Skip to content
Skip to content


Scalability is one of the core features of Kubernetes. Automating the scaling process simplifies overall resource management which would have otherwise taken intensive manual efforts to achieve.
Autoscaling allows users to automatically adjust the number of resources according to the changing demands while ensuring optimized resource allocation and improved cluster efficiency.
In this article, we take an in-depth look into Kubernetes autoscaling and everything to know about it:
What is Kubernetes Autoscaling?
Kubernetes autoscaling optimizes resource usage and total cloud costs by automatically scaling clusters up or down according to the changing demands. It prevents excessive spending and improves overall efficiency.
For instance, if a service has increased load during some specific times of the day, Kubernetes autoscaling can handle the change in demand by automatically increasing the deployed nodes as well as cluster nodes. When the overall load decreases, Kubernetes adjusts the nodes and pods to save on resources.
Autoscaling can help prevent capacity-related failure (when applications don’t have all the infrastructure-related resources it needs) and also prevent users from paying extra for resources that they don’t even need 24/7.
Different Methods for Autoscaling in Kubernetes
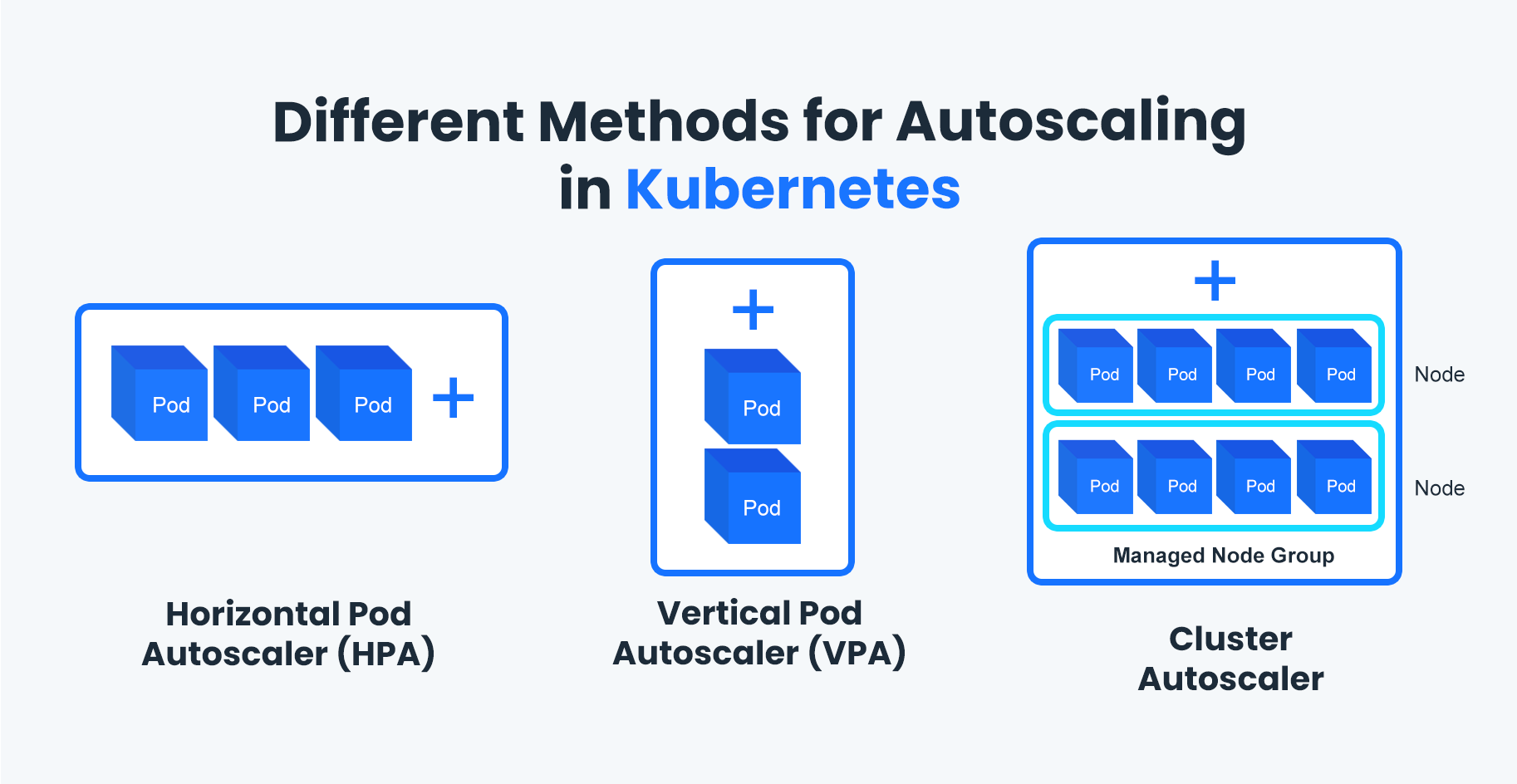
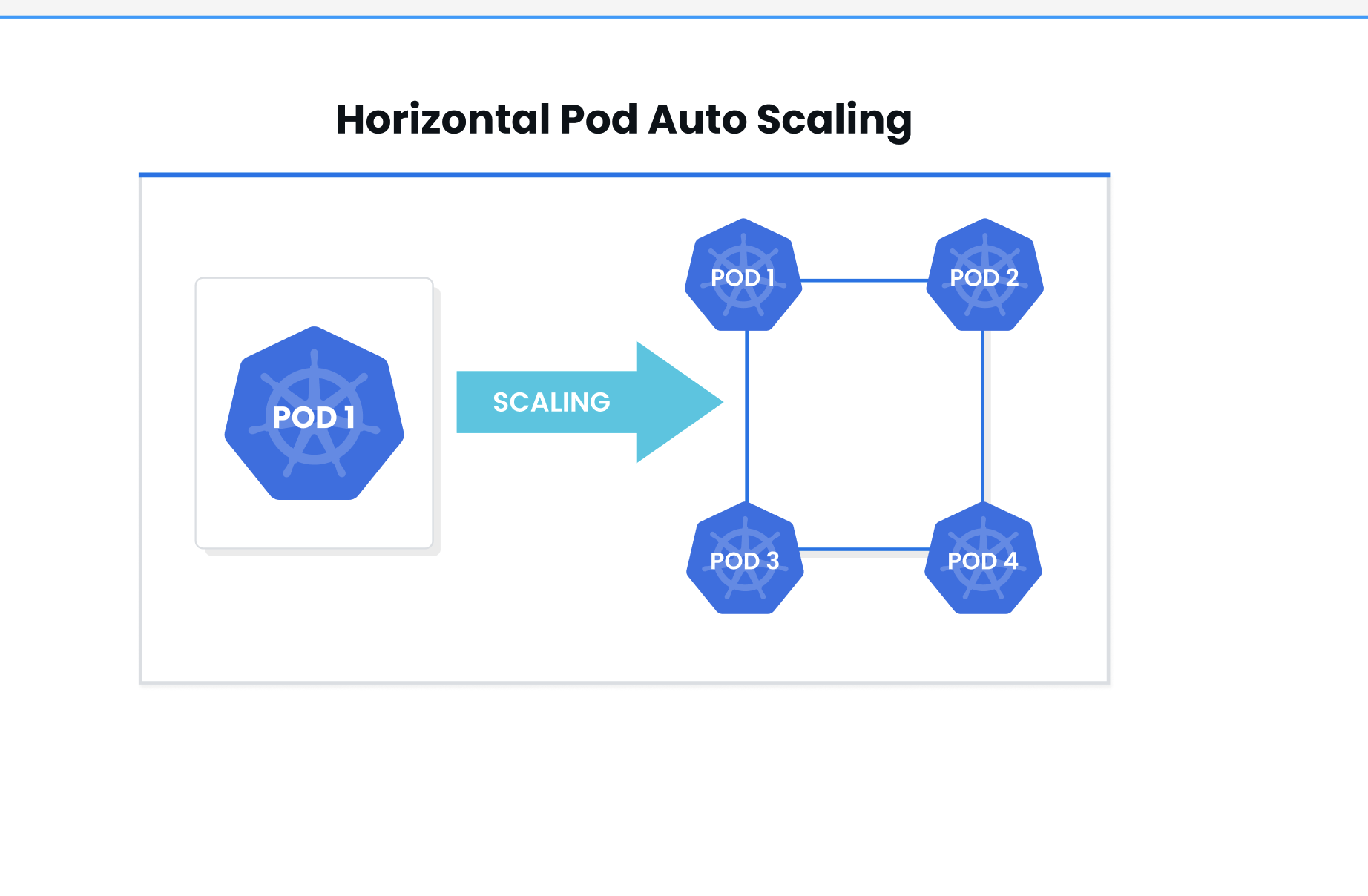
Horizontal Pod Autoscaler (HPA)
Horizontal Pod Autoscaler or HPA is a Kubernetes autoscaling method that refers to changing up the number of pods that are available for the cluster, in case there are any sudden changes in demand. This technique is mostly used to avoid any resource deficits since it scales pods instead of available resources.
With horizontal scaling, you create different rules for stopping or starting instances assigned to a resource, when they end up reaching their lower or upper thresholds.
First, you need to define target usage for different metrics like memory utilization, and CPU usage, or minimum/ maximum desired replicas. The HPA will then monitor the pods in the workload and decide to scale the number of running pods up or down depending on the current usage and the desired target metrics.
There are some limitations to HPA, including:
- You may have to create applications with a scale-out mindset so that distributing workloads across different servers becomes possible.
- Since instances can take a few minutes to load, it may not be able to always handle unexpected demand peaks.
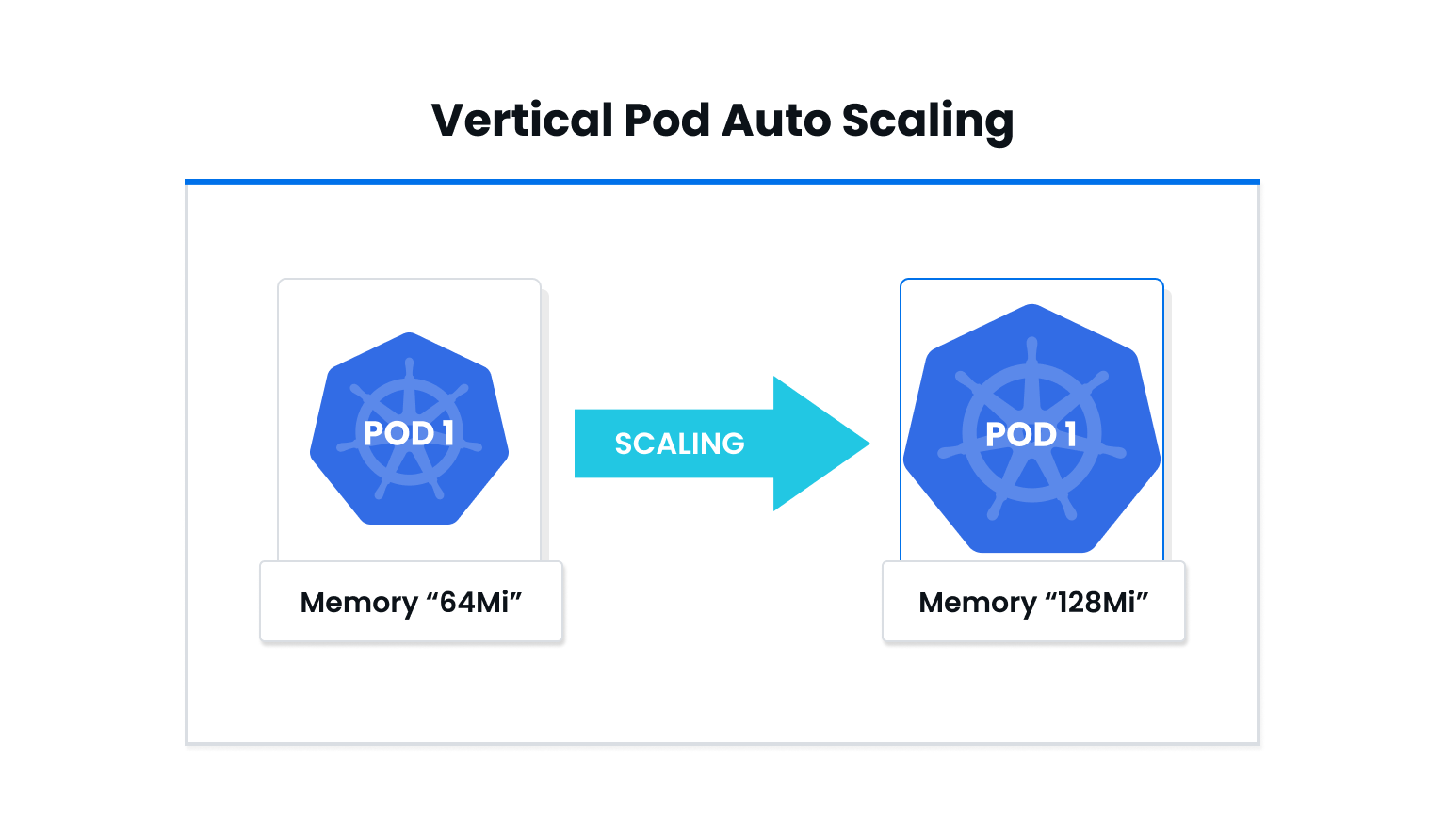
Vertical Pod Autoscaler (VPA)
Vertical Pod Autoscaler involves dynamically provisioning different resources like CPU and memory usage in order to meet the changing requirements of cluster nodes. VPA is responsible for modifying pod resource request parameters according to the consumption metrics of the workload.
By adjusting pod resources according to usage over time, it becomes possible to optimize cluster resource utilization and minimize resource wastage. With vertical autoscaling, you establish a set of rules that in turn affect the memory utilization or CPU usage allocated to existing instances.
There are some limitations to VPA, including:
- For every underlying host, there can be some connectivity ceilings which can in turn lead to network-related limitations
- Even if some resources are idle all the time, you would still have to pay for them
Horizontal and vertical scaling can make sure that all the services running in the cluster can handle demand automatically while ensuring there is no overprovisioning during low usage demand. But both of them cannot address one major issue: What to do when the load is already at peak and the nodes present in the cluster are also overloaded with recently scaled pods?
In a scenario like this, Cluster Autoscaler can be incredibly helpful.
Cluster Autoscaler
Cluster Autoscaler works by autoscaling the cluster itself. It increases or decreases the number of nodes present inside a cluster based on the total number of pending pods. Depending on the current utilization of the cluster, the autoscaler reaches out to the cloud provider’s API to dynamically scale the nodes attached to the cluster. Then the pods present in the cluster rebalance themselves.
Cluster Autoscaler works by looking for any pending pods that cannot be scheduled on any of the existing nodes, which can happen due to numerous reasons like inadequate memory or CPU resources.
For every unscheduled pod in the cluster, the autoscaler will first check if adding a node could unblock the pod. If it is possible, the autoscaler will just add the node to the present node pool.
The Cluster Autoscaler also constantly scans nodes that are present in the node pool to check if there are any nodes with pods that can be rescheduled. When it comes to deciding whether to move a node or not, Cluster Autoscaler uses pod priority as the main factor.
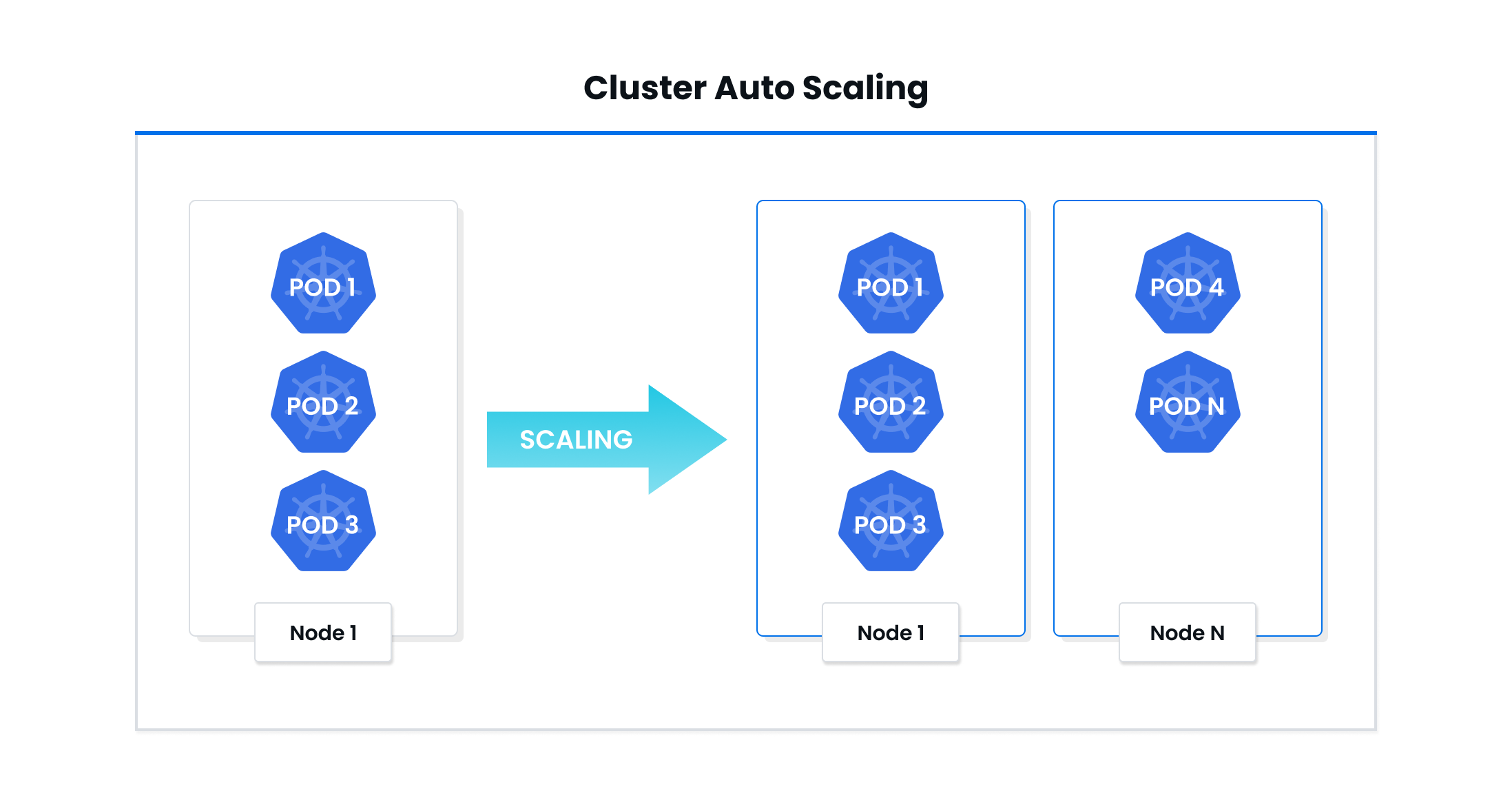
It’s important to remember that since Cluster Autoscaler works on the infrastructure level, it needs relevant permissions to be able to delete or add infrastructures.
There are some limitations to Cluster Autoscaler as well, including:
- Cluster Autoscaler only reviews the pod’s specific requests and limits for memory usage or CPU utilization–but scaling decisions are not made based on these factors. This in turn means that the autoscaler will not be able to detect any unused computing resources.
- The autoscaler has to send a request to the cloud provider when a cluster needs to be scaled. While it only takes the autoscaler less than a minute to send the request to the cloud provider, it can take a few minutes for the cloud provider to assess the request and create a node. This can, in turn, lead to delays and affect the overall performance of the application.
Best Practices for Scaling Kubernetes Workloads
- Decrease costs with mixed instances
Using mixed instances makes it possible to run different instance types in a single cluster which can, in turn, reduce costs. When scaling, using mixed instances can help ensure the cluster is always sized according to the workloads running on it and that you are using the most cost-efficient instances for the workload.
- Make sure HPA and VPA policies do not clash
If the HPA and VPA policies are not aligned with each other, then both autoscaling methods may end up scaling pods in opposite directions at the very same time. Therefore, HPA and VPA policies should be carefully established to ensure they complement each other and are consistent.
- Use VPA along with Cluster Autoscaler
When you use VPA combined with Cluster Autoscaler, they both cancel out each other’s limitations leading to a more efficient scaling of the cluster.
While VPA provides more precise control over resources used by the pods, autoscaler can make sure the cluster has the right number of pods to support the workload.
How can nOps Karpenter Solution (nKS) Help Optimize Kubernetes Autoscaling?
nOps Karpenter Solution (nKS) leverages the power of open-source Karpenter to go beyond what Cluster Autoscaler, HPA, or VPA can do and supercharge autoscaling. It can scale, manage, and provision nodes based on the configuration of custom provisioners.