Skip to content
Skip to content


The EC2 P family is AWS’s high-performance line of GPU-powered instances built for compute-intensive workloads like machine learning training, large-scale inference, and scientific simulations. These instances are backed by NVIDIA’s most powerful data center GPUs and are designed to deliver maximum throughput and scalability.
Each generation brings significant improvements in GPU architecture, memory bandwidth, and networking. Later generations (P4 and P5) include support for features like Elastic Fabric Adapter (EFA) and GPUDirect RDMA, which reduce latency and improve performance in distributed workloads.
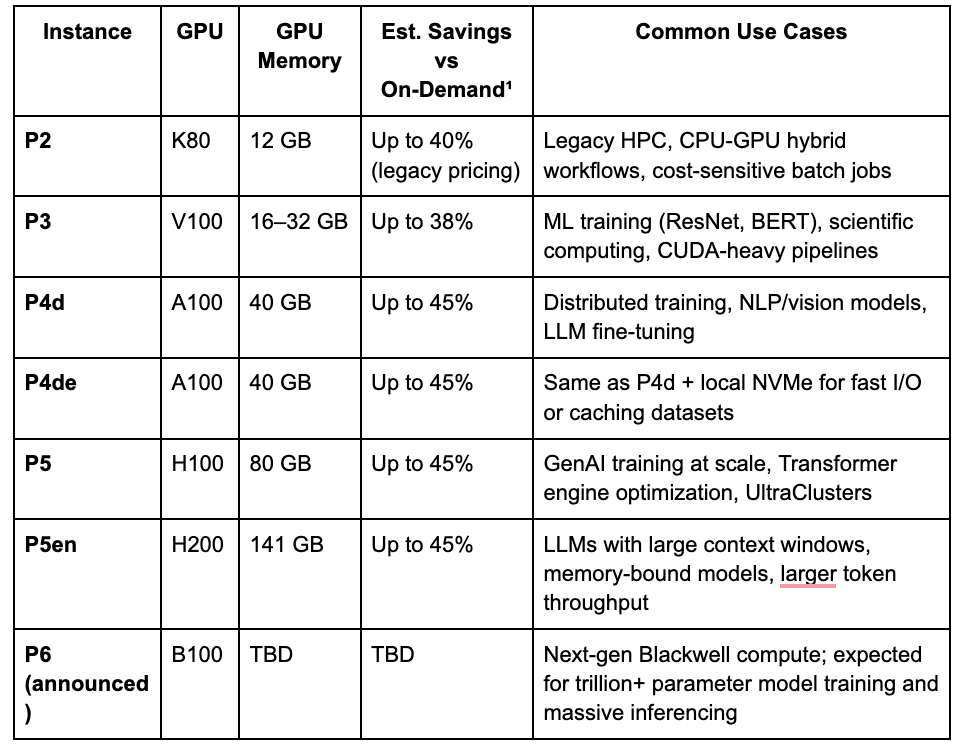
These instances are typically used in clusters for high-throughput training, inference pipelines, and simulation-heavy HPC workloads. If your job is bottlenecked by GPU throughput or memory bandwidth, the P family is likely where you’ll land.
The EC2 G family is AWS’s line of GPU instances designed for graphics rendering, media streaming, and lightweight machine learning inference. Compared to the P family, G instances are optimized for workloads that benefit from GPU acceleration but don’t require the full compute power of high-end data center GPUs.
G instances are built on NVIDIA’s T4, L4, and L40S GPUs, which are more power-efficient and cost-effective than the A100 or H100 chips in the P family. They support virtualization technologies like NVIDIA GRID, making them a strong choice for virtual desktops, game streaming, and 3D visualization.
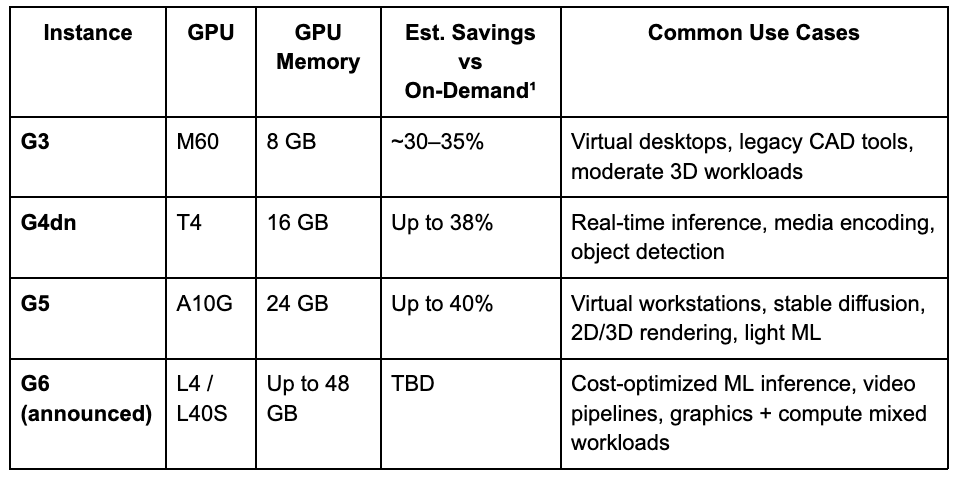
These instances are ideal when you need GPU acceleration without the full cost or scale of the P family. Common use cases include video processing, virtual workstations, graphics-intensive applications, and real-time inference workloads.
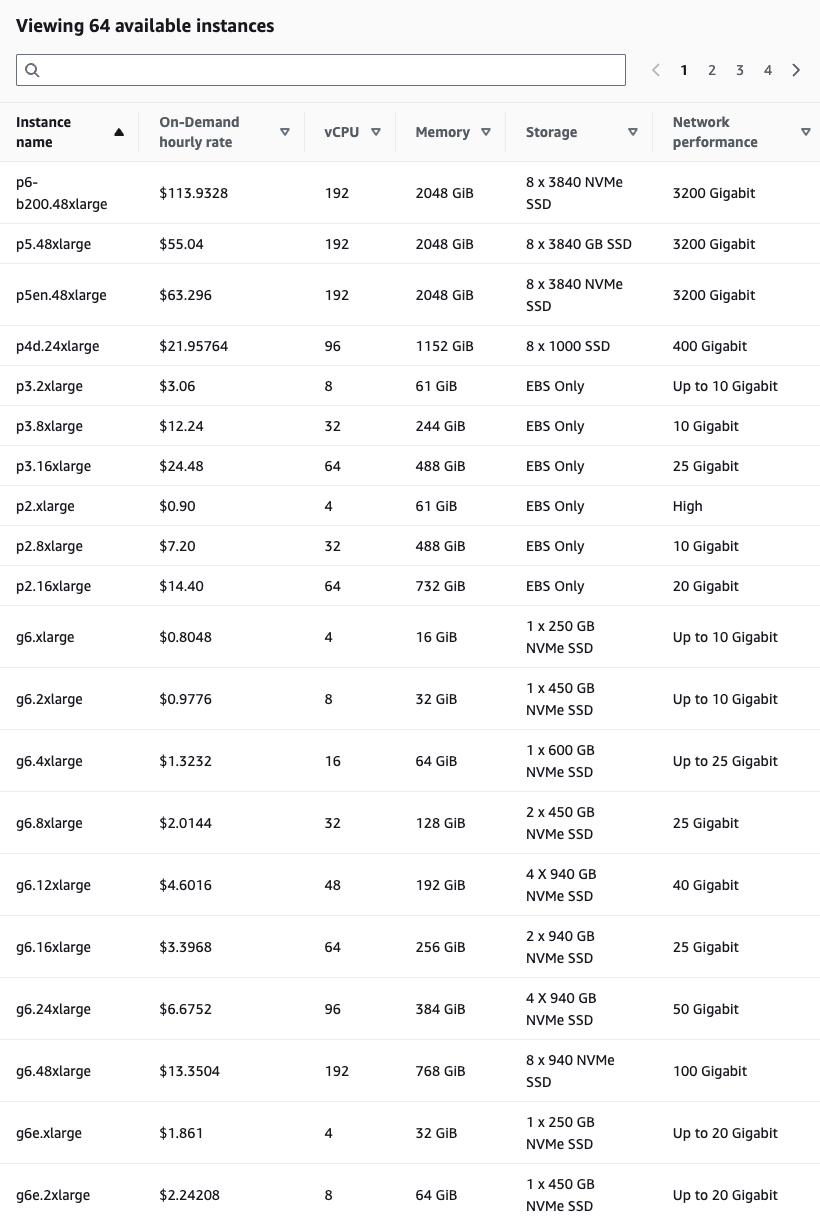
GPU instances on AWS are priced based on a combination of GPU type, instance size, and region. In general, P-family instances are significantly more expensive than G-family instances due to their higher-end GPUs, larger memory footprints, and advanced networking capabilities. That said, their performance per dollar can be favorable for large-scale training and inference—especially when combined with Savings Plans or Spot Instances.
Here’s a screenshot of the most recent p family and g family pricing from the Amazon pricing page.
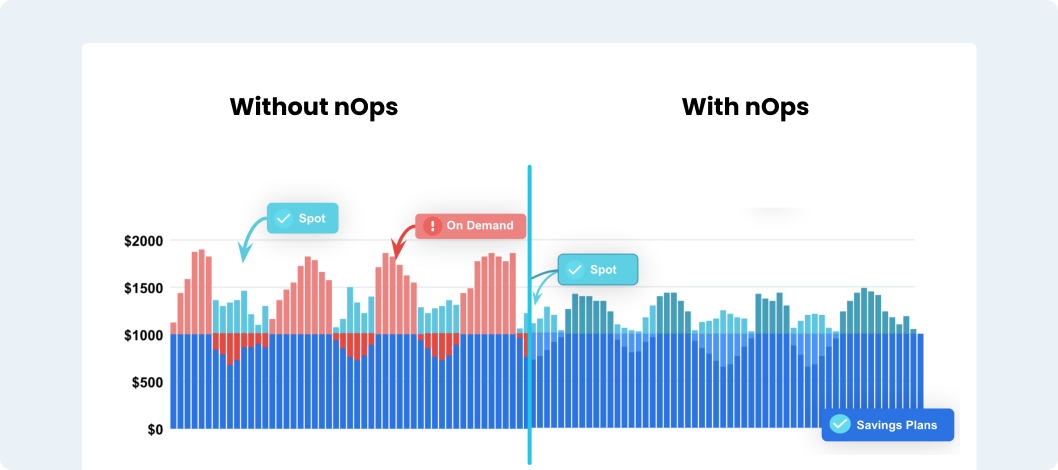
To reduce costs, many teams use Savings Plans, which offer up to 45% off in exchange for a 1- or 3-year commitment. Spot Instances are also available for some P and G instance types, often at steep discounts—but with interruption risk. We’ll cover both strategies in more detail in the cost optimization section.
GPU-backed workloads can quickly become one of the most expensive components of your AWS bill—but there are proven strategies to reduce that cost without sacrificing performance. Here’s how engineering teams can optimize spend when using the EC2 P family.
1. Use Savings Plans for Steady Workloads
If you have long-running training pipelines, model development environments, or predictable batch jobs, EC2 Instance Savings Plans offer the best discount. As of June 2025, AWS provides up to 45% savings on P4 and P5 instances with a 1- or 3-year commitment. This is ideal for foundational workloads that require consistent compute.
2. Leverage Spot Instances for Flexible or Interruptible Jobs
Spot capacity is available for many P-family instances—especially older generations like P3 and P2. These can offer up to 70–90% discounts compared to On-Demand. Use Spot for:
- Preemptible training runs
Experiments and tuning jobs - Non-time-sensitive batch inference
Be sure to configure checkpoints or use managed services (e.g. SageMaker Managed Spot Training) to handle interruptions gracefully.
3. Choose the Right Generation for Your Workload
Not every workload needs a P5. For smaller models or less memory-intensive tasks, older generation instances like P3.8xlarge or P4d.24xlarge may deliver better performance per dollar. Match instance type to:
- Model size and batch size
- Memory bandwidth requirements
- Cost sensitivity vs speed of completion
4. Consolidate Training into Fewer, Larger Jobs
When scaling horizontally, fewer larger instances (e.g. P4d.24xlarge) may be more cost-efficient than many smaller ones. Larger nodes offer NVLink and GPUDirect, which reduce inter-GPU latency and speed up multi-GPU training—cutting overall job duration and total cost.
5. Use nOps to Automate GPU Cost Optimization
nOps Compute Optimization constantly manages the scheduling and scaling of your workloads for the best price and stability, automatically implementing these best practices for you.
- Optimize your RI, SP and Spot automatically for 50%+ savings — Copilot analyzes your organizational usage and market pricing to ensure you’re always on the best options.
- Reliably run business-critical workloads on Spot. Our ML model predicts Spot terminations 60 minutes in advance.
- All-in-one solution — get all the essential cloud cost optimization features (cost allocation, reporting, scheduling, rightsizing, & more)
Copilot is entrusted with over 2 billion dollars of cloud spend. Join our satisfied customers who recently named us #1 in G2’s cloud cost management category by booking a demo today!