Skip to content
Skip to content


- Blog
- EKS Optimization
- Building an Effective Kubernetes Scaling Strategy: HPA, VPA, and Beyond
Building an Effective Kubernetes Scaling Strategy: HPA, VPA, and Beyond
Container efficiency hinges on optimizing resources at every layer: nodes, pods, and containers.
Horizontal Pod Autoscaler (HPA) and Vertical Pod Autoscaler (VPA) each focus on a distinct aspect of pod scaling—HPA adjusts the number of pods, while VPA optimizes resource allocation within pods.
Node provisioning is also one of the key areas of optimization, whether you’re using Cluster Autoscaler or Karpenter.
In this article, we’ll explore HPA vs VPA vs nOps, where Cluster Autoscaler and Karpenter fit in, and how to achieve a smarter, more efficient, and cost-effective Kubernetes environment.
What is HPA? (Horizontal Pod Autoscaler)
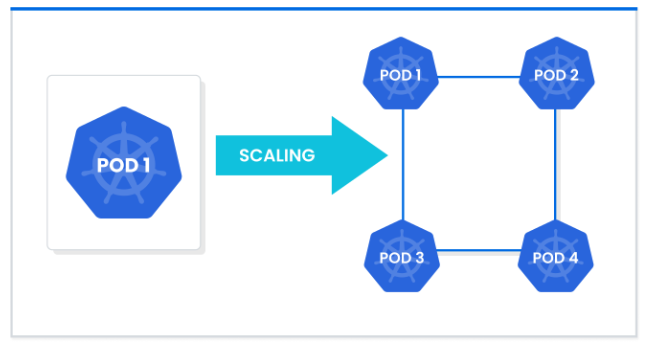
The Horizontal Pod Autoscaler (HPA) dynamically adjusts the number of pod replicas based on resource utilization metrics such as CPU, memory, or custom application metrics. HPA operates at the application layer, ensuring that workloads can handle fluctuating demand.
Scaling Out (Adding Pods):
Scaling In (Removing Pods):
The Limitations of HPA
What is VPA? (Vertical Pod Autoscaler)
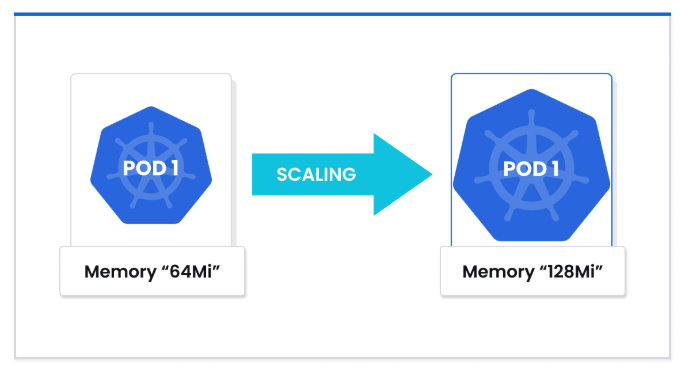
Dynamic Resource Allocation:
Usage Modes:
VPA has the following usage modes:
- Off (also called “recommendation mode”): Provides resource recommendations without applying changes.
- Auto: Applies recommended changes automatically (may cause pod restarts).
- Initial: Sets resource requests/limits for new pods but does not adjust running pods.
Pod Restarts:
To apply changes dynamically, VPA requires restarting pods (this can disrupt workloads).
VPA Limitations
VPA is for pod-level optimization only. It adjusts resources for the entire pod but doesn’t go deeper into container-level optimization. Also, using VPA requires restarts. Changes applied in “Auto” mode may impact application availability if workloads cannot tolerate restarts.
Using HPA and VPA together
VPA and HPA can be used independently, but careful consideration is required when using them together to avoid conflicting scaling actions (we cover this topic extensively in Horizontal vs Vertical scaling in Kubernetes).
VPA focuses on adjusting individual pod resource limits based on usage history, which optimizes for the resource allocation of each pod. On the other hand, HPA scales the number of pods in a deployment based on current CPU usage to handle traffic demands. This divergence can lead to situations where VPA’s recommendations for resource reduction conflict with HPA’s need to scale out, potentially causing resource contention or under-provisioning. Additionally, the complexity of managing both autoscalers together can increase the risk of misconfiguration.
nOps can solve this problem for you — read on to find out how.
Enhanced & autonomous Kubernetes optimization with nOps
1. nOps custom VPA
While VPA is a useful tool for adjusting resource requests dynamically within Kubernetes, it has its limitations. It operates only within Kubernetes, doesn’t factor in cost implications, and can sometimes clash with other autoscaling tools like HPA, creating inefficiencies.
With nOps’ custom vertical pod autoscaler (VPA), you can automatically apply resource recommendations to your workloads whenever they are updated. nOps VPA leverages the industry-standard Kubernetes Vertical Pod Autoscaler, with its security and reliability, to update workloads whenever new recommendations are available. You get the benefits of the VPA with the brains of nOps resource recommendations. Automatic optimization can be enabled or disabled on an individual workload basis, giving you complete control over your cluster.
And unlike standard VPA, it is fully compatible with HPA.
2. Dynamic Container Rightsizing
nOps’ Dynamic Rightsizing takes resource optimization to the next level. By analyzing real-time usage patterns and historical data from the past 30 days, nOps provides smarter, more cost-effective resource recommendations. It uses machine learning and AI-driven insights to decide whether to base recommendations on metrics like p95, p98, or even maximum usage based on how predictable or spiky your workloads are. This approach ensures recommendations are tailored to the unique needs of your workloads to balance performance and savings, not just based on static or generalized rules.
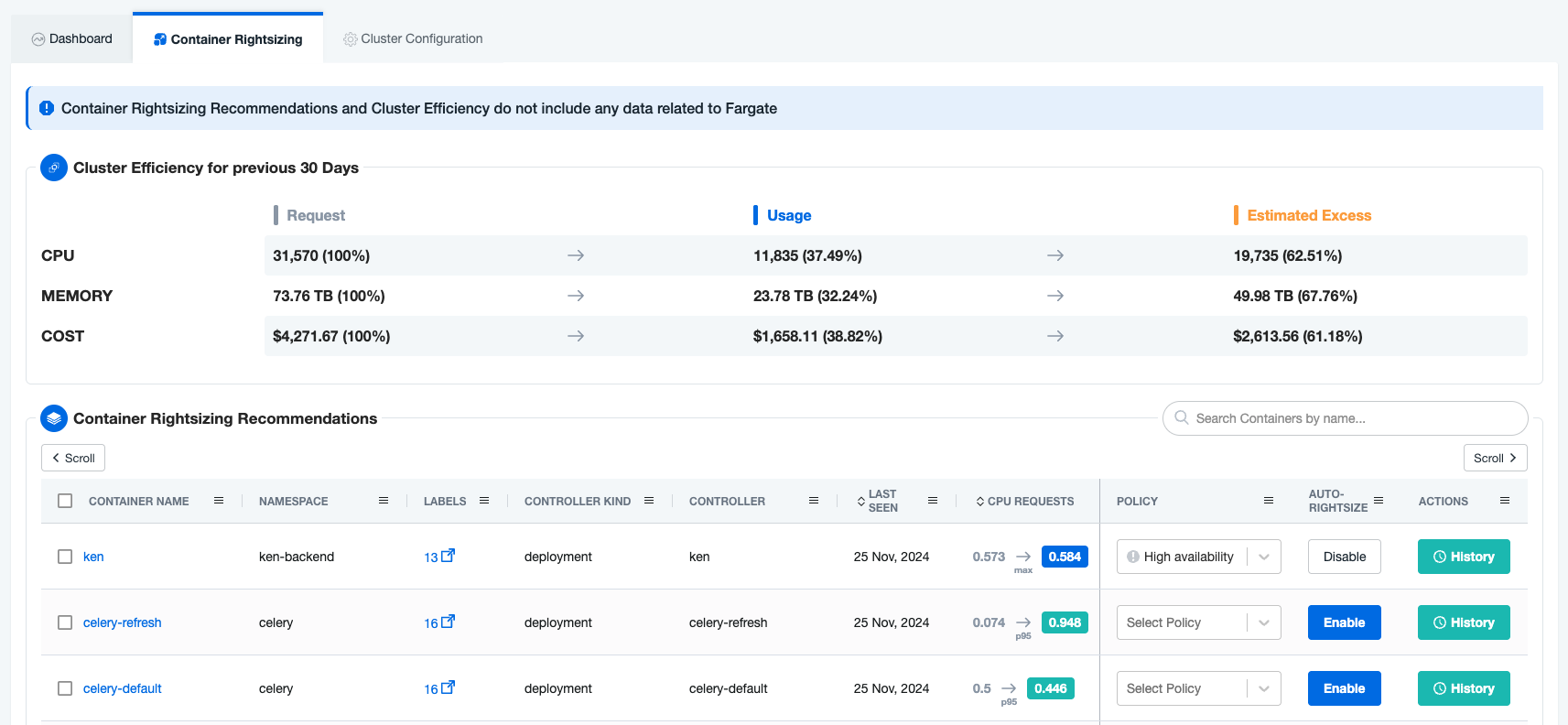
Here’s why nOps dynamic container rightsizing is better:
| Fine Tuned Control | nOps adjusts CPU and memory requests for each container individually, whether it’s a main application container or a sidecar. This ensures every container gets exactly what it needs to perform, without over-provisioning. |
| Data-Driven Decisions | Using 30 days of historical data, nOps identifies trends and patterns in how your workloads use resources. This real-world context makes recommendations far more accurate than reactive adjustments. |
| Smarter Predictions | With built-in machine learning, nOps analyzes workloads to recommend the best thresholds—whether it’s p95, p98, or the maximum observed usage. |
| Reduced Waste & Increased Savings | nOps helps eliminate unnecessary overhead by right-sizing requests to match actual container needs, cutting down on wasted resources without sacrificing reliability. |
| Built for Complex Workloads | Whether you’re running pod with multiple containers or workloads with varied usage patterns, nOps ensures every container is optimized individually, so nothing gets overlooked. |
3. Custom Recommendation Policies
By default, nOps will automatically select the best dynamic rightsizing policy for your workload based on its historical resource consumption.
Recommendation Policies also enable users to automatically and continuously tailor recommendations to their unique requirements by leveraging nOps-supplied Quality of Service levels that combine CPU and memory recommendations to meet real-world operational requirements. Now you can take advantage of automatic resource allocation while still covering your peak traffic use cases.
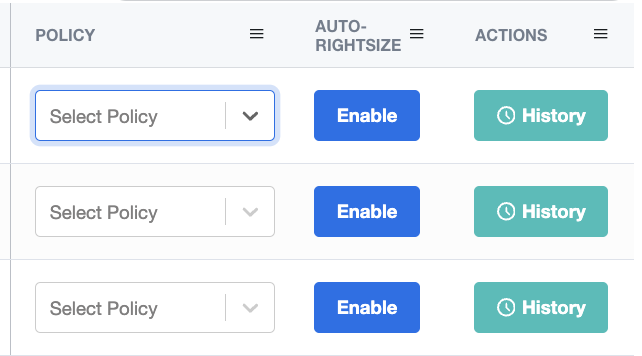
nOps offers a variety of preconfigured recommendation policies that cover common use cases, including a savings-oriented policy and a peak performance policy. Policies mix and match CPU and memory recommendations to create a custom combination that matches your use case.
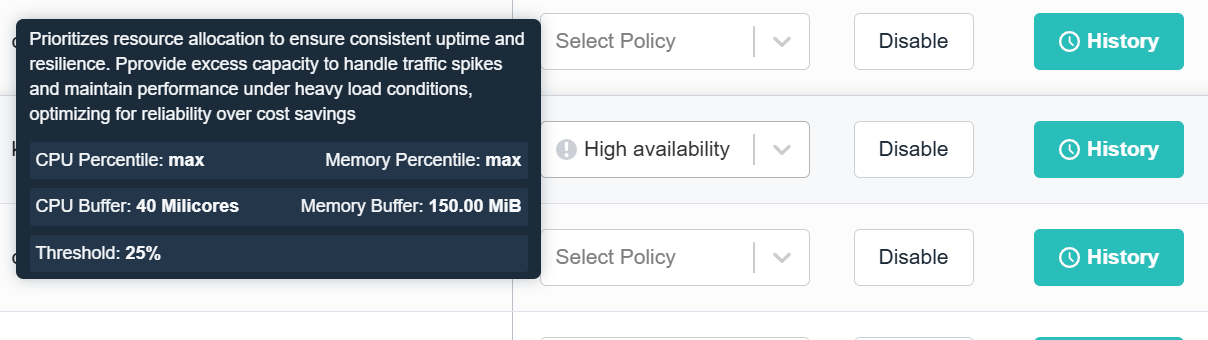
High Availability prioritizes resource allocation to ensure consistent updates and resilience.
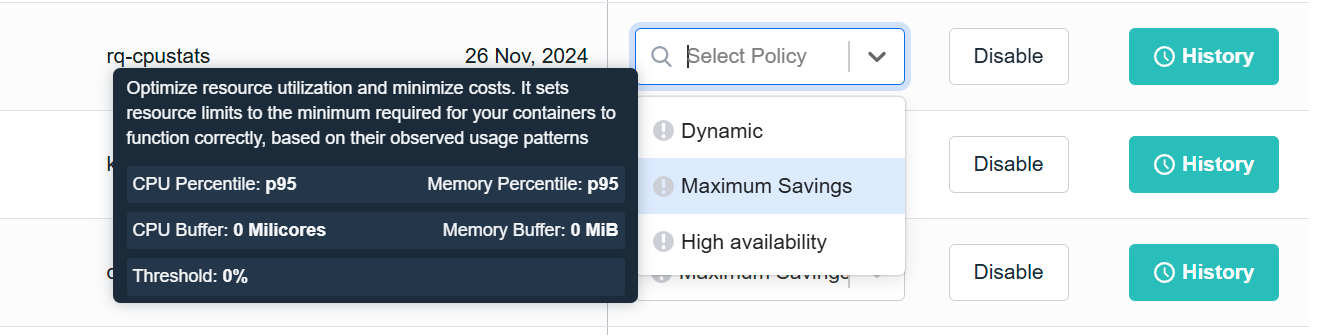
Maximum Savings optimizes resource utilization and minimizes costs.
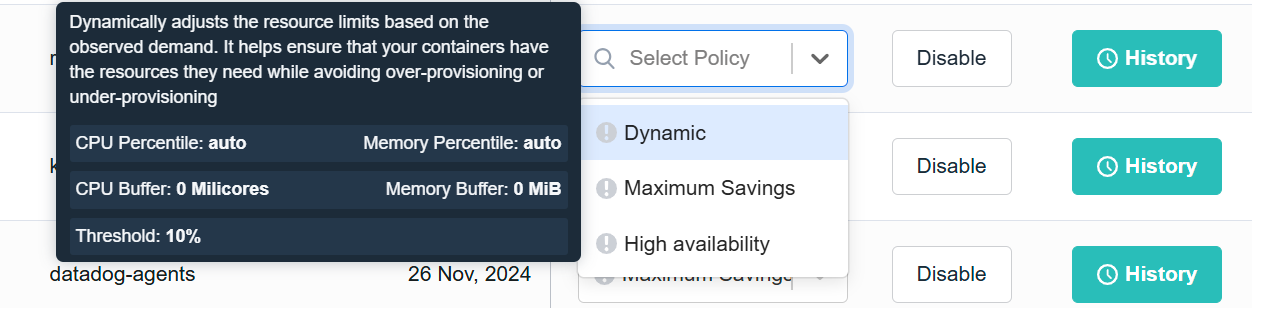
4. nOps Seamless Integration with Cluster Autoscaler and Karpenter
In addition to extending the pod-scaling capabilities of VPA, nOps Compute Copilot integrates with both Cluster Autoscaler and Karpenter, for intelligent and efficient node scaling, significant cost savings, and reduced manual overhead.
Integration with Karpenter
Karpenter, a high-performance open-source Kubernetes autoscaler, optimizes clusters by proactively launching right-sized compute resources for better scaling and less waste.
nOps helps you get even more out of Karpenter by adding additional capabilities, such as:
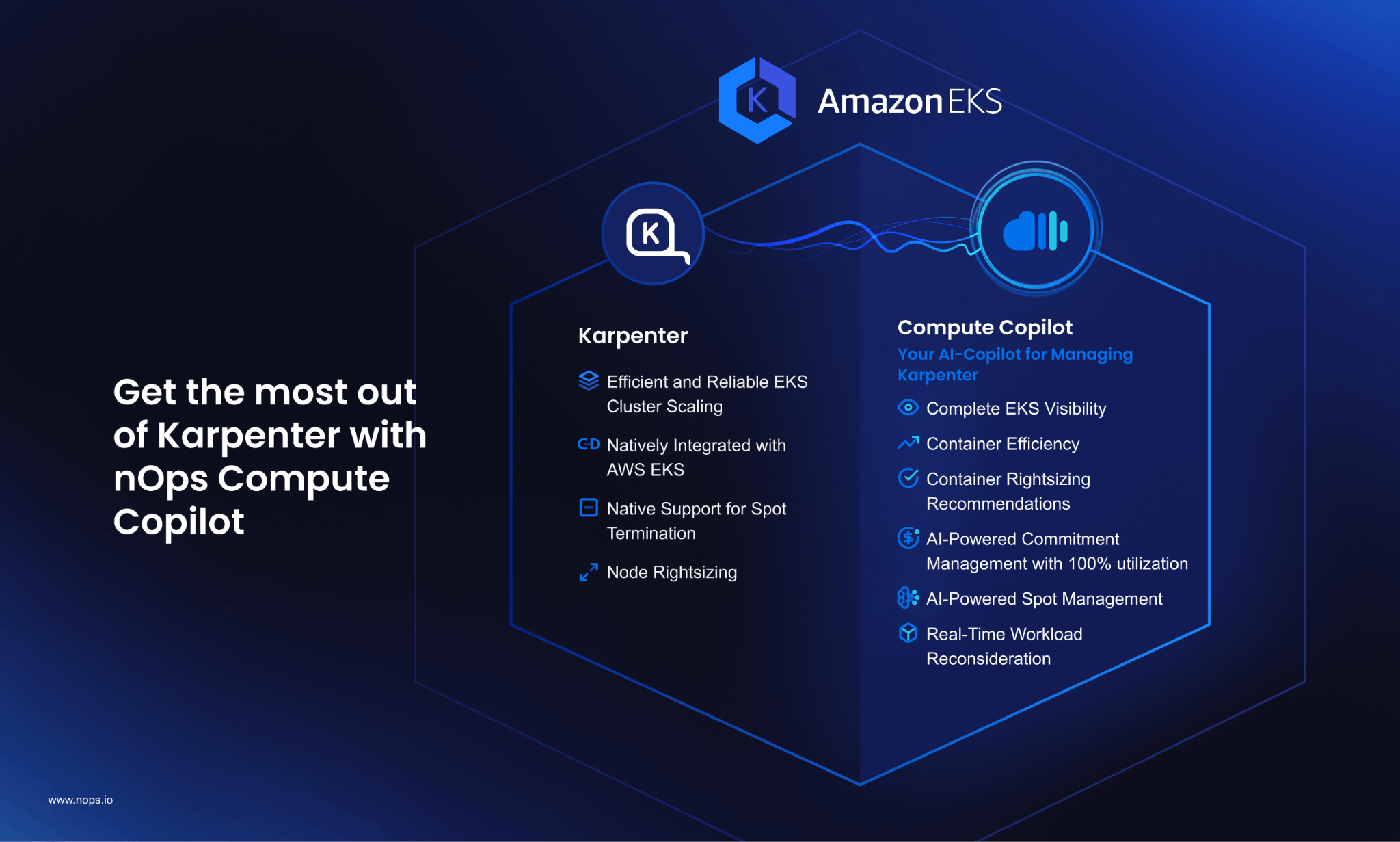
- Dynamic Node Provisioning: nOps enhances Karpenter’s ability to provision nodes dynamically. Once you effortlessly onboard by one-click importing your NodePool configurations, nOps selects the most cost-effective instance types based on workload requirements and continually tunes your configurations with real-time workload reconsideration.
- Discount Optimization: nOps ensures workloads intelligently prioritize Spot Instances or reserved capacity to reduce cloud spend, aligning resource usage with cost-saving strategies without compromising reliability. Customers typically see a 20-40% reduction in cloud costs by leveraging these optimizations.
- Rapid Scaling: By optimizing node provisioning, nOps enables Kubernetes clusters to scale nodes quickly and efficiently, ensuring workloads are never left waiting for resources while maintaining operational efficiency.
Integration with Cluster Autoscaler
Compute Copilot works alongside Cluster Autoscaler by managing Auto Scaling Groups (ASGs). It intercepts scaling actions triggered by CA using AWS Lambda, ensuring that when your cluster scales, the most cost-effective instances—like Spot Instances—are used while still meeting workload demands.
Smart Cost Optimization: By aligning ASG configurations with your reserved instances or savings plans, Compute Copilot ensures scaling happens efficiently. When CA adjusts the DesiredCapacity of an ASG, Compute Copilot steps in to determine the best instance types to launch, reducing reliance on expensive On-Demand instances.
Better Resource Efficiency: Compute Copilot dynamically optimizes ASGs to match workload needs. Through real-time adjustments to instance configurations and capacity, it ensures CA can scale up or down without over-provisioning or wasting resources.
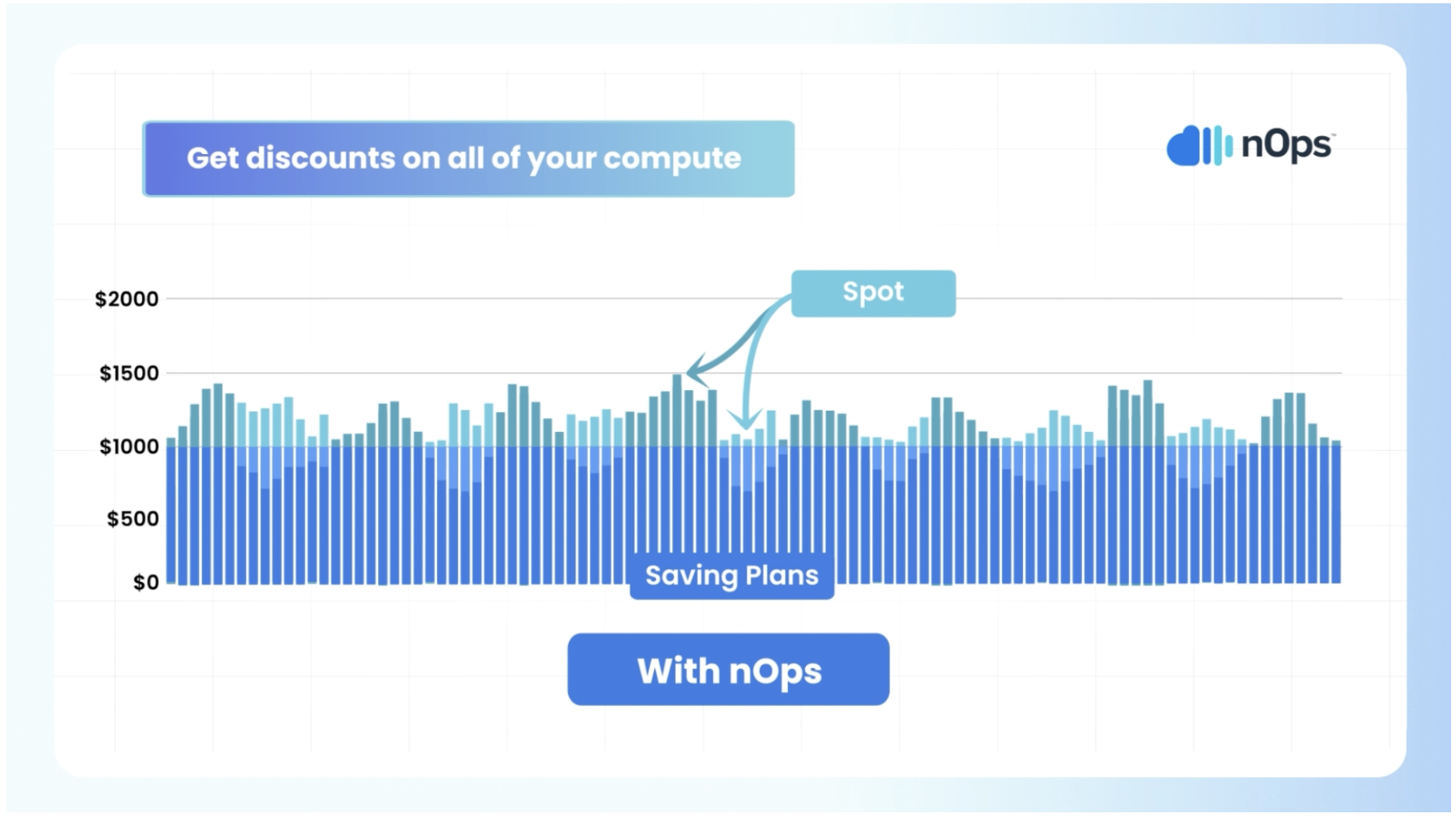
5. Pricing-Optimized Scaling: Discounts on All of Your Compute
AWS offers discounts of up to 72% if you commit to purchasing Reserved Instances (RIs) or Savings Plans (SPs) with a one- or three-year term, depending on the plan type and payment option selected. But HPA and VPA aren’t inherently aware of these commitments.
In contrast, nOps is aware of your organization-wide existing cloud commitments. This enables nOps to:
- Optimize Node Provisioning: Scale workloads onto nodes that align with reserved capacity, maximizing cost efficiency.
- Utilize 100% of Commitments: Avoid unnecessary provisioning of On-Demand instances when existing commitments can be utilized.
- Maximize Discounts: nOps continually ensures you’re on an optimal blend of RI, SP and Spot while scaling, reducing manual overhead and ensuring you get discounts on all of your compute.
nOps was recently ranked #1 with five stars in G2’s cloud cost management category, and we optimize $2 billion in cloud spend for our customers.
At nOps, our mission is to make it easy for engineers to optimize. Join our customers using nOps to understand your cloud costs and leverage automation with complete confidence by booking a demo today!
Last Updated: February 9, 2026, EKS Optimization
Last Updated: February 9, 2026, EKS Optimization