 Skip to content
Skip to content


- Blog
- Announcements
- FinOps X 2026 Day 1 Keynote Recap: The Great Token Panic and Is FinOps Dead?!
FinOps X 2026 Day 1 Keynote Recap: The Great Token Panic and Is FinOps Dead?!
FinOps X 2026 — the largest gathering of FinOps professionals is happening in San Diego this week. Here at nOps, we’re on the floor and keeping an ear on what practitioners are saying in the expo hall, sessions and side conversations.

Day 1 kicked off with a keynote from J.R. Storment, founder of the FinOps Foundation, focused on the topic on everyone’s mind: AI.
Two years ago, the mandate was simple: go all-in. Cost would be figured out later. Speed beats efficiency. Token consumption went exponential, CFOs stopped asking and started demanding answers, and FinOps teams everywhere realized: FinOps for AI is not Cloud FinOps.
"Traditional FinOps is dead," declared Pooja Kumar of Prudential Financial, capturing the mood in the room.

For FinOps teams navigating this landscape, Storment and other practitioners in the trenches offer a roadmap. Here are our top seven takeaways from the keynote:
#1: AI Growth is Going to 24x (Again) & the Subsidy Era Is Ending
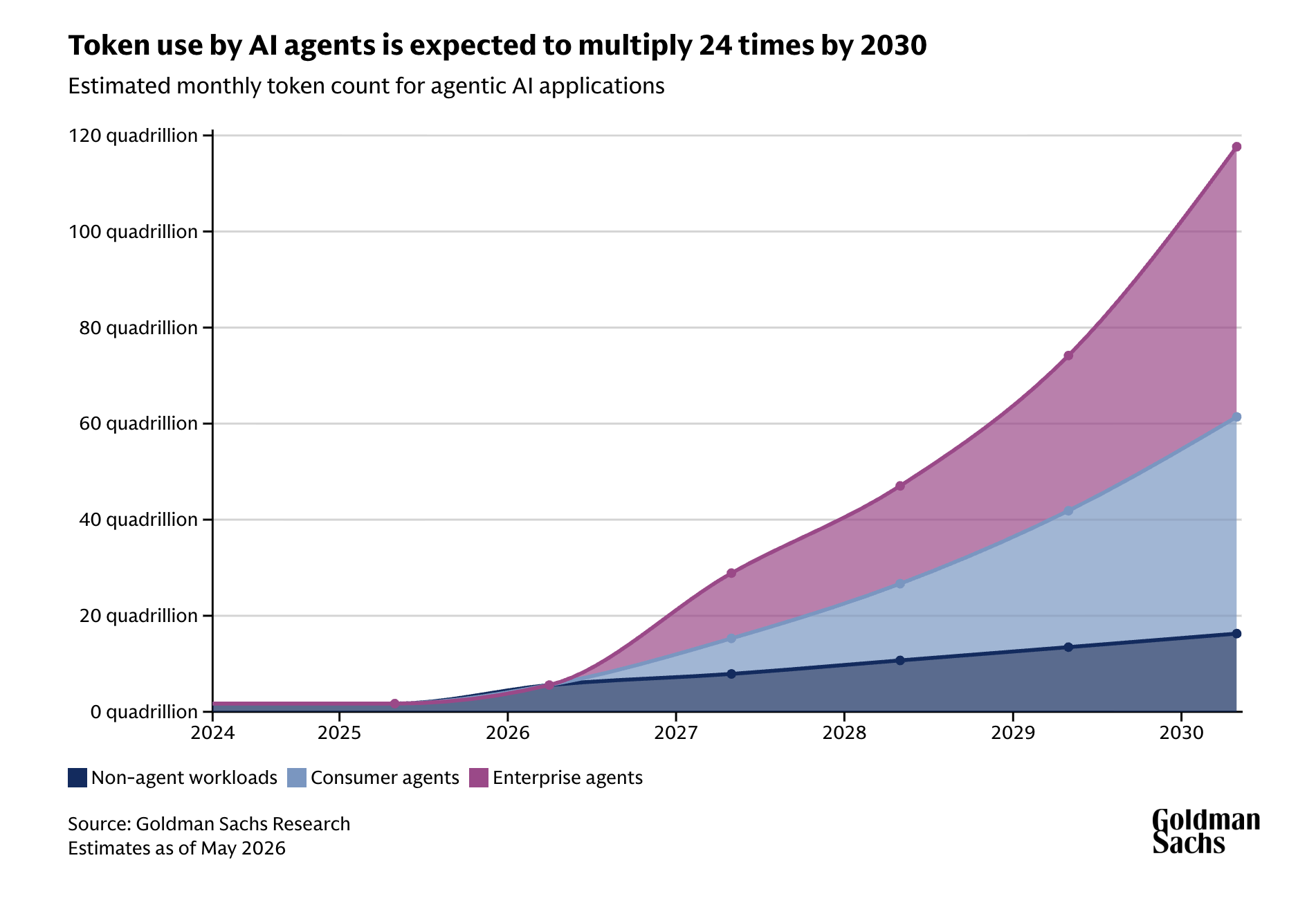
The first reality check: forecasts are failing at scale. Organizations forecasted their 2026 AI spend months ago — conservative estimates, aggressive estimates, everything in between. By June 9, many had already burned through 3x that entire annual budget.
The mechanisms that worked for cloud don't translate. Token leaderboards — the internal gamification of AI usage that was supposed to encourage adoption and surface high-value use cases — backfired spectacularly. Teams raced to the top without understanding the cost implications. All-you-can-eat subscription plans for AI, modeled on SaaS seat licenses, are being replaced by metered usage as providers face their own capacity constraints.
The numbers tell the story. Today's global token consumption sits at roughly 6 quadrillion tokens. By 2030, that number is projected by Goldman Sachs to reach 120 quadrillion tokens — a 20x increase in four years. That growth trajectory is faster than cloud adoption ever was, and it's happening across infrastructure that wasn't built to handle it.
#2: The Falling Cost Fallacy
The second takeaway: the cost-per-token floor is here to stay. Token prices fell dramatically from 2023 to late 2025 as model providers competed for market share and efficiency gains drove down per-token costs. Every organization budgeting AI spend in 2024 assumed that trajectory would continue. But that trajectory hit a wall in November 2025. Token pricing for top-tier models has been flat ever since — and Storment explained why that plateau is a structural shift, not a temporary pause.

Hardware scarcity. GPU supply can't keep pace with demand. Energy constraints are real — data centers are hitting power limits. Copper shortages are real — the physical infrastructure to connect GPU clusters is constrained. The neoclouds (hyperscaler-alternative GPU providers like CoreWeave, Lambda Labs, and Crusoe) are extending minimum annual commitments from one year to 3-5 years because they can't secure enough capacity to offer flexibility. The big four cloud providers — AWS, Google Cloud, Azure, and Oracle — collectively hold more than $2 trillion in combined infrastructure backlog.
AI scarcity until 2028. The supply-side constraints won't ease until 2028, according to industry forecasts. That means the cost-per-token floor is here to stay for the next 24+ months. Organizations that budgeted for continued token price deflation — assuming costs would keep falling as they did in 2024-2025 — are now facing a structural mismatch between their forecast assumptions and market reality.
This is the falling cost fallacy: usage is exponential, but costs are flat. The token bill keeps growing, even when per-token pricing doesn't. FinOps teams that anchored their AI ROI models on declining unit costs now need to rebuild those models entirely.
#3. The Token Bill Is Just the Start: 9 Cost Layers You're Paying For

It’s not all about the token count. In AI, you pay per token. But that pricing abstraction hides enormous complexity underneath. Storment broke down the full cost structure of AI workloads into nine distinct layers — and only one of them is metered.
Here's what you're actually paying for:
1. Token consumption — The visible bill. Metered per API call.
2. Retrieval and data — Corpus size and query volume for RAG (Retrieval-Augmented Generation) systems. The vector database that holds your embeddings costs money to store and query.
3. Orchestration — Agents per task, workflow automation overhead. Multi-agent systems multiply costs fast.
4. Inference infrastructure — Model size, GPU allocation, idle compute. The hardware running the model, whether you're using it or not.
5. KV cache — Key-value cache storage for context windows. This is the memory that lets models "remember" earlier parts of a conversation. Larger context windows (like 200k tokens) create massive KV cache bills that often go untracked until they show up as a surprise line item.
6. Evaluation and monitoring — Test runs, tracing, observability infrastructure. You need to know if your models are performing correctly, and that instrumentation costs money.
7. Governance — Regulatory compliance, data residency, sovereignty costs. Running models in specific regions to meet compliance requirements often costs 20-40% more than default deployments.
8. Human labor — Prompt engineering, output review, training data annotation. The humans in the loop.
9. Failure and waste — Retries when models fail, hallucination rework, and shadow AI (teams running unauthorized models outside central visibility and cost allocation).
Most FinOps teams have visibility into layer 1. Very few have instrumentation for layers 2-9. That gap is where AI cost overruns live.
#4. Tokenomics: A New Framework for AI Cost Management
The fourth shift: FinOps needs a framework purpose-built for AI. Storment introduced Tokenomics as an emerging framework for converting energy and capital into AI tokens — and then governing their consumption, allocation, and value realization.

Production: Energy, Capital, and Capacity Planning
This is how organizations (and providers) convert energy, capital resources, and infrastructure into AI capacity. It includes token factories (the GPU clusters that generate inference capacity), AI capacity planning and procurement, energy sourcing and sustainability constraints, and capital allocation for AI infrastructure buildout.
Production-side visibility is typically opaque to FinOps teams — you don't see inside your provider's GPU cluster allocation strategy. But understanding provider constraints (like the 3-5 year commitment windows neoclouds now require) directly impacts your procurement strategy and cost forecasting. If your provider is capacity-constrained, you can't assume infinite scale at flat pricing.
Consumption: Allocation, Forecasting, Optimization
This is where most FinOps teams operate today. It includes cost allocation, chargeback, showback, forecasting token demand across teams and workloads, optimization (model routing, batch processing, caching strategies), and ITAM (IT Asset Management) for AI infrastructure.
Consumption governance requires visibility across all nine cost layers, not just the token bill. Without that instrumentation, optimization is guesswork. You can't optimize what you can't see.
Value: Monetization, Pricing, and Labor Impact
This is how organizations measure ROI on AI spend and translate token consumption into business outcomes. It includes monetization strategies (if AI is customer-facing), pricing implications (how AI cost impacts product margins), product design tradeoffs (speed vs. cost vs. quality), and labor implications (how AI spend relates to headcount decisions).
The value layer is where AI cost becomes a boardroom conversation. CFOs don't care about tokens — they care about cost per outcome, margin impact, and whether AI investments are delivering measurable returns.
#5. What the Boardroom Is Asking: Value not Cost
The fifth shift: traditional FinOps metrics don't answer the questions executives are asking. CFOs are no longer asking "What did we spend on AI?" They're asking "What did we get for it?" While it’s too early to say where the industry will land, some imaginings include cost per verified outcome, direct allocation percentage, route win rate, cache + batch coverage, and sovereignty hit rate.
#6. Three Pricing Models, of Varying Opacity
Next, Storment dissected the three pricing models AI providers use — and why opacity is the enemy of cost governance.
Credit systems have no fixed relationship to tokens. You can't determine which model was used, how many tokens were consumed, or what the effective per-token cost was. Monthly credit limits can be consumed in 15-minute bursts with zero warning. Credit systems maximize provider revenue and minimize customer visibility.
Hybrid models layer token-based rate cards on credit systems — per-unit estimates, published token rates, and credit allocations coexist. Abstraction layers accumulate rather than simplify. You're paying by the token, but also by the credit, and the conversion rate changes based on model, region, and usage tier.
Direct (BYOK) models offer published per-token rates with full telemetry, but require infrastructure ownership. Bring-your-own-key infrastructure gives you full visibility — every API call billed at the provider's published rate, full telemetry showing every token consumed, by which model, for which request. Direct models are the gold standard for FinOps visibility, but they require operational overhead that many organizations aren't ready for.
Storment's point: opacity is a feature, not a bug. Providers gain pricing flexibility when customers lack visibility. The best defense is instrumentation — log every token call, track every model invocation, and build your own source of truth.
#7: The Tokenomics Foundation

The seventh and final announcement: the industry is formalizing AI cost governance. Storment closed with a major announcement: the Linux Foundation is launching the Tokenomics Foundation, a new open-industry body to set standards, benchmarks, and best practices for the economics of AI infrastructure.
This is a big deal. The Tokenomics Foundation will develop open specifications and frameworks for AI cost measurement, establish benchmarks for token economics across providers, create certification programs for AI FinOps practitioners, and fund and support the FOCUS specification (FinOps Open Cost and Usage Specification) as it extends into AI billing.
The foundation's governing board will include hyperscalers, neoclouds, enterprises, and FinOps platform vendors. The technical committee will develop the standards. And the certification program will define what it means to be qualified in AI FinOps — distinct from cloud FinOps. Who gets tokens, how many, and for what work? Should a human do this, or an agent? The framework, certifications, and a whole new team will answer these questions.
What the Industry Still Needs to Figure Out
Storment ended with a list of unanswered questions that the Tokenomics Foundation — and the broader FinOps community — will need to address over the next 18-24 months:
1. How do we measure cost per intelligent outcome instead of cost per token? The metric everyone wants, but almost no one can calculate.
2. Is intelligence per watt or TCO per intelligence the right metric? Sustainability and cost efficiency often conflict. Which should FinOps prioritize?
3. How do we standardize price change transparency across model providers? Token pricing changes with zero notice. How do we enforce transparency?
4. How do we price uncertainty and failure into AI investment decisions? Hallucinations, retries, and prompt drift all carry cost. How do we model that risk?
5. What is Tokenomics, and how does it intersect with FinOps? Are they the same discipline, or complementary practices?
6. Who gets tokens, how many, and for what work? Allocation policy at scale.
7. Should a human do this, or an agent? The meta-question: when does AI cost governance become automated by AI?
nOps at FinOps X

nOps is on the floor at FinOps X 2026 with a platform built for the realities Storment outlined: unified AI, multicloud and Kubernetes cost visibility and optimization.
Stop by the nOps booth or book a demo to see how we can help make your FinOps for multicloud and AI effortless.
nOps manages $4 billion in cloud spending and was recently ranked #1 in G2’s Cloud Cost Management category.
