Efficiently Packing and Sizing your EKS Nodes: Bin Packing & More
Efficient resource utilization in a Kubernetes cluster is vital for reducing costs, improving performance and scalability, minimizing resource contention, supporting sustainable practices, and ensuring reliability.
In this blog series, we will take a structured approach to optimizing Kubernetes, from the basics to advanced:
- Part 1: Intro to Container Rightsizing: adjusting resource requests and limits to match actual usage patterns
- Part 2: Horizontal vs. Vertical Scaling: HPA, VPA & Beyond
- Part 3: Bin Packing & Beyond: the changing landscape of efficiently packing and sizing your EKS nodes.
- Part 4: Deep Dive into VPA Modes
- Part 5: Effective Node Utilization and Reconsideration
Let’s dive into part 3, centered on binpacking and the various strategies used to efficiently size and pack your EKS nodes.
Understanding the state of Kubernetes & its native packing strategies and configurations
Let’s start by briefly discussing how Kubernetes works natively and some of the challenges involved in effective node management, before diving into some solutions and strategies for more effective node packing and sizing in today’s landscape.
Kubernetes has become the dominant container orchestration tool, and it’s only projected to grow. However, Kubernetes resource management can be complex. In the context of Kubernetes and EKS, the primary challenge is ensuring that the allocated resources (CPU, memory, storage) match the actual needs of dynamic workloads running on the cluster. Mismanagement can lead to overprovisioning and waste, conversely underprovisioning and performance degradation.
Kubernetes’ built-in strategy focuses on scheduling pods based on resource requests, affinities, and other constraints to ensure availability and performance. While it does consider resource utilization when making decisions, it prioritizes other factors.
Kubernetes primarily relies on the `requests` field in pod specifications. This specifies the minimum resources a pod needs to function. The scheduler uses node predicates to filter out unsuitable nodes based on conditions like available resources, node selectors, and taints. Shortly defined, `predicates` are a set of pre-registered functions in K8s, the scheduler invoking these functions to check if a pod is eligible to be allocated onto a node. The scheduler employs prioritization functions to rank eligible nodes. Factors like resource availability, node load, and pod affinities influence this ranking. The prioritization logic can shortly be summarized in 2 main phases, Filtering and Scoring:
Each priority function assigns a score to each eligible node. In the filtering phase, Kubernetes eliminates nodes that are not suitable for running a pod. For example, if a pod requests 4 GB of memory, Kubernetes will filter out nodes that have less than 4 GB of available memory. In the scoring phase, Kubernetes assigns a score to each remaining node based on various criteria, such as resource utilization, pod affinity, and node affinity. The node with the best score is selected as the best fit for the pod. The filtering and scoring phases are implemented by two types of components: predicates and priorities. Predicates are boolean functions that return true or false for each node. They are used to implement the filtering logic. Priorities are numeric functions that return a score between 0 and 10 for each node. They are used to implement the scoring logic. The scheduler selects the highest-ranked node to place the pod.
Why optimally managing nodes can be challenging
Some of the practical problems you may encounter include:
- Challenges of dynamic workloads: static resource requests and limits may not accurately reflect the real-time resource needs of running containers, leading to either resource wastage or insufficient provisioning.
- Resource fragmentation: Kubernetes’ scheduler may place pods on nodes in a way that leads to resource fragmentation. This happens when small amounts of unused resources across nodes accumulate, which could otherwise be used to accommodate additional workloads if they were more compactly arranged.
- Autoscaling complexities: EKS provides cluster autoscaling capabilities that adjust the number of nodes based on the cluster’s resource demands. However, configuring these autoscalers optimally requires deep understanding and continuous tuning, as the default settings might not fit all workload patterns. Deciding between horizontal and vertical scaling add further complexities (see part #2).
- Dependency on Proper Configuration of resource requests, limits, and autoscaling parameters. Misconfigurations can lead to significant inefficiencies and potential application performance issues.
- Cost Management: AWS offers over 750 instance types with different pricing models. Choosing the wrong instance type or mismanaging reserved instances and Spot instances can significantly impact your cloud costs.
Efficiently packing and sizing your EKS nodes: a practical guide
In this practical guide, we’ll discuss advanced strategies for efficiently packing and sizing your EKS nodes. While HPA and VPA play a crucial role, we can enhance the process by fitting containers with different resource demands onto compute nodes with limited CPU, memory, and other resources in addressing the unique challenges of EKS environments.
Step 1: Collecting the right metrics
Like all cloud optimizations, binpacking starts by collecting the right data. When it comes to EKS resource management, here are the most important metrics to consider:
Concept | Definition | Key Metric(s) |
CPU Utilization | Measure the CPU usage across your nodes to ensure you’re not over or under-utilizing your resources | CPU usage percentage |
Memory Utilization | Monitor memory usage to avoid out-of-memory (OOM) errors and ensure efficient memory allocation | Memory usage percentage |
Pod Resource Requests and Limits | Track the resource requests and limits set for your pods to ensure they align with the actual usage patterns | CPU and memory requests vs. limits |
Node Resource Allocation | Check how resources are allocated across nodes to detect any imbalances | Resource allocation per node |
Pod Distribution | Analyze how pods are distributed across your nodes to identify any inefficiencies in scheduling | Number of pods per node |
Cluster Autoscaler metrics | Review metrics related to the cluster autoscaler to understand scaling decisions and their impact | Scale-up and scale-down events Pending pods due to insufficient resources |
There are several ways to collect metrics. Depending on your needs, you can choose and even combine some of common approaches below:
Platform | Primary use | Configuration |
Prometheus | Prometheus is a powerful monitoring and alerting toolkit that can scrape detailed, real-time metrics from Kubernetes components such as nodes, pods, and services. You can set up alerts to notify you when critical metrics like CPU usage, memory usage, or request latency exceed predefined thresholds. | Deploy Prometheus in your EKS cluster and configure it to scrape metrics from the Kubernetes API server, Kubelets, and application endpoints. |
Grafana | Use Grafana to visualize the metrics collected by Prometheus. It offers rich dashboards and alerting capabilities. | Connect Grafana to your Prometheus instance and set up dashboards for CPU, memory, pod distribution, and autoscaler metrics. |
AWS CloudWatch | AWS-native tool for monitoring and observability for AWS resources, including EKS. CloudWatch can collect and monitor logs and metrics from your EKS cluster, including application logs, infrastructure logs, and custom metrics. Set alarms to trigger actions such as scaling instances or sending notifications when certain conditions are met. | Enable CloudWatch Container Insights to collect and visualize metrics from your EKS cluster. |
Kubecost | Cost management and monitoring tool for Kubernetes resources. Provides visibility into the cost of running Kubernetes workloads by monitoring resource usage and attributing costs to specific namespaces, services, or labels. This helps in identifying inefficiencies / optimizing spend. | Deploy Kubecost in your EKS cluster and integrate it with Prometheus to collect cost metrics. |
OpenCost | Open-source tool that provides real-time cost monitoring and visibility into your Kubernetes clusters. | Deploy OpenCost in your EKS cluster to track and manage resource costs. |
Once we have the metrics, it’s a matter of making algorithmic decisions.
There are various strategies and approaches you can employ to optimize your EKS node usage. The key is to analyze the collected data to make informed decisions about resource allocation, node sizing, and workload distribution. Some approaches include binpacking Algorithms, Machine Learning Models (TensorFlow, Pytorch), Heuristic algorithms, Cost Optimization Algorithms (Major Cloud Providers support this), CA (Kubernetes CA), Workload Profiling and Right-Sizing, Pod Affinity and Anti-Affinity Rules (Scheduling eviction with pod to node assignment) and many more.
For today, we’ll be diving deeper into the key topic of binpacking, why it’s key, how to do it, and how new technologies like Karpenter disrupt the traditional binpacking problem.
Related Content
The Ultimate Guide to Karpenter
Maximizing efficiency, stability, and cost savings in Kubernetes clusters
Download Now
Step 2: Understand binpacking strategies
Binpacking, in the context of Kubernetes, involves placing containers (pods) into nodes in a way that optimizes resource usage and minimizes costs. By arranging pods in such a way that they make the best possible use of the available CPU, memory, and other resources on each node, bin packing helps prevent both the waste of resources and the overloading of any single node — for better performance at lower costs
Let’s take a quick look at the built-in features provided by Kubernetes to implement binpacking strategies:
Resource Requests and Limits | Specify the resource requirements of your pods. The scheduler considers these requests when placing pods on nodes with sufficient resources |
Pod Affinity and Anti-Affinity | Specify pod placement based on the proximity to other pods. Affinity rules attract pods to nodes where specific pods are already running, enhancing locality for related tasks. Anti-affinity ensures pods are spread out. |
Pod Topology Spread Constraints | Distribute pods across different failure zones or node pools to enhance cluster resilience |
Again, these built-in features have limitations; custom bin packing solutions can further enhance the efficiency of your Kubernetes clusters. Here are some common bin packing strategies used in Kubernetes alongside use cases and examples:
- First Fit — Places each pod in the first node that has enough remaining capacity. Although this is the fastest and simplest, it may lead to suboptimal packing.
- Best Fit — Places each pod in the node that leaves the least remaining capacity after the pod is placed. Bigger complexity but far better than the First Fit strategy.
- Best Fit Decreasing — The most complex strategy but generally provides the best results, as it sorts all pods in decreasing order of size and then applies the Best Fit algorithm.
Step 3: Practical steps for binpacking
Let’s talk about the specific actions needed to implement a binpacking strategy.
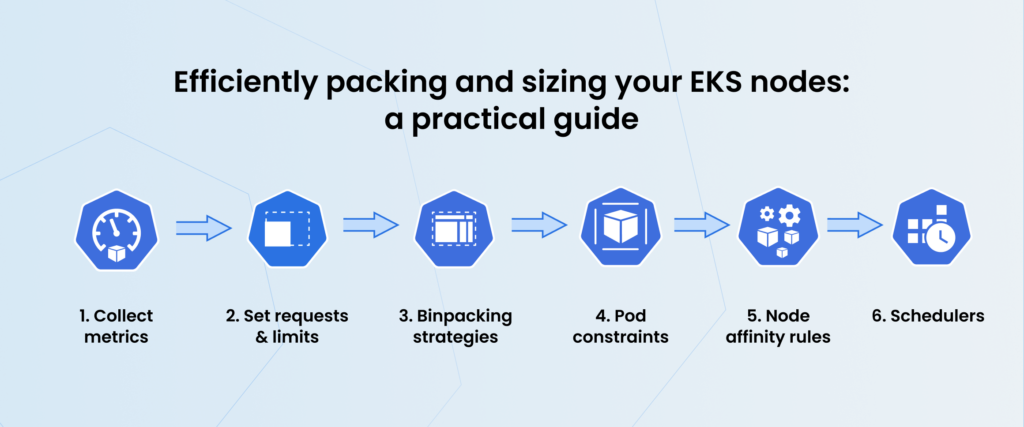
PREREQUISITE Steps
- Analyze collected metrics relevant to determining nodes/pods sizes and placement within the cluster.
- Set accurate requests and limits to help ensure that each pod is allocated the right amount of resources without overprovisioning or underprovisioning.
- Determine which binpacking approach to use.
Key Considerations for determining which binpacking approach to use:
Analyze the Workload Characteristics: Understand the nature of your workloads: Are they CPU-intensive, memory-intensive, or a mix of both? Do they have specific affinity or anti-affinity requirements? If you have many small, short-lived pods, a simpler algorithm like First Fit might be sufficient. For more complex, long-running workloads, Best Fit Decreasing could be more appropriate.
Evaluate the Cluster Configuration: Consider the current configuration of your cluster, including the types of nodes available, their capacities, and any existing constraints. If your cluster has a wide variety of node types and sizes, Best Fit or Best Fit Decreasing can help make the most efficient use of these resources.
Cost Considerations: Factor in cost considerations, especially if using different types of instances (e.g., on-demand vs. spot instances). Prioritize placing pods on spot instances first, using a heuristic approach to balance cost savings and availability. (See the nOps Karpenter approach).
Scalability and Performance: Determine how the algorithm will scale with the number of pods and nodes. More complex algorithms like Best Fit Decreasing may provide better packing but at the cost of higher computational overhead. For large-scale clusters, consider using heuristic-based approaches that provide a balance between efficiency and computational complexity.
BINPACKING steps:
- Incorporate Constraints to influence the placement of pods based on specific requirements.
- Node affinity rules help ensure that pods are scheduled on nodes with particular attributes, while pod affinity and anti-affinity rules manage the placement of pods relative to each other to meet high availability and performance needs.
- Schedulers (we recommend Karpenter — see step 4): Karpenter’s model of layered constraints, including NodePools, allows you to define specific constraints for nodes. This ensures that the resources needed are available and appropriately allocated to your pods (more about Karpenter NodePools). We’ll explore this point in detail in Step 4 of this guide.
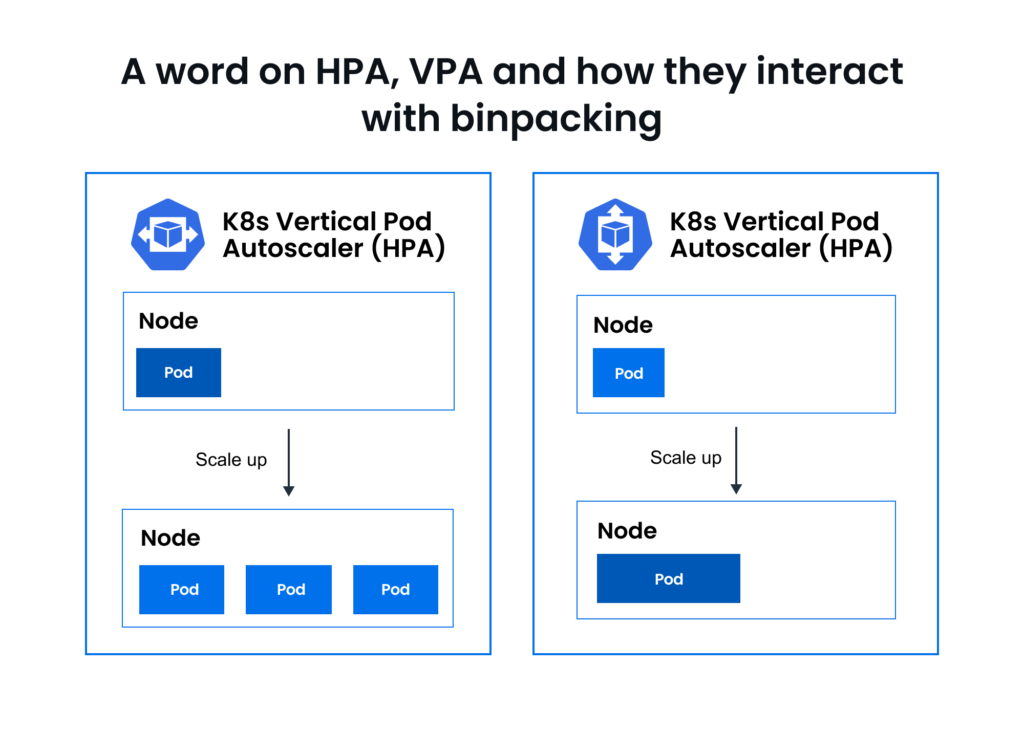
HPA focuses on maintaining performance by scaling out pods based on workload demands, which can lead to fluctuating resource requirements. This dynamic scaling can disrupt bin packing strategies, which are designed to tightly pack static workloads into nodes to reduce resource fragmentation and node count. Moreover, if bin packing places pods too densely, it might leave insufficient resources for HPA to scale up efficiently during spikes in demand, leading to performance bottlenecks. Conversely, HPA might scale up rapidly in response to a spike, resulting in suboptimal node usage and increased costs if the new pods are scattered across underutilized nodes rather than being packed efficiently.
VPA adjusts the CPU and memory allocations of pods to match the current demands more closely, scaling the resources allocated to each pod vertically. In contrast, bin packing aims to place pods in a way that maximizes node utilization, often by fitting smaller pods into gaps left by larger ones. VPA (Vertical Pod Autoscaler) doesn’t specifically consider the overall efficiency of pod placement or the constraints such as Pod Disruption Budgets (PDBs) or other annotations that might hinder optimization during its operation. This oversight can result in less-than-optimal resource utilization because VPA’s primary focus is adjusting the resource requests of pods based on their usage without considering how these adjustments fit into the broader node packing strategy. For example, VPA can disrupt existing bin packing arrangements by increasing the resource requests of pods, potentially leading to a need for these pods to be rescheduled onto different nodes with more available resources.
Proper coordinating strategies and configuration of Kubernetes schedulers like Karpenter can help binpacking work more harmoniously with HPA and/or VPA. For example, using scheduler features like pod priority and preemption could help manage the placement and resource allocation more dynamically when used alongside HPA and VPA. Advanced scheduling techniques such as affinity and anti-affinity rules, topology spread constraints, and custom scheduler plugins that can help in achieving more granular control over pod placement in accordance with both HPA and VPA adjustments.We’ll discuss these features and how to use them later in this guide.
Step 4: Understand Schedulers and how to use them.
Schedulers play a crucial role in the process of bin packing in Kubernetes and similar systems, as they are responsible for deciding where and how to place workloads—essentially, they are the core component that implements bin packing logic.
The problems with Cluster Autoscaling binpacking and why Karpenter is gamechanging
Bin packing issues with the AWS-native autoscaler (Cluster Autoscaler) in Kubernetes primarily stem from its reactive nature. Cluster Autoscaler adjusts the number of nodes based on current demands and predefined thresholds, which can lead to suboptimal bin packing. This inefficiency arises because it focuses on node-level scaling rather than individual pod placements, often resulting in underutilized nodes or delayed scaling decisions that temporarily impact performance.
Karpenter, on the other hand, addresses these issues by employing a more proactive and fine-grained approach to node management and pod placement. Unlike Cluster Autoscaler, Karpenter continuously evaluates the entire cluster to make decisions about scaling and pod distribution. Karpenter dynamically adjusts the number and type of nodes in your Kubernetes cluster based on the current workload requirements. This real-time responsiveness ensures that resources are allocated efficiently, minimizing both over-provisioning and under-provisioning.
Traditional bin packing algorithms statically assign workloads to nodes, often leading to inefficiencies as they cannot adapt quickly to changing demands. Karpenter, on the other hand, continuously monitors the cluster and makes adjustments on-the-fly, providing a more adaptive and efficient resource management solution.
- Karpenter’s layered constraints model integrates constraints from the cloud provider, cluster administrator, and pod specifications. This multi-layered approach allows for precise control over node selection and pod placement.
- When it comes to costs, Karpenter supports diverse instance types and purchase options, such as Spot instances and Reserved Instances, allowing for cost-effective scaling. By leveraging these cost-saving opportunities, Karpenter helps reduce the overall operational expenses of running Kubernetes clusters.
Other notable advantages when it comes to the usage of Karpenter’s workload scheduling are the seamless integration with the Kubernetes API, making everything easier to manage and deploy and the Enhanced Flexibility and Scalability, which is Karpenter’s ability to quickly scale nodes up or down in response to workload changes ensures that your cluster is always running optimally. This flexibility is crucial for handling unpredictable and dynamic workloads common in modern cloud-native environments.
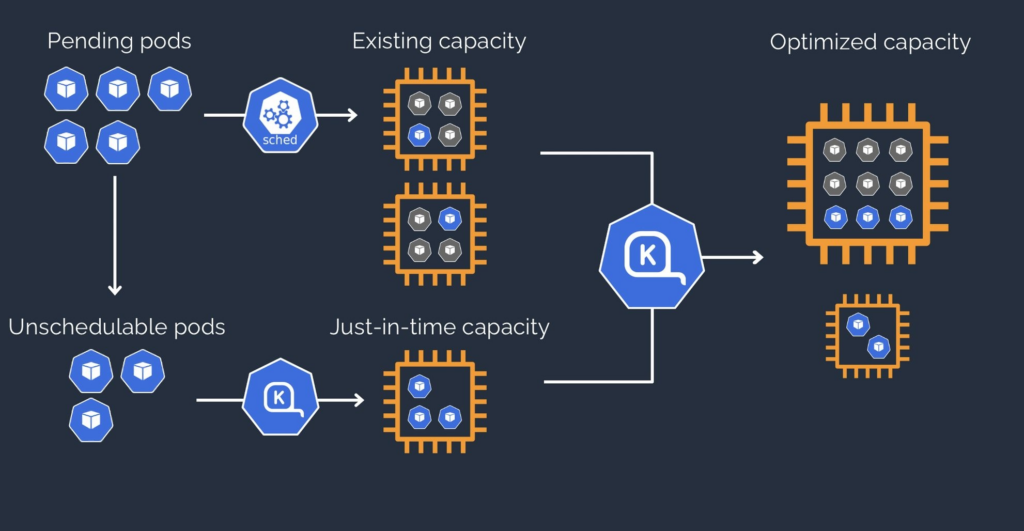
Karpenter stands out as the most advanced node scheduling technology on the market, particularly when your pods lack specific requirements for node placement. By leveraging the full range of available cloud provider resources, Karpenter can dynamically select nodes to meet the needs of your workloads. However, you can also utilize Karpenter’s model of layered constraints to ensure that the precise type and amount of resources required are available to your pods. This capability is especially useful for scenarios where specific conditions must be met for pod placement.
Let’s discuss how to use Karpenter for optimal pod placement based on your specific criteria.
Use Karpenter’s Layered Constraints
In managing Kubernetes clusters, ensuring that your pods are running efficiently and effectively is crucial. This is where the concept of layered constraints get very handy. But why should you use layered constraints and how can they help you? There are several reasons you might need to constrain where your pods run, and here are some of them:
- Availability Zones: Ensuring pods run in zones where dependent applications or storage are available. This is especially important if your applications depend on other services or storage systems that are only available in specific zones
- Hardware Requirements: Requiring specific types of processors or other hardware. For instance, you might have workloads that perform better on GPUs or need the latest generation of CPUs for efficiency.
- High Availability: High availability is a critical factor for many applications, especially those that need to be up and running at all times. By using topology spread techniques within layered constraints, you can distribute your pods across different nodes and zones.
One idea of understanding LCM is to think of it as a set of rules that guide where and how your pods are scheduled, from broad to very specific criteria. Let’s break down these layers:
- Cloud Provider Constraints: The cloud provider defines the initial set of constraints, including all available instance types, architectures, zones, and purchase types.
- Cluster Administrator Constraints: The cluster administrator can add another layer of constraints by creating one or more NodePools. These NodePools define limits on which nodes can be used.
- Pod Specifications: Finally, you can add constraints directly to your Kubernetes pod deployments. These constraints must align with the NodePool constraints to ensure successful scheduling. For example, if a NodePool is restricted to a particular zone, pods requesting a different zone will not be scheduled.
Types of Constraints
Using a well structured set of constraints, that are fit to your workload, ensures that pods are scheduled in the most appropriate environments to meet specific needs. Below are the most important types that can help you achieve that.
Constraint Type | Description | Example |
Resource Requests | Specify the required amount of memory or CPU. | A pod requiring 2 CPUs and 4GB of memory. |
Instance Family | Specify the instance families to be used in the workload | Requires that the node is using one of the following families [“m5”, “c5″,”c5d”,”c4″,”r4″] |
Node Selection | Choose nodes with specific labels using nodeSelector. | A pod scheduled on nodes labeled with role=frontend. |
Node Affinity | Use affinity rules to draw pods to nodes with certain attributes. | A pod that prefers nodes with SSD storage or specific GPU types. |
Topology Spread | Ensure application availability by distributing pods across topology domains. | Distributing replicas of a service across different availability zones to ensure high availability. E.g: To use specific AZs: [“us-west-2a”, “us-west-2b”] |
Pod Affinity/Anti-affinity | Influence pod placement based on the presence of other pods | Ensuring that pods of the same service are placed together, or critical pods are placed on different nodes. |
Unified Scheduling Constraints
Karpenter supports standard Kubernetes scheduling constraints, allowing you to define a consistent set of rules that apply to both existing and newly provisioned capacity. This flexibility ensures that your workloads are scheduled efficiently and according to your specific requirements.
Optimize EKS with nOps
If you’re looking to optimize your EKS utilization and costs, nOps can help. Just simply integrate it with Karpenter or Cluster Autoscaler to start saving.
nOps offers proprietary AI-driven management of instances for the best price in real time. It continually analyzes market pricing and your existing commitments to ensure you are always on the best blend of Spot, Reserved, and On-Demand, gracefully replacing nodes before termination. Here are a few of the benefits:
- Hands free. Copilot automatically selects the optimal instance types for your EKS workloads, freeing up your time to focus on building and innovating. As your dynamic usage scales, Copilot continually reconsiders your instance placement.
- Effortless Spot savings. Copilot makes it easy to benefit from Spot savings. nOps predicts terminations 60 minutes in advance, putting you on diverse and safe Spot options to greatly reduce unexpected interruptions. In fact, our Spot SLAs are the same as AWS On-Demand.
- No vendor-lock in or upfront cost. Just plug in your AWS-native EKS clusters to start saving effortlessly, and change your mind at any time.
Our mission is to make it easy for engineers to cost-optimize, so that they can focus on building and innovating. nOps was recently ranked #1 in G2’s cloud cost management category.
Join our customers using nOps to cut cloud costs and leverage automation with complete confidence by booking a demo today!