Increase AWS Cost Savings with nOps Kubernetes (K8s) Cost Allocation, Optimization & Management Solution.
The cost of Kubernetes is a mystery to most of our clients. Since multiple teams share the clusters to run their services, Kubernetes’ cost allocation and optimization are difficult. If you look at the AWS billing console, you see the billing view below. However, the actual cost is much higher. In the billing console, you only see the cost for AWS EKS managed services. The actual EKS cost comes from EC2 instances that are part of customers’ billing.

The FinOps foundation has written a fantastic post suggesting that companies divide container optimization efforts into three categories: inform, optimize, and operate. As an elite cost optimization cloud management platform, nOps aligns practices around the FinOps foundation.
In this blog post, we’ll show you how nOps can help you with these three areas and use our environment and experience to guide you along the way. Let’s get started.
Inform & Prioritize Optimization Based on Opportunity & Impact.
Most of the time, software engineering teams want the capability to comprehend the financial impact of services. For example, here at nOps, each service in our environment is owned by a squad, which is in charge of everything from the functional code that establishes service behavior to the Terraform code used to coordinate service deployment. To understand the cost impact of their services in Kubernetes, we deploy our lightweight Kubernetes modules.
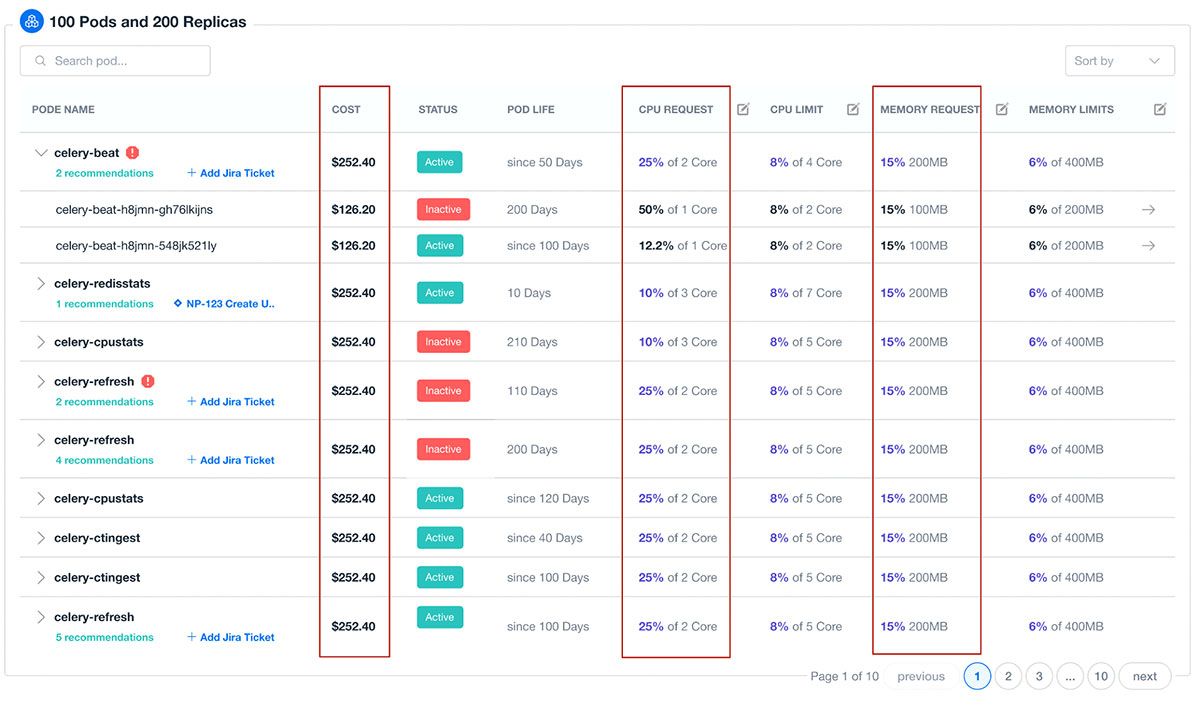
Our lightweight agent can be easily deployed and maintained in your environment and forwards relevant details to our data platform for real-time analysis and cost insights. We correlate cluster metrics with cost, usage, pricing, and savings programs data to deliver the deepest and most comprehensive insights at the container, pod, node, and cluster levels.
We also collect and aggregate by labels or drill into specific pod replicas or containers to see how they contribute to cost or create waste. These insights allow the team to make decisions about profiling, load testing, and tuning based on impact. Both pod and node-level insights can be sorted by cost, RAM, or CPU utilization making it extremely simple to prioritize optimization based on opportunity and impact.
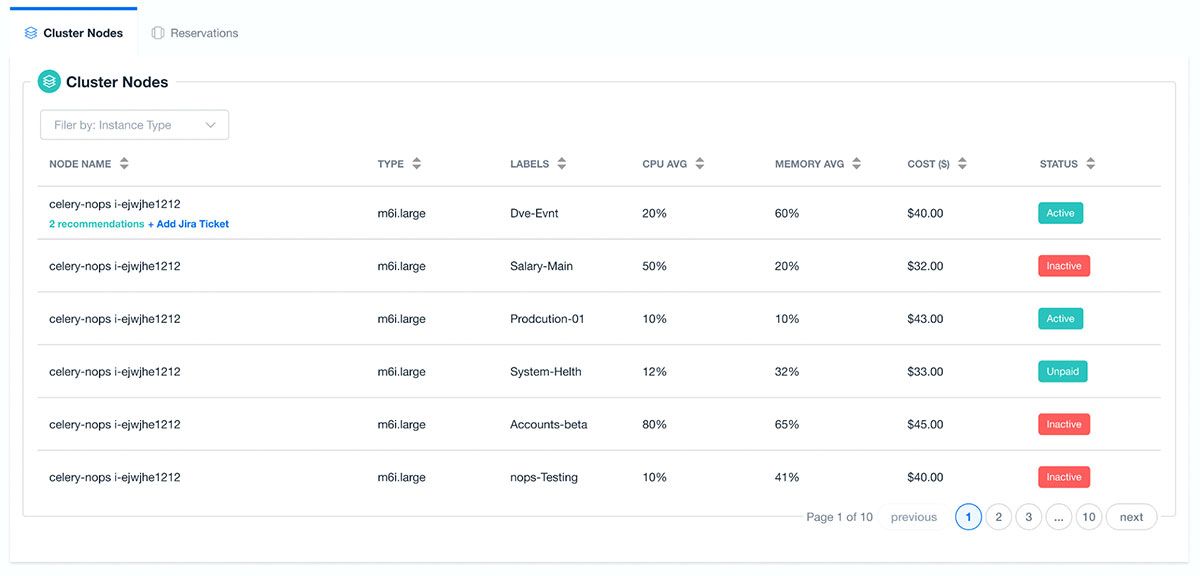
nOps also provides Cluster node insights so that we can make decisions about how to tune our instance type selections. We can quickly look at average node utilization over time and, again, prioritize our actions based on either cost impact or the largest rightsizing opportunities.
Optimize
Now that we’re no longer flying blind on our EKS clusters, acting becomes very easy. At nOps, we’ve started with conservative resource thresholds for our production environments – because we’ve got a constant stream of real-time tuning data, we can easily project the impact of new capabilities and ever-increasing load.
nOps pod recommendations give you the exact parameters to confidently tune your pod resource requests and limits.
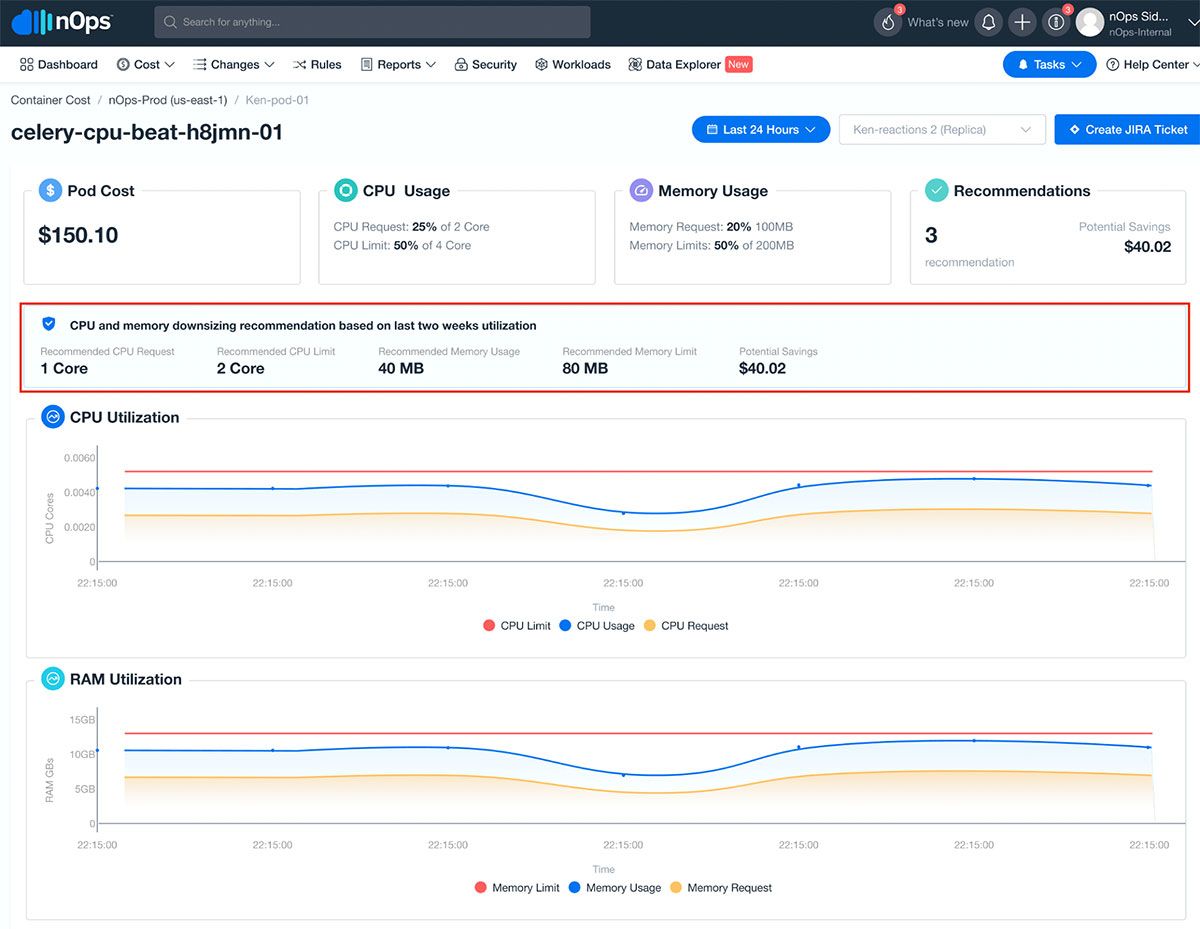
nOps also gives teams control over configuration insights and recommendations so that targeted recommendations can be tuned to meet the operational and business requirements of your workloads.
Through integration with both our Jira and Gitlab, tuning goes on auto-pilot as we ticket, approve changesets, and rollout optimizations without interruption to our critical feature delivery timelines.
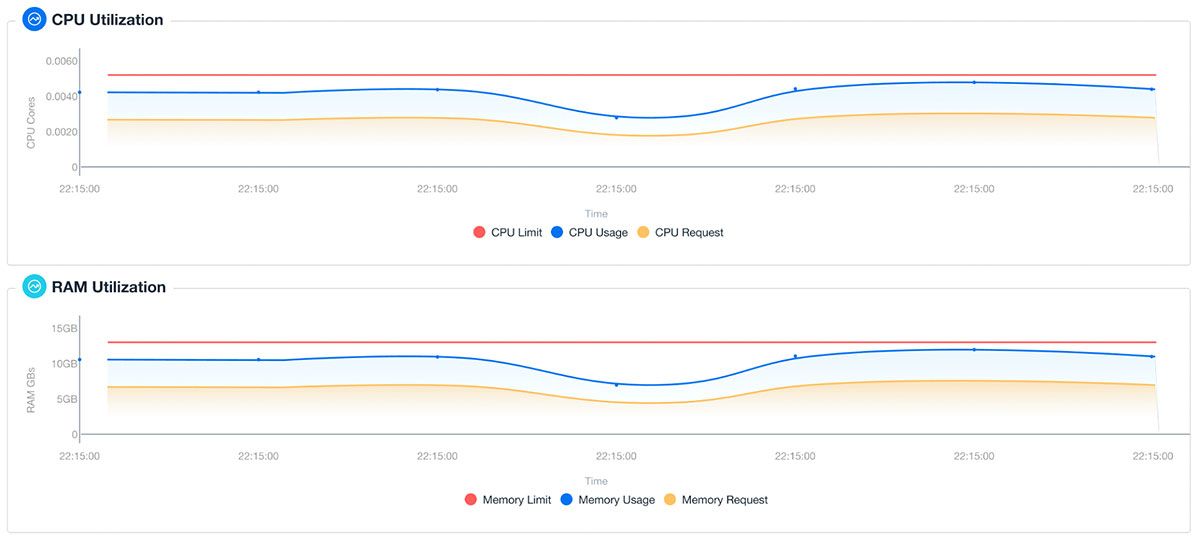
Keeping your pods tuned eliminates waste in your cluster by freeing up space for pods to scale on existing cluster nodes – and helps your team to exact immediate benefit with very low overhead.
Once your configuration house is in order, we can go further by limiting replicas based on the utilization patterns that nOps can give you at both the replica and container level. You can select any time window from the last 10 minutes to the last month, and investigate historical trends for ephemeral resources.
Now that we’ve got the basics of pod tuning taken care of, you’ll be able to make the most of tuning cluster nodes. Another thing that nOps makes very easy is to understand the impact of our node selection by identifying the waste that we have on our cluster nodes. The pod insights help us to organize our pods by either compute or memory optimization, and the node insights show us where we have opportunities to rightsize the nodes in our cluster.
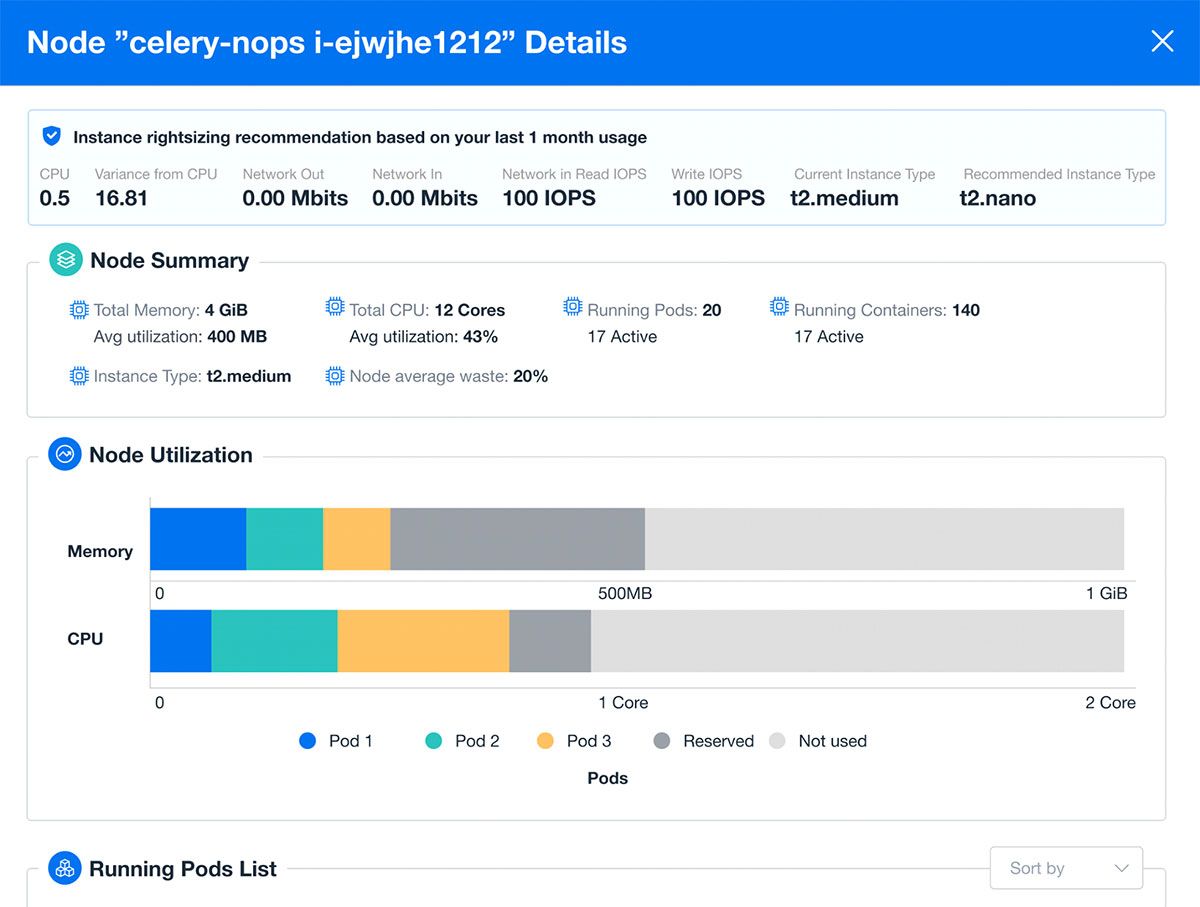
The nOps rightsizing recommendations help us to continuously optimize our node instance type selection to ensure that we are taking advantage of the latest in EC2 technologies and reducing the waste in our environment.
For our steadier state workloads, we also have the opportunity to increase our savings by taking advantage of nOps advanced reserved instance capacity capabilities. nOps will not only recommend reserved instance purchases that map to our cluster nodes but also helps us to clearly see how much coverage we have for our dominant instance types.
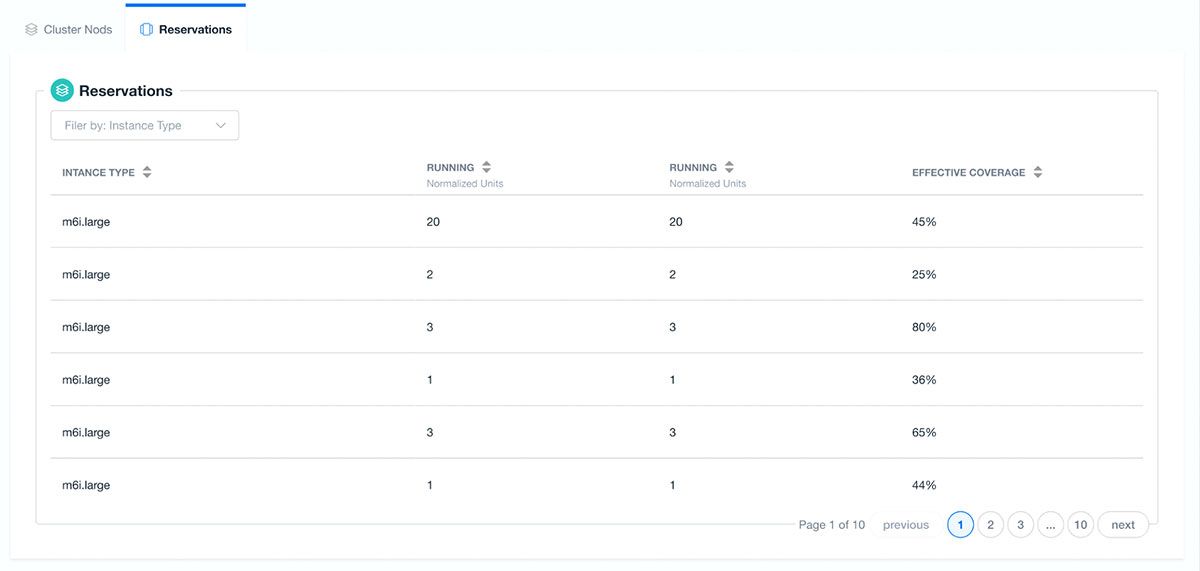
Impact
At nOps, we like to use our infrastructure to quantify impact and become our own best users. Let’s talk about impact. Within 48 hours of deployment into our environment:
- An average pod configuration optimization of 20% – we can now fit 20% more pods in our environment with the same operational confidence.
- Improved our process by rooting out default configurations and encouraging developers to make targeted configurations as part of our regular engineering workflow.
- Created a rightsizing opportunity for our largest node group to move from m6i.xlarge to an m6i.large – a 50% savings opportunity.
Also, thanks to nOps-powered RI automation, our environment automatically adjusts reservations to get maximum cost benefit with minimal interruption to our daily work of delivering new data and automation capabilities to our customers.
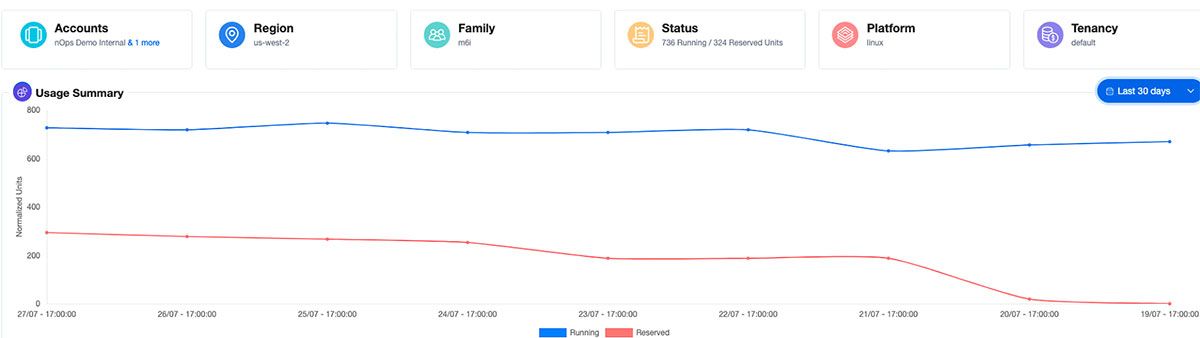
Stay tuned for a deep dive into the continuous operations and advanced automation features of nOps Kubernetes Cost Allocation and Optimization solution.
Related Topics
How to Optimize the Cost of Your Kubernetes Deployment
How the AWS Pricing Calculator Is Important When Choosing Cloud Resources
Increase AWS Cost Savings with nOps Kubernetes (K8s) Cost Allocation, Optimization & Management Solution.