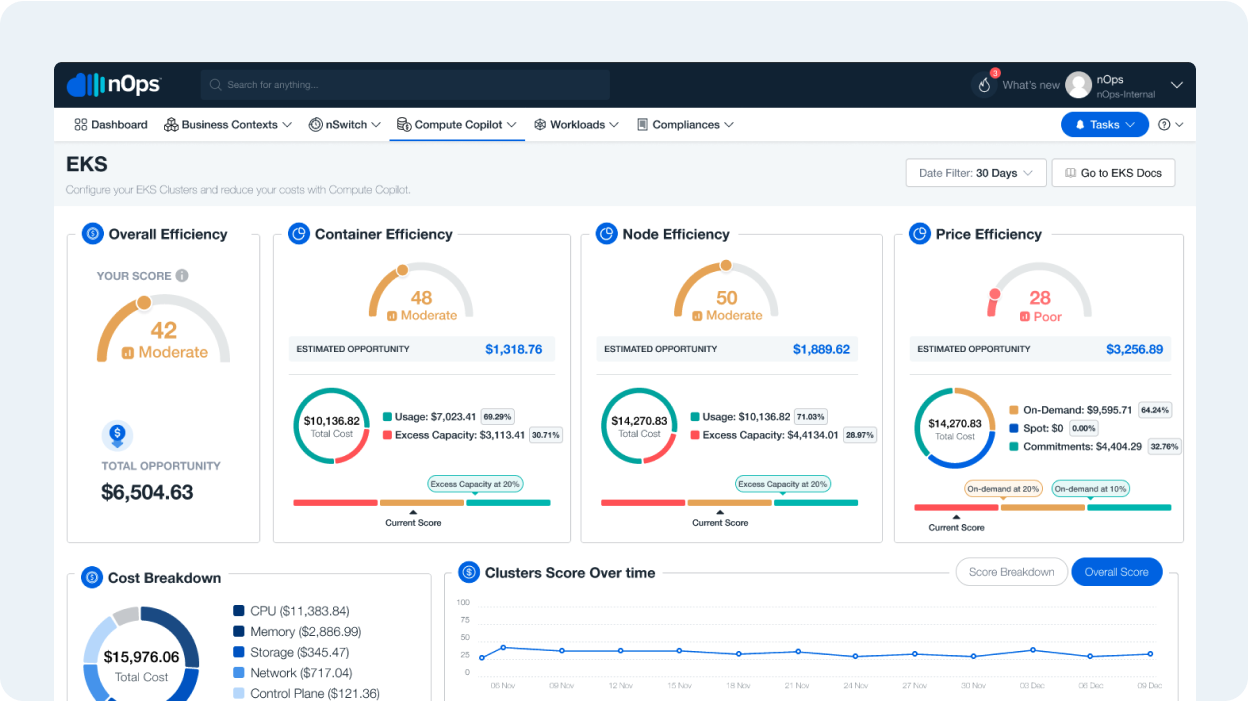
Key features include:
- Critical metrics & benchmarkingfor pricing optimization, utilization rates, waste optimization down to the pod, node or container level
- Container Cost Allocation: nOps processes massive amounts of your data to automatically unify and allocate your Kubernetes costs in the context of all your other cloud spending.
- Container Insights & Rightsizing. View your cost breakdown, number of clusters, and the utilization of your containers to quickly assess the scale of your clusters, where costs are coming from, and where the waste is.
- Autoscaling Optimization: nOps continually reconfigures your preferred autoscaler (Cluster Autoscaler or Karpenter) to keep your workloads optimized at all times for minimal engineering effort.
- Spot Savings: automatically run your workloads on the optimal blend of On-Demand, Savings Plans and Spot instances, with automated instance selection & real-time instance reconsideration
nOps was recently ranked #1 with five stars in G2’s cloud cost management category, and we optimize $2+ billion in cloud spend for our customers.
Join our customers using nOps to understand your cloud costs and leverage automation with complete confidence by booking a demo with one of our AWS experts.
Last Updated: May 20, 2025, EKS Optimization