 Skip to content
Skip to content


The FinOps Foundation Summit Recap (September 2026)
The FinOps Foundation isn’t just another industry group—it’s where the cost optimization playbook gets written. With 93% of the Fortune 100 participating and more than 60,000 trained practitioners, what comes out of these Summits sets the tone for how companies worldwide manage cloud and AI spend.
The September summit put a stake in the ground: FinOps for AI is no longer about how much you’re spending but about proving value. Hand in hand, a recurring theme was restraint: knowing when not to use AI. Many of the biggest cost failures come from misapplied or mismatched use cases—projects where a rules engine, classical NLP, or even a basic API would deliver the outcome faster and cheaper.
We analyzed the Summit closely and pulled out the top 8 key takeaways that matter the most.
1. Value > Spend: make AI value measurable
When attendees were live polled by Rob Martin about what’s hardest about managing AI in FinOps, the top answer wasn’t high AI costs or how to allocate them — it was proving value (38%).
Leaders don’t just want to know the bill—they want to know what the business is getting back. That means you need to define outcomes before you start: revenue growth, hours of work saved, lower risk exposure. For example, if you’re testing an AI agent to replace part of a customer success team, you’d set the bar up front: “Reduce ticket-handling time by 40% within 90 days, while keeping CSAT steady.” Pair that with costs from the start so you’re measuring both sides of the equation.
This matters because it ends the hand-wavy debates like “AI is too expensive.” Instead, you can show whether a feature actually pays for itself or not — this is key for roadmap conversations, financial forecasting, and “failing fast” before costs spiral.
2. Use a repeatable, cross-functional AI review process
One of the biggest pitfalls in AI right now is teams spinning up ad hoc proofs of concept in isolation. They start with good intent, but without shared goals or cost checks, those projects often burn money, duplicate effort, or never connect back to business value.
The recommendation from the Summit was to replace that chaos with a lightweight, recurring review that brings Product, Engineering, and Finance together. Keep it simple: a short intake and a consistent bar for “go/no go” and a quick discussion about costs and outcomes before anyone dives in.
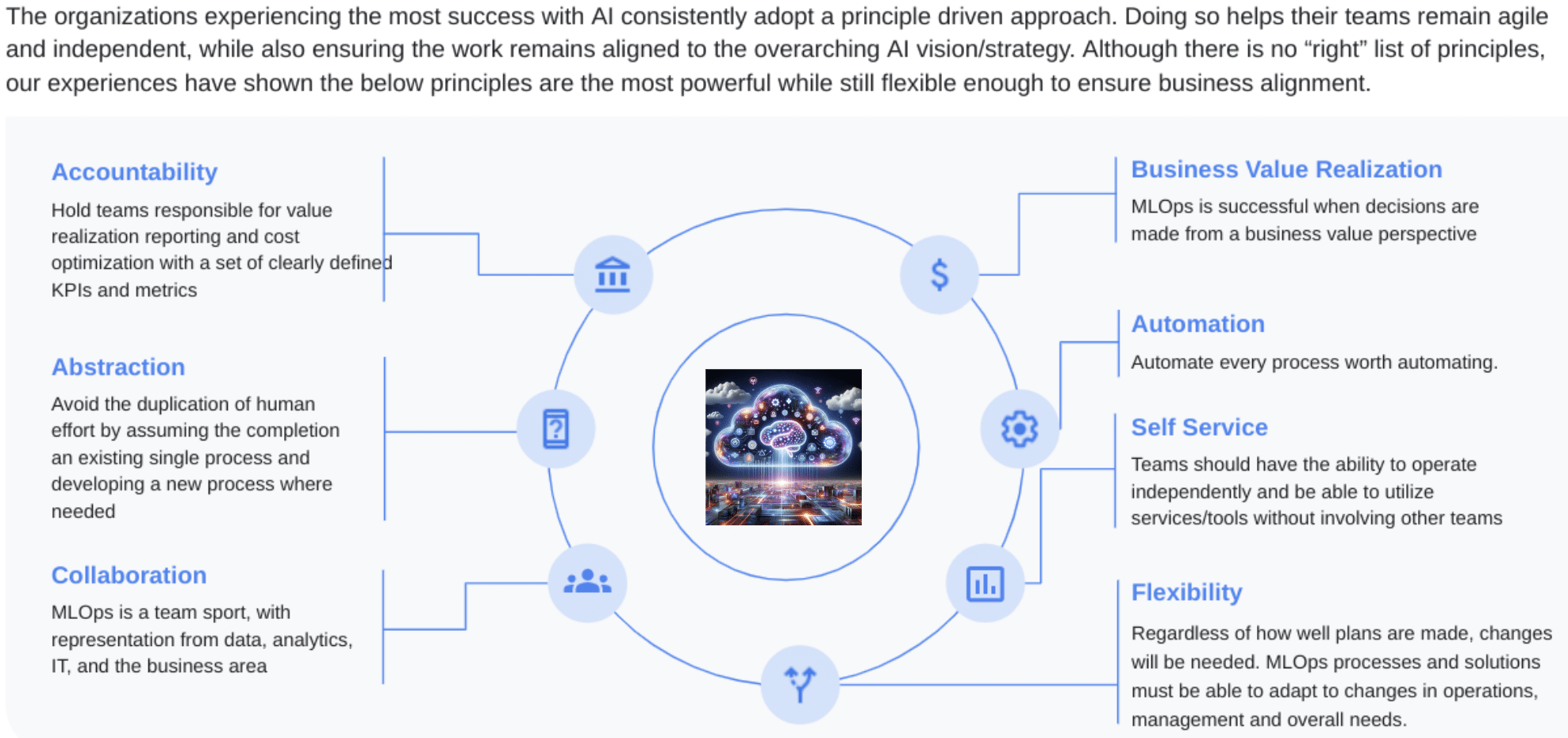
3. AI architectures are getting complex—add guardrails
Teams are moving beyond single prompts to retrieval-augmented generation (RAG), multi-step agent workflows, and orchestration across multiple models. That complexity is powerful, but it also makes costs harder to predict. Each new step—extra context pulled in, additional API calls, retries when an answer fails—adds another moving piece that can quietly drive up spend.
That’s why design-time and run-time guardrails matter. At design time, teams can set sensible defaults—limits on tokens or context length, rules for when to cache instead of call, clear budgets for experiments. At run time, those checks keep spend from spiraling if a workflow loops unexpectedly or an agent pulls in more data than intended. Because costs can so quickly go haywire, anomaly detection is a key safety net.
4. One “source of truth” report beats ten dashboards
A key lesson by Becky Canterbury was not to spin up a new AI reporting system, but to fold AI into the same monthly deck already used for cloud and SaaS. That creates one source of truth everyone works from, with the level of detail tailored to each audience: executives see spend trends and revenue impact to make faster calls; engineers self-optimize the moment they see their costs; forecasting gets cleaner.
If you’re multi-cloud, the challenge multiplies—AI apps might be running across ten different platforms, each with its own billing view. nOps can help with this — it integrates with all of your multicloud, Kubernetes and AI costs for a single pane of glass.
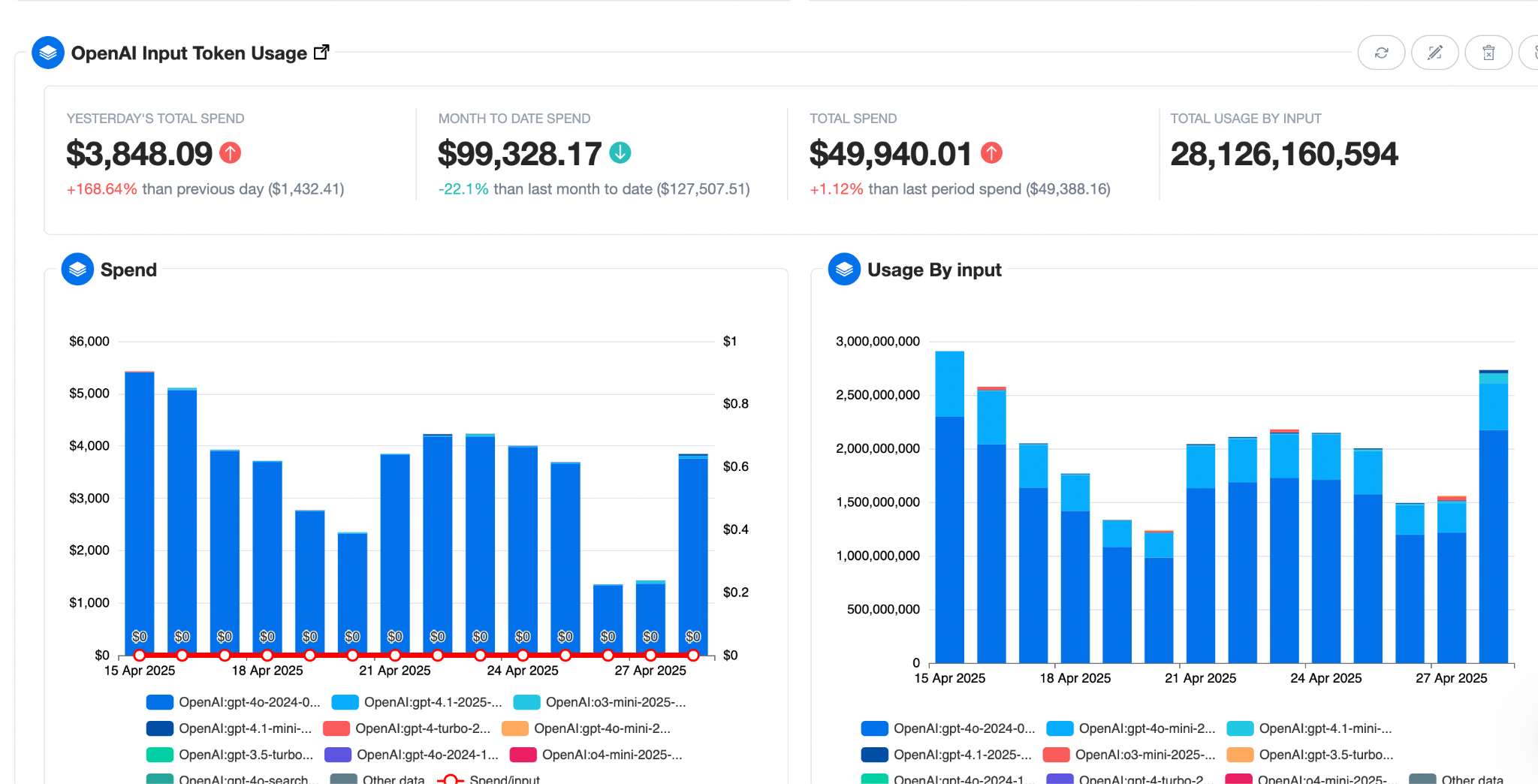
5. Choose instances by performance-per-dollar, not $/hour
Mike Thompson discussed a common trap: picking infrastructure by sticker price. Teams see a CPU instance at $0.90/hr and a GPU at $3/hr and assume the GPU is the “better” or “necessary” choice for AI. But what matters is performance-per-dollar, not the hourly line item. Benchmarking shows that for many inference workloads—especially smaller or medium-sized models, or jobs without strict latency requirements—CPU instances delivered the same results at a fraction of the cost. One example showed ~2× better performance-per-dollar by running an AI meeting summary agent on CPU, where an extra few minutes of processing time didn’t change the business outcome.
The takeaway is to benchmark before you default to “GPU-first.” GPUs are essential for some use cases (like large model training or latency-sensitive inference), but they’re not always the most economical. By testing CPU vs GPU for your workload and factoring in throughput, runtime, and latency sensitivity, you can materially cut net costs without changing the product or feature itself.

6. FOCUS 1.3 is coming
FOCUS (FinOps Open Cost and Usage Specification) is a common billing data format that cloud providers and tools are starting to adopt. Instead of every vendor giving you usage data in its own shape, FOCUS standardizes it—so costs, usage, and commitments can be compared and combined reliably.
Shawn Alpay outlined the upcoming 1.3 release, which adds two important capabilities: split cost allocation, so shared resources like Kubernetes can be broken out into sub-resources, and contract commitments, so you can see how usage lines up against negotiated deals. Alongside that, a new conformance tool is being built to validate provider data against the spec. These additions matter because they close gaps that make AI reporting especially messy—like splitting shared GPU clusters across teams or making sure commit burn-down is accurate. With 1.3, the foundation gets stronger for consistent AI cost management across providers.
7. Don’t default to AI—prove the fit before you optimize
One of the big themes of the Summit, in this case discussed by Taylor Houck, was knowing when not to use AI. The trap is to jump straight into optimization—tweaking tokens, caching, or GPUs—before asking if the project itself makes sense. The Summit framed this as a progression: first, cut use cases that are misapplied (problems that don’t need AI at all). For example, routing a support call to the right department is often better handled by a rules engine than an LLM, at a fraction of the cost. Next, avoid mismatched solutions—where AI is right, but the wrong tool is chosen. Sentiment analysis, for instance, can often be solved more cheaply with classical NLP than a large foundation model. Only once the use case and the tool are confirmed should you move on to AI cost optimization.
This sequencing matters because it prevents the worst kind of waste: pouring time and GPU dollars into projects that were never good candidates in the first place.
8. AI for FinOps is real—use it to find waste, you drive the change
The conversation closed on an important reversal: it’s not just about doing FinOps on AI, but also using AI for FinOps. GenAI Optimization tools are getting better at scanning cloud environments to surface inefficiencies continuously—things like oversized clusters, idle resources, or underused commitments. But the tech won’t fix it on its own. The role of FinOps is to orchestrate the right owners, turn those insights into action, and keep accountability in place.
That shift scales your impact. Instead of manually hunting for waste, you can lean on AI-powered detection and focus your energy on coordinating change across teams. The result is faster remediation, broader coverage, and a stronger position for FinOps as AI costs keep growing.
How nOps helps reduce AI cost
The themes from the Summit were clear: AI FinOps isn’t about chasing line items, it’s about proving value, knowing when not to use AI, and putting the right controls in place so costs don’t spiral. That means catching anomalies early, unifying spend across clouds and Kubernetes, benchmarking performance-per-dollar, and keeping reporting consistent.
This is exactly where nOps comes in. We integrate all your multi-cloud, Kubernetes, and AI costs into one view with a fullstack set of FinOps tools (anomaly detection, forecasting, cost recommendations, benchmarking, etc.) so you can put the Summit’s lessons into practice right away.
nOps was recently ranked #1 with five stars in G2’s cloud cost management category, and we optimize $2+ billion in cloud spend for our customers. Book a demo to start supercharging the value of your AI investments — or experience a quick interactive demo below.
Last Updated: December 15, 2025, FinOps
Tags
Last Updated: December 15, 2025, FinOps
