

How to Use nOps to Rightsize Memory-Intensive AWS Resources
To achieve cost optimization, rightsizing becomes an ongoing process. Even if you rightsize workloads initially, changing performance and capacity requirements can result in underused or idle resources that drive unnecessary AWS costs.
Most organizations continuously rightsize their AWS resources to align with business needs and anticipated demand. Since there is no historical data for a new workload, you may end up guessing about instance types. As you collect historical utilization for existing workloads, you can rightsize the resource based on analysis of that data.
When you think about rightsizing your container resources, it’s essential to factor in both CPU and memory utilization. Some of our customers have CPU-intensive workloads such as 3D rendering, financial/scientific modeling, video encoding, or data mining. Others have memory-intensive workloads, such as large in-memory databases.
In this article, we’ll take you through a comprehensive, hands-on guide to with step-by-step instructions, effective strategies, and best practices for rightsizing memory-intensive AWS resources safely and effectively.
How to collect rightsizing metrics
To collect metrics for memory instances, you need to install an Amazon CloudWatch agent and send those resources to CloudWatch. You can also use third-party tools like Datadog to factor in memory resources. Check out these guides to collecting rightsizing metrics with CloudWatch and Datadog for more specifics.
In this table, you’ll find the relevant key metrics you’ll need for rightsizing. If you are using a different monitoring tool, you can look for similar metrics.
Metric Category | How It’s Used | CloudWatch Metric(s) | Datadog Metric(s) |
CPU Utilization | Evaluate the CPU usage to determine if a smaller instance could suffice. | CPUUtilization: Percentage of CPU utilization. | We recommend you use the CloudWatch metric — the closest Datadog metric to use is cpu.idle, which approximates CPU utilization when inverted. |
Memory Utilization | Memory metrics are crucial for accurate rightsizing, especially for certain instance types. Tools like AWS CloudWatch and third-party solutions like Datadog are invaluable. | mem_used_percent (custom metric): Percentage of used memory. | mem.used: Amount of RAM currently in use. |
Network Utilization | Assess disk I/O and network throughput to ensure your instances match your actual usage patterns. | NetworkIn: Total bytes received on the network. NetworkOut: Total bytes sent on the network. | net.bytes_rcvd: Total bytes received over the network. net.bytes_sent: Total bytes sent over the network. |
Storage Utilization | Focus on ephemeral disk usage to gauge whether the current allocation aligns with your actual needs. | disk_used_percent (custom metric): Percentage of used disk space. | Disk.used: Amount of disk space currently in use. |
Note that mem_used_percent and disk_used_percent are only available through CloudWatch Agent (they are not included in the free version of CloudWatch).
For any Amazon Elastic Container Service (Amazon ECS) task or service using the Amazon Elastic Compute Cloud (Amazon EC2) launch type, your Amazon ECS container instances require version 1.4.0 or later of the container agent to enable CloudWatch metrics. However, it’s recommended to use the latest container agent. For information about checking your agent version, go to the ECS instances tab under the ECS cluster.
Establishing Baselines and Collecting Metrics
The first step in rightsizing is to monitor and analyze your current use of services to gain insight into instance performance and usage patterns. At nOps, we recommend using at least a 15-day period (or ideally, 30 days) to establish a reliable baseline for rightsizing recommendations. Let’s discuss a few key guidelines:
- For the most accurate recommendations, increase the granularity of your metrics and observe over a longer time period (particularly if your workload is variable).
- Focus on maximum utilization rather than average or mean/median utilization. This is a slightly more conservative, but safer path for production workloads. For UAT or other non-critical workloads, you may wish to be more aggressive.
- Your instances may not be constantly running. If this is the case, the minimum period of data collection would be to observe the equivalent of 15 days (i.e. 360 hours) within a 30-day period.
Rightsizing Algorithms
Once you’ve collected metrics, the general rule is to rightsize against memory if you find that your maximum memory utilization is less than 40% over a four-week period. For example: If the current instance type has 8GB of memory available, and the average memory utilization is 700MB over a two-week period, you may want to rightsize with an instance type which has at least 1-2 GB of available memory.
We’ve summarized the various rightsizing calculations for each CloudWatch Metric; you can use the same principles with equivalent metrics from other monitoring solutions.
Metric | What it represents | Period to use | Metric type | Formula | Notes |
CPUUtilization | CPU Utilization percentage. | Last 30 days | Max | Rightsize if CPUutilization is at or below 40% | |
Mem_used_percent | Memory being used | Last 30 days | Max | Rightsize if mem_used_percent is below 80% of the lower instance type | |
NetworkIn | Network utilization (important for workloads relying on high bandwidth) | Last 30 days | Max | Rightsize if NetworkIn + NetworkOut is below 80% of the lower instance type | This depends on instance type — ensure that you put everything in the same scale, whether bytes per second, bits per second, or percentage |
DiskReadOps DiskWriteOps | Utilization of ephemeral (nonpersistent) storage — not to be confused with EBS (persistent) storage | Last 30 days | Max | Rightsize if DiskReadOps + DiscWriteOps is below 40% |
If you’re looking for additional tips and best practices, you can check out our full eBook The Definitive Guide to Rightsizing.
Continuous Rightsizing:
Even if you rightsize workloads initially, performance and capacity requirements for workload change over time. If you are not constantly rightsizing workloads, you are operating AWS like a traditional data center — it not only leads to unnecessary costs but also hinders optimal performance.
However, one of the challenges with rightsizing is that developers are afraid that it might break their workloads. That’s why it’s important to have accurate, data-backed recommendations that allow you to optimize for both operational efficiency and cost. The other challenge is that rightsizing is time-consuming — continually investigating and applying rightsizing recommendations takes considerable engineering time and resources.
That’s why we built nOps Essentials. It integrates with the two industry-leading monitoring solutions, AWS CloudWatch and Datadog, for effortless rightsizing savings. We automatically analyze every EC2 instance in your environment for recommendations, which you can apply with one click on the platform.
Real-time coverage of resource-level insights such as memory, CPU, network bandwidth and storage are fed through nOps’s state-of-the-art ML engine for the best rightsizing recommendations available on the market.
Rightsize with nOps for:
- The most trustworthy rightsizing recommendations. Because nOps automatically collects and analyzes highly granular data, recommendations are 100% accurate and reliable — so engineers can act on them with the utmost confidence that workloads won’t be disturbed.
- Significant time savings. nOps integrates with EventBridge, automating the complex and time-consuming rightsizing process into a single click — freeing up engineers to build and innovate.
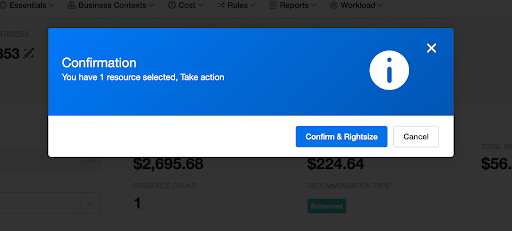
One-click rightsizing, right from nOps using EventBridge
- Up to 50% in immediate cost savings. When engineers don’t act on rightsizing recommendations, underutilized and idle resources continue to drive unnecessary AWS costs. nOps make it completely pain-free, safe and effortless for engineers to actually act on recommendations and start saving.
About nOps
nOps is a certified AWS Select Tier Services Partner and AWS Marketplace Seller. nOps helps companies automatically optimize any compute-based workload. Our mission is to make it faster and easier for engineers to take action on cloud cost optimization, so they can focus on building and innovation.
nOps processes over $1.5 billion in cloud spend and was recently ranked #1 in G2’s cloud cost management category. Join our customers using nOps to cut cloud costs and leverage automation with complete confidence by booking a demo today!
























