 Skip to content
Skip to content


- Blog
- AWS Pricing and Services
- AWS S3 Cost Optimization: Best Practices & Guide
AWS S3 Cost Optimization: Best Practices & Guide
Amazon Simple Storage Service (Amazon S3) is an object storage service. Users of all sizes and industries can store and protect any amount of data for virtually any use case, such as data lakes, cloud-native applications, and mobile apps.
Amazon S3 is one of the most inexpensive, scalable and versatile ways to store your data in the cloud. However, if you’re relying on S3 to store, access and transfer large volumes of data, costs and complexity can quickly escalate — leading to thousands of dollars in unnecessary S3 costs.
If you’re struggling with high or increasing S3 costs, we have compiled a list of best practices we use internally that we hope are helpful to you. By choosing the right storage classes and managing your S3 data efficiently, you can significantly advance your S3 cost optimization efforts. First, let’s quickly dive into the basics.
What are the Amazon Simple Storage Service (S3) Bucket Types?
General Purpose Buckets
Directory Buckets
Table Buckets
What are the Amazon Simple Storage Service (S3) classes?
S3 Express One Zone
Amazon’s newest storage class, Express One Zone offers high-performance in a single Availability Zone purpose-built to deliver single-digit millisecond data access. With lower request costs than S3 Standard and 10x performance, Express One Zone is a great choice for short lived data that requires high throughput and low latency, which can then be *tiered* out of Express One Zone to more cost efficient classes, or deleted. Express One Zone is still a relatively new storage class, and we should expect continued improvements to the tooling that allows for objects to be transitioned in and out of Express One Zone.
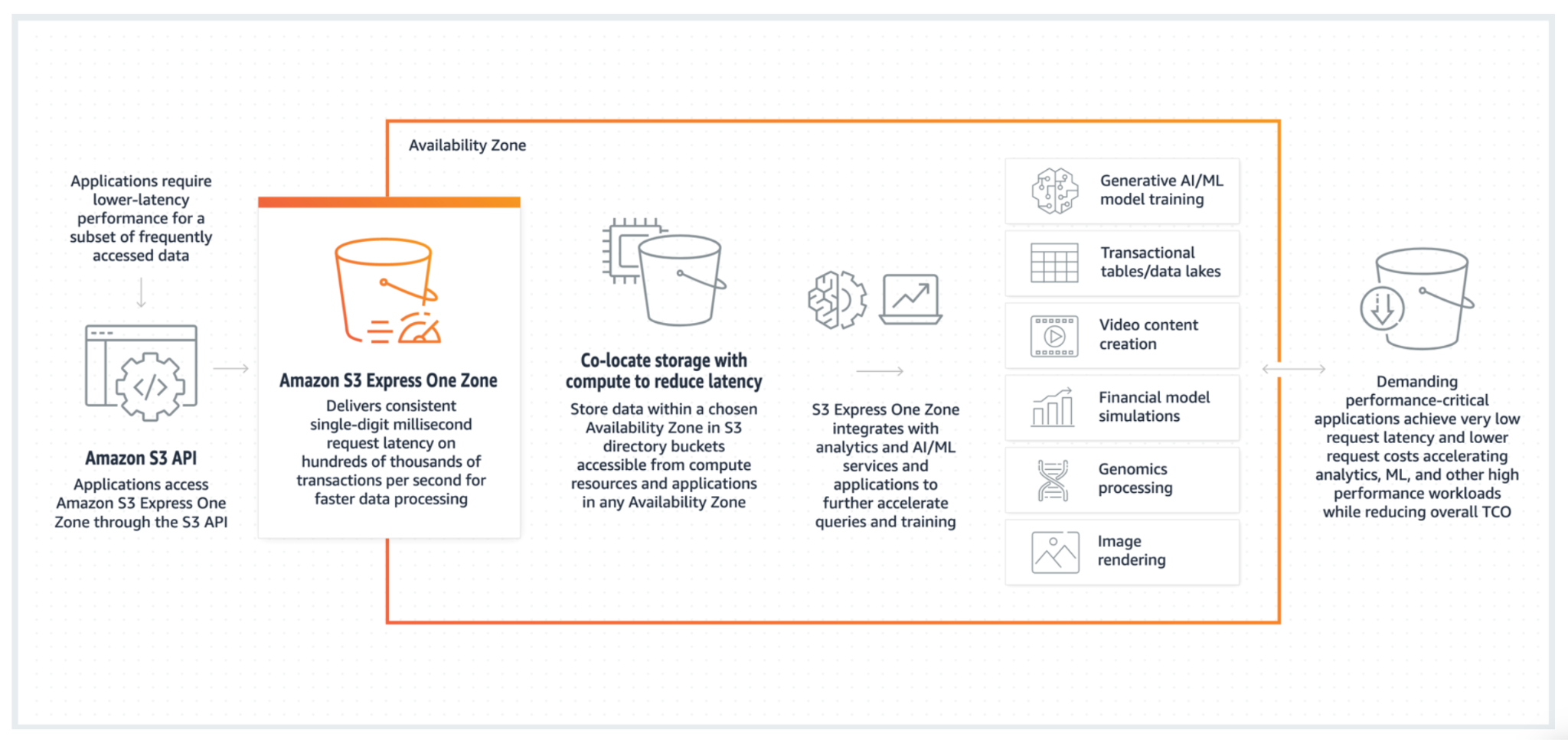
S3 Standard
This class is designed for frequently accessed data and provides high durability, performance and availability (data is stored in a minimum of three Availability Zones). Costs are higher for S3 Standard than for other S3 storage classes (Excluding Express One Zone). S3 Standard is best suited for general-purpose storage for a range of use cases requiring frequent access, such as websites, content distribution or data lake.
S3 Standard-Infrequent Access
S3 One Zone-Infrequent Access
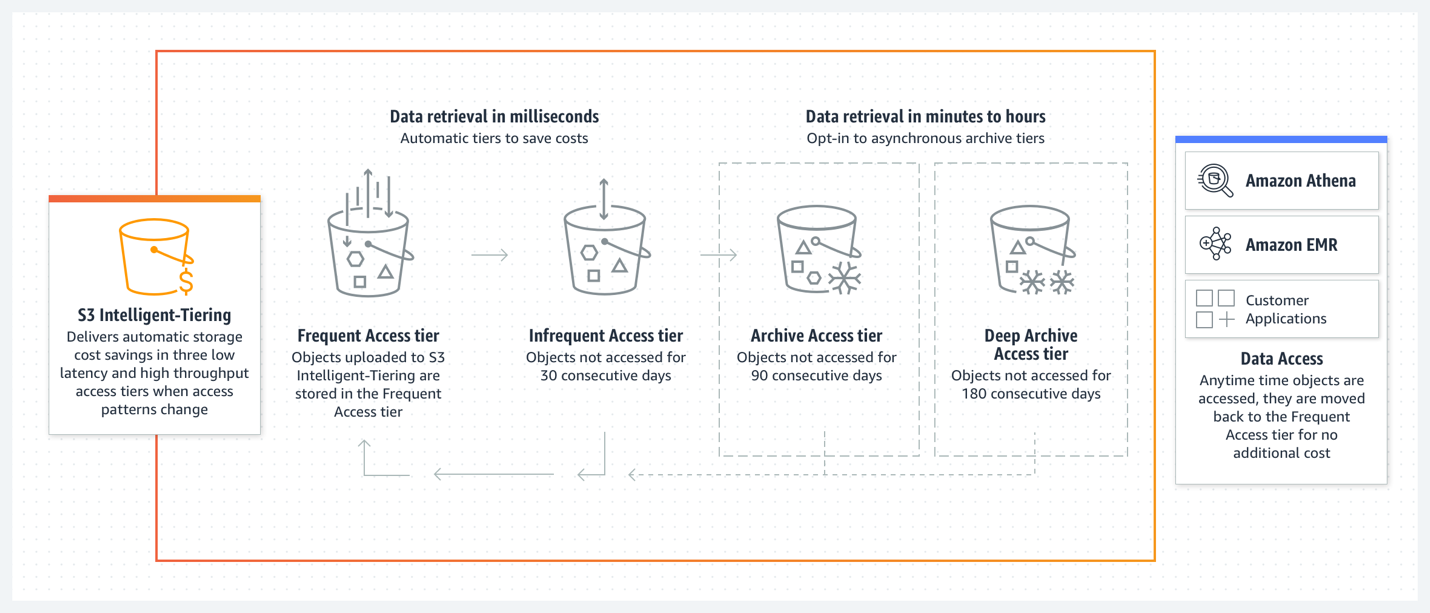
S3 Intelligent-Tiering
Managing the lifecycle of your S3 objects can be challenging, and expensive if your access patterns are unknown. Intelligent-Tiering manages the lifecycle of your objects automatically, for a small monitoring fee, and a minimum storage size of >128KB to be considered for tiering.
Intelligent-Tiering can be configured on the bucket level using a lifecycle policy, however, the most efficient way to get your objects into Intelligent-Tiering is to do so on object creation. Once your data has made its way into Intelligent-Tiering, your objects will move between Frequent Access (same price as S3 Standard), Infrequent Access (same price as Standard-IA), and Archive Instance Access (same price as Glacier Instant Retrieval). This offers significant cost savings up to 82% with no additional effort.
If you’re looking for additional savings, there are two more tiers which can save you further, but your platform must be able to withstand waiting for the data to be retrieved.
S3 Glacier Instant Retrieval
Matching the cost per GB of the lowest default tier within Intelligent Tiering, Glacier Instant Retrieval can put you at a unique advantage over other tiers if you’re accessing the data infrequently, do not want to wait for it to tier down within Intelligent Tiering, and without the monitoring fees. It offers the lowest storage cost for long-lived, rarely accessed data that requires millisecond retrieval times. This tier is suitable for storing long-term secondary backups and older data that might still need to be accessed quickly, such as certain compliance records or seldom-used digital access, and is planned to be stored for at least 90 days.
S3 Glacier Flexible Retrieval
Aimed at data archiving, and 10% less expensive than Glacier Instant Retrieval, this class provides low-cost storage with retrieval times ranging from 1 minute to 12 hours. It is well-suited for long-lived archives, for which retrieval delays are acceptable, and stored for at least 90 days.
S3 Glacier Deep Archive
This is the most cost-effective storage option for long-term archiving and digital preservation, where data retrieval times of 12 hours are acceptable. It is designed for long-term data archiving that is accessed once or twice a year, and planned to be stored for 180 days or longer.
S3 on Outposts Storage Classes
How does S3 pricing work?
Amazon S3 uses a pay-as-you-go pricing model, without any upfront payment or commitment required. S3’s pricing is usage-based, so you pay for the resource that you’ve used.
AWS offers a free tier to new AWS customers, involving 5GB of Amazon S3 storage in the S3 Standard storage class; 20,000 GET Requests; 2,000 PUT, COPY, POST, or LIST Requests; and 100 GB of Data Transfer Out each month.
After that, here are the main variables that are taken into account when calculating S3 pricing.
Storage Costs

Request and Data Retrieval Costs

Data Transfer Costs
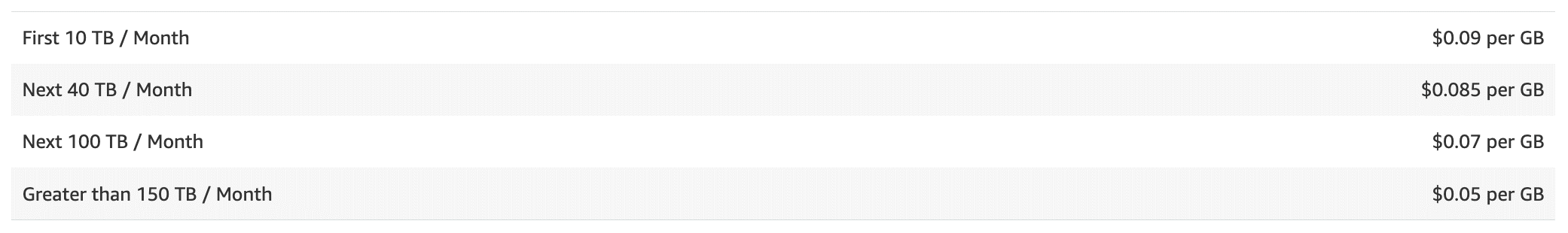
Additional Features and Costs
Amazon S3 pricing also includes charges for management and analytics tools, data replication across regions or within the same region, security and access tools, and costs associated with data transformation and querying through services like Amazon S3 Select (Discontinued for new customers as of July 25, 2024).
Furthermore, using Amazon S3 Object Lambda results in charges based on the data processed, and costs can vary significantly with server location and data transfer destinations, particularly when transferring data across different AWS regions
What are the top 10 best practices for S3 cost optimization?
1. Use Lifecycle Policies
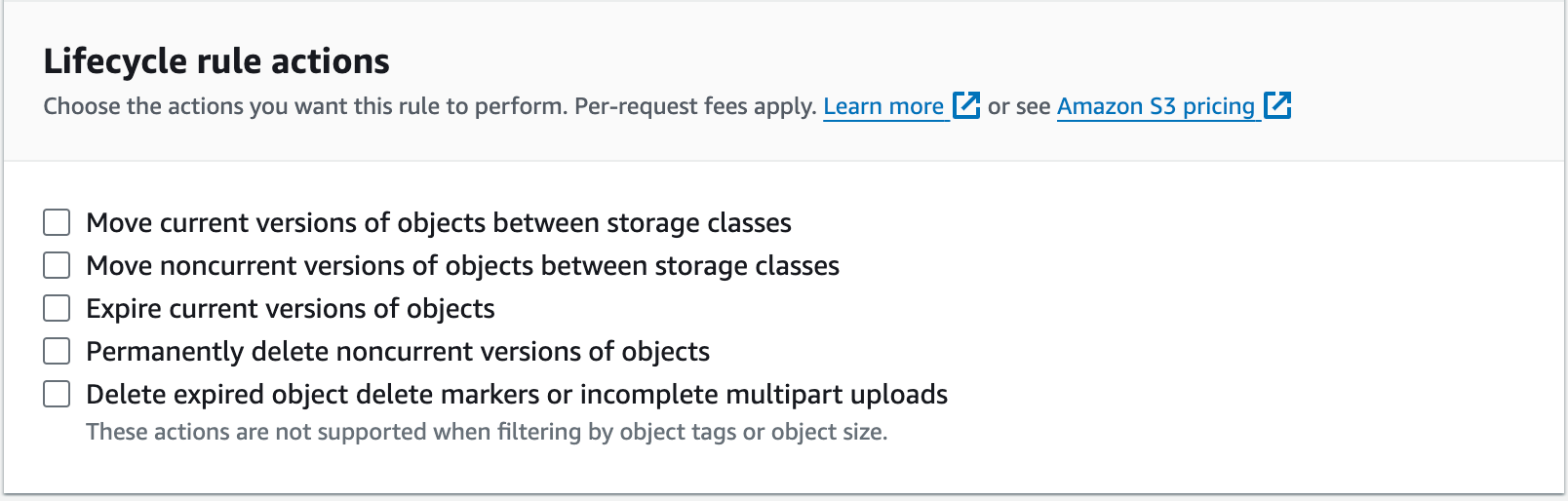
Through the AWS Management Console within the S3 service, you can enable lifecycle rules on individual buckets. You can also accomplish this using the AWS CLI or through whichever IaC tool you prefer.
Some common use cases would be configuring a lifecycle rule that handles expired object delete markers and deleting noncurrent versions if you have enabled versioning on your bucket. Another common use case would be transitioning your objects from S3 Standard into Standard IA or Glacier Instant Retrieval after X number of days.
2. Delete Unused Data
3. Compress Data Before You Send to S3
You incur Amazon S3 charges based on the amount of data you store and transfer. By compressing data before sending it to Amazon S3, you can reduce both storage and transfer costs.
Several effective compression methods can help optimize storage costs and efficiency. Algorithms like GZIP and BZIP2 are widely used for text data, offering good compression ratios and compatibility. LZMA provides even higher compression rates, though it typically requires more processing power. For binary data or quick compression needs, LZ4 is an excellent choice due to its very fast compression and decompression speeds.
Additionally, using file formats like Parquet, which supports various compression codecs, can further optimize storage for complex datasets by enabling efficient columnar data querying and storage.
4. Choose the right AWS Region and Limit Data Transfers
When configuring your S3 buckets, it’s important to consider which region your bucket will live in. Although S3 is often referred to as a global service, its buckets are tied to a specific region, and that region can have additional cost implications. For example, it is currently 4.16% more expensive to store data in S3 Standard in eu-west-2 than us-east-1.
Another commonly overlooked source of data transfer costs is accessing content from your bucket over the public internet. To minimize expenses, consider how your objects are accessed and use AWS VPC Gateway Endpoints for S3 whenever possible.
AWS Cloud Cost Allocation: The Complete Guide

5. Consolidate and Aggregate Data
Consolidating and aggregating data before storing it on S3 can lead to significant cost savings, especially for use cases involving analytics and data processing.
By combining smaller files into larger ones and aggregating similar data types, you can optimize storage utilization and reduce the number of requests made to S3, which in turn minimizes costs associated with PUT, GET, and LIST operations. Additionally, if you plan to transition this data to other classes using lifecycle rules, you’ll be eliminating additional lifecycle transition fees.
Some examples include batching small files (as fewer, larger files reduces overhead and costs) and aggregating data at the source before uploading (for example, if you’re collecting log data, summarize or filter it prior to storage).
6. Monitor and Analyze Usage with S3 Storage Lens & Storage Class Analysis
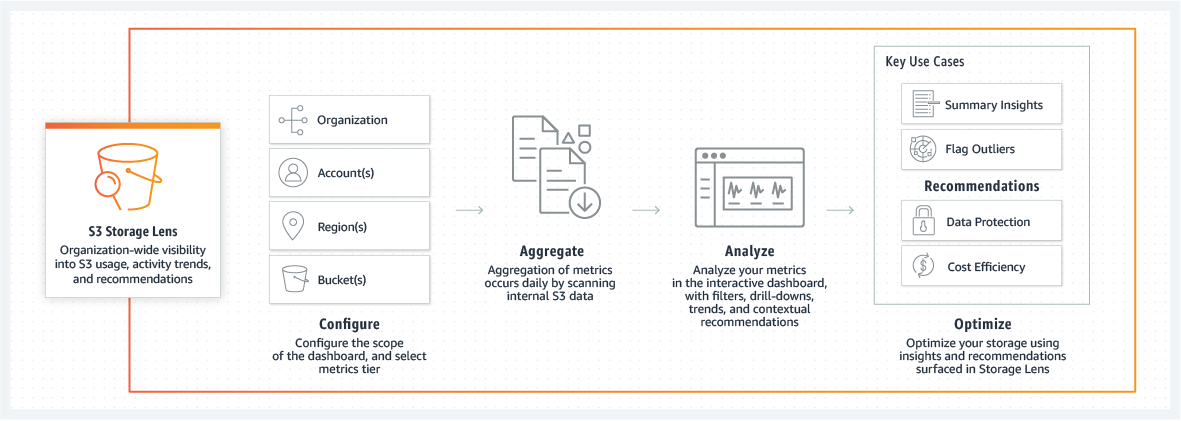
Amazon S3 Storage Lens is a storage analytics tool that helps you visualize and manage your storage usage and activity across your S3 objects. With its dashboard and metrics, you can gain insights into operational and cost efficiencies within your S3 environment. You can use S3 Storage lens to:
Identify cost drivers: S3 Storage Lens provides metrics on data usage patterns, enabling you to pinpoint high-cost areas. For example, you can identify buckets where data retrieval is frequent and costs are high, or find buckets with stale data that could be moved to a cheaper storage class or deleted.
Optimize storage distribution: The dashboard allows you to see how data is distributed across different storage classes. You might find opportunities to shift data from S3 Standard to Infrequent Access tiers if the access patterns support such a move, reducing costs significantly.
View metrics on replication and data protection, helping ensure you’re not overspending on redundancy for non-critical data.
Monitor access patterns: By examining access patterns, you can adjust your storage strategy to better align with actual usage. If certain data is accessed infrequently, you can automate the transfer of this data to lower-cost storage classes using lifecycle policies.
Set Customizable metrics and alerts: You can configure Storage Lens to send alerts when certain thresholds are met, such as an unexpected increase in PUT or GET requests, which could indicate an inefficiency or a potential issue in your S3 usage pattern.
Advanced analytics using Storage Class Analysis: If you’re looking for further insight into your usage patterns, you can enable Storage Class Analysis, which helps you identify how much of your data in specific storage classes you are accessing. This is very helpful when determining whether or not to transition data into a tier that has a minimum storage duration, or significantly increased retrieval fee.
7. Use Requestor Pays
Enable the Requestor Pays option to shift data transfer and request costs to the user accessing your Amazon S3 bucket data. This feature is particularly useful if you host large datasets publicly and want to avoid bearing the cost of data egress.
For example, you might use Requester Pays buckets when making available large datasets, such as zip code directories, reference data, geospatial information, or web crawling data. When enabled, anyone accessing your data will incur the charges for requests and data transfer out of Amazon S3, while you continue to pay for the storage costs. Requestor Pays can be set on a per-bucket basis.
8. Set up IAM to limit access
Set up Identity and Access Management (IAM) to limit access to your Amazon S3 resources effectively. By configuring IAM policies, you can control who can access your Amazon S3 data and what actions they can perform. This is crucial for minimizing unnecessary data access, which can lead to additional costs, especially with operations like PUT and GET requests.
Implement least privilege access by granting permissions only to the extent necessary for users to perform their assigned tasks. You can utilize IAM roles and policies to specify allowed actions on specific buckets or objects. For instance, you might allow a group of users to only read data from a particular Amazon S3 bucket, while administrative access could be restricted to IT staff.
9. Partition your data before querying it
By partitioning data into segments based on specific keys such as date, time, or other relevant attributes, you can enable query services like Amazon Athena or Amazon Redshift Spectrum to scan only pertinent parts of your data.
You can start by defining partition keys that align with common query filters, such as time-based keys (year, month, day) or geographic identifiers (country, region). This approach ensures queries are more efficient, accessing only the necessary data for analysis.
Additionally, consider implementing a folder structure in your Amazon S3 buckets that mirrors your partitioning strategy, facilitating direct and fast access to subsets of data. The partition management process can be automated with AWS Glue or custom scripts to maintain and update partitions as new data is ingested, keeping your storage organized and cost-effective with less manual effort.
Understand and optimize your cloud costs with nOps
Whether you’re looking to optimize just your S3 costs or your entire cloud bill, nOps can help. It gives you complete cost visibility and intelligence across your entire AWS infrastructure. Analyze S3 costs by product, feature, team, deployment, environment, or any other dimension.
If your AWS bill is a big mystery, you’re not alone. nOps makes it easy to understand and allocate 100% of your AWS bill, even fixing mistagged and untagged resources for you.
nOps also offers a suite of ML-powered cost optimization features that help cloud users reduce their costs by up to 50% on autopilot, including:
Compute Copilot: automatically selects the optimal compute resource at the most cost-effective price in real time for you — also makes it easy to save with Spot discounts
Commitment Management: automatic life-cycle management of your EC2/RDS/EKS commitments with risk-free guarantee
Essentials: set of easy-apply cloud optimization features including EC2 and ASG rightsizing, resource scheduling, idle instance removal, storage optimization, and gp2 to gp3 migration
nOps processes over 2 billion dollars in cloud spend and was recently named #1 in G2’s cloud cost management category.
You can book a demo to find out how nOps can help you start saving today.
Last Updated: May 20, 2025, AWS Pricing and Services
Last Updated: May 20, 2025, AWS Pricing and Services
