Skip to content
Skip to content


- Blog
- Right Sizing
- How to Minimize AWS EBS Costs
How to Minimize AWS EBS Costs
Amazon Elastic Block Store (EBS) is one of the most widely used storage services in AWS, powering everything from databases to analytics workloads. It provides persistent block storage that attaches directly to Amazon EC2 instances, giving applications the performance and reliability needed for production environments.
But with flexibility comes cost and complexity. EBS charges for the volumes you provision, the snapshots you store, and the IOPS you consume. Without the right strategy, organizations can rack up significant waste from oversized volumes, unused snapshots, or inefficient workload patterns.
In this guide, we’ll explain what EBS does, highlight its key features, break down how pricing works, and walk through 21 practical optimization strategies to keep performance high while costs stay under control.
What Does Amazon Elastic Block Store (EBS) Do?
Amazon Elastic Block Store is a scalable, high-performance block storage service designed for AWS EC2 (Elastic Compute Cloud). It is a persistent way to store your data with EBS volumes. Unlike ephemeral instance storage, which disappears when an instance is stopped or terminated, EBS volumes retain data until you delete them.
EBS volumes can be attached and detached from EC2 instances on the fly, scaled up or down to match workload needs, and replicated within an Availability Zone for durability. They’re commonly used for databases, file systems, analytics workloads, and any application where low-latency access to data is critical. The best thing about AWS volumes is that you only pay for what you use.
Key Features of Amazon EBS
Amazon EBS is designed to give AWS users flexible, durable, and high-performance storage for a wide range of workloads. Some of its most important features include:
-
Persistent storage – Data on an EBS volume remains available even after an EC2 instance is stopped or terminated.
-
Multiple volume types – EBS supports a variety of volume types (gp2, gp3, io1, io2, st1, sc1) optimized for different performance and cost requirements, from general-purpose use cases to high IOPS databases or large throughput workloads.
-
Scalability – Volumes can be resized and reconfigured with no downtime, allowing teams to adapt to changing workload demands.
-
High availability – EBS automatically replicates data within an Availability Zone to protect against hardware failure.
-
Snapshots – Point-in-time backups can be created and stored in Amazon S3, making it easy to protect data, restore volumes, or create new ones from existing baselines.
-
Encryption – Native integration with AWS Key Management Service (KMS) provides encryption at rest, in transit, and during snapshot operations.
-
Integration with AWS ecosystem – EBS integrates with CloudWatch for monitoring, Trusted Advisor for recommendations, and IAM for access control, making it part of AWS’s broader management stack.
EBS Pricing: How AWS EBS Costs Are Calculated
Amazon EBS charges based on the type and size of the volume you provision, along with any extra performance you enable. General Purpose SSDs (gp3) let you pay separately for storage, IOPS, and throughput, while high-performance volumes like io2 add premiums for durability and consistency. Snapshots stored in Amazon S3 are billed per GB, and cross-AZ data transfers add more charges.
Because you pay for provisioned capacity — not just what you use — it’s easy to over-spend on idle volumes, unused snapshots, or oversized disks.
For a complete explanation and breakdown of AWS EBS Optimized Pricing, check out Amazon EBS Pricing: The Complete Guide.
AWS EBS Optimization Strategies
Managing EBS efficiently means balancing performance with cost — here are 21 proven strategies to cut waste, improve reliability, and get the most out of every dollar you spend on EBS.
1. Avoid using EBS for temporary storage
EBS is designed for persistent workloads and charges you for every GB you provision, regardless of how long you use it. If you attach EBS to an EC2 instance for scratch files or temporary data, you’ll continue paying even after the workload ends unless you delete the volume. Instead, use EC2 instance store volumes for ephemeral data, like caches or buffer files, since they cost nothing extra and vanish automatically when the instance stops. This simple switch prevents unnecessary charges and ensures EBS is reserved for data you truly need to persist.
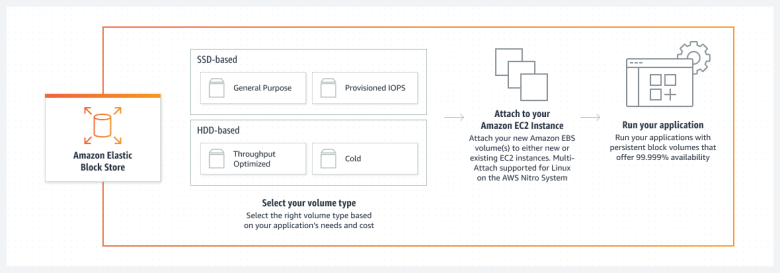
2. Pick the right EBS volume type
EBS volumes fall into two main categories:
-
SSD-backed storage – optimized for transactional workloads that need low latency and fast random I/O
-
HDD-backed storage – optimized for throughput-intensive workloads that read or write large sequential data sets
Within these categories, you can choose from different subtypes:
-
Provisioned IOPS SSD (io1/io2) – the most expensive, built for mission-critical applications like large relational databases needing consistent high IOPS
-
General Purpose SSD (gp2/gp3) – the default choice for most workloads, balancing cost and performance; gp3 lets you scale IOPS and throughput independently at lower cost
-
Throughput Optimized HDD (st1) – cost-effective for big data, log processing, and other sequential access workloads
-
Cold HDD (sc1) – the cheapest option, suited for infrequently accessed data and archival storage
When choosing, consider capacity, application throughput, and IOPS requirements. For most workloads, General Purpose SSD volumes are the right starting point. If you need more than 10,000 IOPS, upgrade to Provisioned IOPS SSD. For large sequential data sets, HDD volumes can cut costs by more than 50% compared to SSDs.
Continuous EBS optimization
3. Tag Those EBS Volumes
Without proper tagging, EBS costs often end up unallocated or invisible. Tagging volumes ensures every dollar can be tied back to the right project, team, or environment.
Best practices:
-
Apply consistent tags like
Project,Environment, orOwnerto every volume -
Automate tagging policies through AWS Organizations or Config rules
-
Use cost allocation tags in the AWS Billing console to split charges across teams
Good tagging hygiene doesn’t reduce the raw price of EBS but eliminates wasted spend by surfacing forgotten or idle volumes.
4. Use EBS-optimized instances
Not all EC2 instances handle EBS traffic equally. An EBS-optimized instance gives your volumes dedicated bandwidth, so storage performance isn’t dragged down by network congestion. For high-IOPS workloads like databases, this can mean the difference between stable performance and wasted IOPS.
Which instances are EBS-optimized?
| Instance Type Family | EBS-Optimized by Default? | Notes |
|---|---|---|
| t3, t4g, m5, m6, c5, c6 | ✅ Yes | Most current-gen families automatically include dedicated bandwidth |
| Older families (e.g., m3, c3, r3) | ❌ No | Must be explicitly enabled at launch (extra hourly charge applies) |
| Storage-heavy families (i3, d2, h1) | Mixed | Some focus on local storage; check specs for EBS support |
Tip: Always match the instance’s throughput capacity with your EBS volume type. Running a high-performance io2 volume on an underpowered instance wastes money.
5. Attach volumes to EC2 instances that sustain higher throughput to Amazon EBS
Not every EC2 instance can push EBS to its limits. Some have limited throughput, which means even if you pay for high-performance volumes, you’ll never see their full potential.
Do:
-
Match high-performance volumes (io2, gp3 with extra IOPS/throughput) to compute families with enough EBS bandwidth (e.g., m5, c6i, r6g).
-
Check AWS documentation for “Maximum EBS bandwidth” per instance type before provisioning.
-
Consolidate workloads onto fewer, more capable instances rather than spreading them across many underpowered ones.
Don’t:
-
Run database or analytics workloads on burstable t2/t3 instances if they need steady high throughput — you’ll bottleneck EBS.
-
Overprovision IOPS on volumes attached to small instances; you’ll pay for performance you can’t use.
6. Initialize the volumes you create from snapshots
When you create a new EBS volume from a snapshot, the data is lazily loaded. This means blocks aren’t fully restored until they’re accessed for the first time. The result: unpredictable latency, where your application slows down during initial reads. For databases or latency-sensitive apps, this can create costly downtime or force engineers to overprovision IOPS just to mask the lag.
Technical note: To avoid this, run the dd or fio command after creating the volume to pre-warm it. This process reads every block, forcing AWS to pull the data from S3 into EBS ahead of time. While it adds time up front, it ensures consistent performance once the volume is in production.
#7: Use RAID setups
RAID (Redundant Array of Independent Disks) can combine multiple EBS volumes to achieve higher performance or redundancy. For storage-heavy workloads, this approach can help balance speed, durability, and cost efficiency.
Pros
-
RAID 0: Stripes data across volumes for higher throughput and IOPS — useful for databases or analytics workloads that need maximum performance.
-
RAID 1: Mirrors volumes for redundancy, protecting against individual volume failure.
-
Can sometimes be cheaper than overprovisioning a single large io2 volume by combining smaller gp3 volumes.
Cons
-
RAID 0 has no redundancy — if a single volume fails, all data is lost.
-
RAID setups consume more volumes, which can complicate management and increase baseline storage costs.
-
AWS already provides redundancy within an Availability Zone, so RAID 1 may duplicate protection without cutting costs.
Use RAID selectively: it can deliver big performance gains or cost savings in the right scenarios, but adds complexity and risk elsewhere.
#8: Optimize snapshot frequency
Snapshots are incremental, so while each one may seem small, frequent schedules can quietly inflate costs over time. Taking snapshots every hour or for non-critical workloads often results in paying for redundant backups you’ll never use. Instead, set snapshot intervals based on workload importance — daily for production, weekly for dev or test. This keeps recovery options intact while avoiding unnecessary storage costs.
9. Remove unused snapshots
Old snapshots often pile up in Amazon S3, long after the volumes they were created from are gone. Because snapshots are billed per GB-month, these forgotten backups can quietly rack up charges. Regular cleanup keeps costs predictable and prevents unnecessary sprawl.
How to minimize EBS cost of snapshots:
-
Identify orphaned snapshots — use AWS Cost Explorer, nOps, or scripts to flag snapshots not tied to active volumes.
-
Review retention requirements — check whether older snapshots are needed for compliance or disaster recovery.
-
Delete or archive — remove snapshots you don’t need, or move them into a lower-cost tier like Glacier if you want long-term retention.
-
Automate — set policies with Data Lifecycle Manager or third-party tools so snapshots are pruned without manual intervention.
10. Implement Lifecycle policies
Manually creating and deleting EBS snapshots is error-prone — and usually leads to either too few backups or too many expensive ones. AWS Data Lifecycle Manager (DLM) lets you automate this process by defining policies for snapshot creation and expiration.
Example policy:
-
Take a snapshot every 24 hours
-
Keep daily snapshots for 7 days
-
Retain 4 weekly snapshots for longer-term recovery
-
Automatically delete older ones beyond these rules
With lifecycle policies, you strike a balance between durability and cost efficiency, ensuring backups are always available without paying for endless historical data.
11. Automate volume resizing
EBS volumes are billed by provisioned size, so oversized volumes quickly waste money. Manual resizing is slow, but AWS and third-party tools make it possible to rightsize automatically.
How to do it:
-
Use Amazon CloudWatch metrics to monitor volume utilization.
-
Set thresholds (e.g., if usage > 80% for 5 minutes, trigger expansion).
-
Automate resizing with AWS Lambda or the ModifyVolume API.
-
For continuous optimization, platforms like nOps can auto-detect oversized volumes and downsize them safely.
This keeps EBS aligned with workload demand while cutting down on overprovisioned storage costs.
12. Provision enough IOPS for the job
Underprovisioning IOPS leads to slow applications; overprovisioning wastes money. Matching workload requirements to the right EBS performance tier is key.
Rule-of-thumb IOPS guidance:
| Volume Type | Baseline IOPS | Max IOPS | Best For | Cost Angle |
|---|---|---|---|---|
| gp3 | 3,000 included | Up to 16,000 | General workloads | Scale IOPS separately from storage — cheaper than gp2 |
| gp2 | Scales with size (3 IOPS/GB) | Up to 16,000 | Legacy general-purpose SSD | Often more expensive than gp3 for same performance |
| io1/io2 | Configurable | Up to 64,000 | High-performance DBs, low-latency apps | Pay for provisioned IOPS even if unused |
| st1/sc1 | N/A (throughput-based) | N/A | Sequential access workloads | Not designed for transactional IOPS |
Tip: Start with gp3 for most workloads. Move to io2 only if latency-sensitive apps demand >16,000 IOPS.
13. Watch and adjust IOPS with CloudWatch
Provisioned IOPS are only cost-effective if you actually use them. CloudWatch makes it easy to see whether your volumes are over- or under-provisioned.
Step 1: Track usage
Enable the VolumeReadOps and VolumeWriteOps metrics in CloudWatch to measure actual I/O activity.
Step 2: Compare to provisioned IOPS
Check whether average utilization is far below provisioned levels. If so, you’re paying for performance you don’t need.
Step 3: Right-size volumes
Use the ModifyVolume API or console to adjust IOPS up or down.
Step 4: Set alarms
Create CloudWatch alarms to notify you when IOPS consistently run below 30% or spike close to 100%, so you can resize before costs spiral or performance suffers.
14. Set up IOPS alerts in Amazon CloudWatch
Provisioned IOPS only save money if they match your workload. CloudWatch alerts notify you when utilization falls too low (you’re overpaying) or spikes too high (you risk slowdowns).
How to set it up:
-
Go to the CloudWatch console and create a new alarm.
-
Select the EBS metric for read or write IOPS.
-
Define thresholds — for example, “alert me if IOPS drop below 1,000” or “spike above 90% utilization.”
-
Choose an SNS topic or email address to receive notifications.
These alerts act as an early-warning system, so you can resize volumes before they drive up costs or impact performance.
15. Benchmark your EBS volumes
Provisioned IOPS and throughput are only worth paying for if your workloads actually use them. Benchmarking helps confirm whether your volumes are sized correctly or wasting money.
Typical benchmarks:
-
If average IOPS or throughput consistently stays below 30–40% of what you provisioned, you’re overpaying and should scale down.
-
If utilization frequently sits above 80–90%, you risk throttling and should provision more.
-
The “sweet spot” is steady utilization in the middle — enough headroom for spikes without paying for unused performance.
16. Ensure your app sends enough I/O requests when using HDD volumes
Throughput-optimized (st1) and cold (sc1) HDD volumes only deliver their advertised performance if you drive large, sequential I/O.
-
st1 (Throughput Optimized HDD): Baseline of 40 MB/s per TB, with burst up to 250 MB/s.
-
sc1 (Cold HDD): Baseline of 12 MB/s per TB, with burst up to 80 MB/s.
If your application issues small or random requests, you won’t hit these throughput levels — but you’ll still pay for the provisioned storage. For workloads that can’t sustain sequential reads/writes, SSD-backed volumes (gp3, io2) are usually more cost-effective, even at a higher per-GB price.
17. Optimize the read/write patterns
EBS volumes perform best when your I/O patterns align with the design of the volume type. Random, small reads and writes can waste throughput or IOPS, while larger, sequential operations maximize efficiency.
Examples:
-
Databases on gp3 or io2: Random I/O is expected, but keep queries tuned — poorly indexed queries can multiply IOPS and drive costs higher.
-
Log processing on st1: Batch logs into larger sequential writes. Writing line by line wastes throughput and prevents the disk from reaching its baseline MB/s.
-
Analytics workloads: Use sequential scans where possible; avoid frequent small updates that scatter data.
18. Avoid root volume for heavy I/O
By default, EC2 root volumes are often 8–30 GB gp2 or gp3 SSDs, with baseline performance around 3 IOPS per GB (e.g., a 30 GB gp2 root volume gives just ~90 IOPS). That’s fine for the operating system, but nowhere near enough for databases or analytics.
Running heavy workloads on the root disk leads to bottlenecks and forces you to oversize the root just to get more IOPS — which drives up costs. Keep the root volume small (just big enough for the OS) and attach separate EBS volumes sized and tuned for your application data.
19. Check with AWS Trusted Advisor
What it checks:
-
Unused or unattached EBS volumes
-
Underutilized volumes with low activity
-
Old snapshots stored in S3
Why it matters:
These resources quietly accumulate charges (e.g., unattached gp3 volumes still cost ~$0.08/GB-month). Trusted Advisor highlights them so you can delete or archive and realize immediate savings.
20. Automate encryption on Amazon EBS
Turning on default encryption ensures all new volumes and snapshots are protected automatically, saving time and reducing compliance risk. While AWS doesn’t charge extra for encryption itself, using KMS customer-managed keys can add costs for key usage and API calls — so factor this into your budget.
Checklist:
-
Enable default EBS encryption in the AWS console or via CLI.
-
Choose between AWS-managed keys for simplicity or KMS customer-managed keys (CMKs) if you need control over rotation, access, or audit logs.
-
Verify that encryption settings apply consistently to both new volumes and snapshots across accounts and regions.
-
Review IAM policies to ensure the right teams have access to keys but not broader privileges.
-
Schedule periodic audits to confirm no unencrypted resources are slipping through.
21. Use Multi-Attach for high availability
Multi-Attach is designed for specialized scenarios where uptime is critical — like clustered databases or applications that need immediate failover. By allowing multiple EC2 instances to access the same io1 or io2 volume, it reduces downtime risk and improves resilience.
But it comes at a price: since Multi-Attach only works on provisioned IOPS SSDs, you’re paying for premium storage whether you fully use it or not. For most workloads, that cost outweighs the benefits. For mission-critical systems, however, the trade-off is worth it.
The Bottom Line
Amazon EBS underpins countless workloads on AWS, but without active management it can quietly become one of the most expensive parts of your bill. The strategies in this guide — from picking the right volume types to pruning snapshots and automating policies — show how much room there is to cut waste and align storage costs with actual needs.
The challenge is that optimization isn’t a one-time project. Volumes grow, workloads shift, and snapshots accumulate every day. That’s why visibility and automation are critical. nOps provides both: a single place to see every EBS volume across accounts, identify which ones are driving costs, and take action instantly — whether that’s rightsizing, cleaning up, or automating lifecycle policies.
Schedule a nOps demo, or start your free trial today!
FAQ: How To Reduce EBS Cost
What is the AWS tool for cost optimization?
AWS offers several tools, including Cost Explorer, Trusted Advisor, and Compute Optimizer, to help identify savings opportunities. These provide visibility into spend patterns and efficiency recommendations. For broader automation and advanced FinOps capabilities, many organizations turn to third-party platforms like nOps.
Which one of the following actions may reduce Amazon EBS costs?
You can reduce EBS costs by deleting unused volumes, switching to lower-cost storage classes like gp3 or sc1, and resizing volumes to match actual workload needs. Snapshots can also be used to archive data at lower cost while freeing up primary storage.
How to optimize EBS?
Optimizing EBS typically involves rightsizing volumes, choosing cost-efficient volume types, and cleaning up unused or unattached disks. Monitoring IOPS and throughput helps match performance with workload requirements. Automation tools like nOps can identify idle resources, enforce lifecycle policies, and shift data to cheaper storage tiers.
What is EBS-optimized in AWS?
An EBS-optimized instance provides dedicated bandwidth between EC2 and EBS volumes. This ensures predictable performance by separating storage traffic from other network activity. While it can improve reliability for I/O-intensive workloads, using EBS-optimized instances may increase costs compared to standard configurations.
Last Updated: February 4, 2026, Right Sizing
Tags
Last Updated: February 4, 2026, Right Sizing