Skip to content
Skip to content


- Blog
- Commitment Management
- De-Risk GCP Commitments: Why Overcommitment Is the Real Threat
De-Risk GCP Commitments: Why Overcommitment Is the Real Threat
This article breaks down:
- Why overcommitment became the bigger risk in 2026
- Why Google Cloud is uniquely susceptible to overcommitment, and
- How to structure a commitment strategy that stays resilient as workloads, demand and pricing economics change
Why Overcommitment Is Now the Bigger Problem
The traditional fear in commitment management was under-coverage: leaving on-demand spend on the table when you could have locked in a discount. That fear pushed teams toward aggressive purchasing — commit high, commit long, capture every dollar of savings.
The math has changed. Consider two scenarios for a team spending $100/hour on eligible GCP compute:
Scenario B — Over-committed by 20%: You commit $120/hour at the same 28% discount. Only $100/hour of usage absorbs the commitment, but you pay fees on the full $120/hour regardless. You’re now paying $86.40/hour for $100/hour of value — an effective discount of just 13.6%, materially worse than Scenario A — and the unused $20/hour of commitment burns roughly $126,000 in fees per year for capacity you never consume.
What Makes GCP Uniquely Susceptible to Overcommitment
SUDs Are Disappearing on New Machine Families
This creates a dangerous gap. Teams that modernize their fleet (as Google encourages) lose their free discount floor. A team running N2 with a 70% commitment gets the remaining 30% at a discounted on-demand rate via SUDs. That same team migrating to C4 or N4 loses the SUD entirely — the uncommitted 30% now runs at full on-demand. The reflex is to commit more aggressively to close the gap. But if the migration stalls or workloads fluctuate, that aggressive commitment becomes overcommitment overnight.
Net Price Billing Changes the Renewal Math
Google’s multiprice CUD model, active since July 2025 and automatically applied as of January 2026, fundamentally changes how commitment pricing works. Instead of a flat blended rate, each SKU gets individual pricing. Flex CUDs now apply to a broader set of services including Cloud Run and GKE Autopilot.
The overcommitment trap: under the old model, a $100/hour Compute Engine commitment was sized against Compute Engine spend alone. Under the new model, the eligible pool includes Cloud Run, GKE Autopilot, and other elastic workloads. Coverage ratios appear to drop overnight — not because anything shrunk, but because the denominator grew. Teams that react by upsizing their commitment to “match” the new pool risk over-purchasing, because serverless and container spend is far spikier than static VM spend. A commitment sized to peak Cloud Run usage is heavily underutilized during troughs.
Flex CUDs Don't Cover Everything
Flex CUDs solve the cross-family problem but at a discount-rate cost: roughly 9–11 percentage points below resource-based CUDs at the same term (28% vs. 37% at one year; 46% vs. 57% at three years on general-purpose). And some workload types — particularly T2D (Tau) instances — have historically had limited or variable flex CUD eligibility depending on the billing model version.
Commitment Strategies That Absorb Change
The Layered Commitment Model
| Layer | Coverage Target | Instrument | Term | Purpose |
|---|---|---|---|---|
| Foundation | 50–60% of baseline | Resource-based CUDs | 1 year | Maximum discount on rock-stable workloads |
| Agile | 15–25% of variable spend | Flex CUDs | 1 year | Cross-family, cross-region flexibility |
| Peak | Remaining spend | On-demand | None | Zero commitment risk on variable workloads |
The foundation layer uses resource-based CUDs because their discount rates are higher than flex at the same term — roughly 37% on a one-year resource-based commitment for general-purpose machines, vs. 28% for one-year flex. You accept the machine-family lock-in because these are workloads you have high confidence won’t change within the term.
Blended Resource-Based and Flex CUD Strategy
Resource-based CUDs for workloads where you know the machine family won’t change within 12 months. Database servers on N4. Batch processing pipelines on C4. Stable GKE node pools. These get the highest possible discount — 37% on a one-year resource-based commitment for general-purpose families.
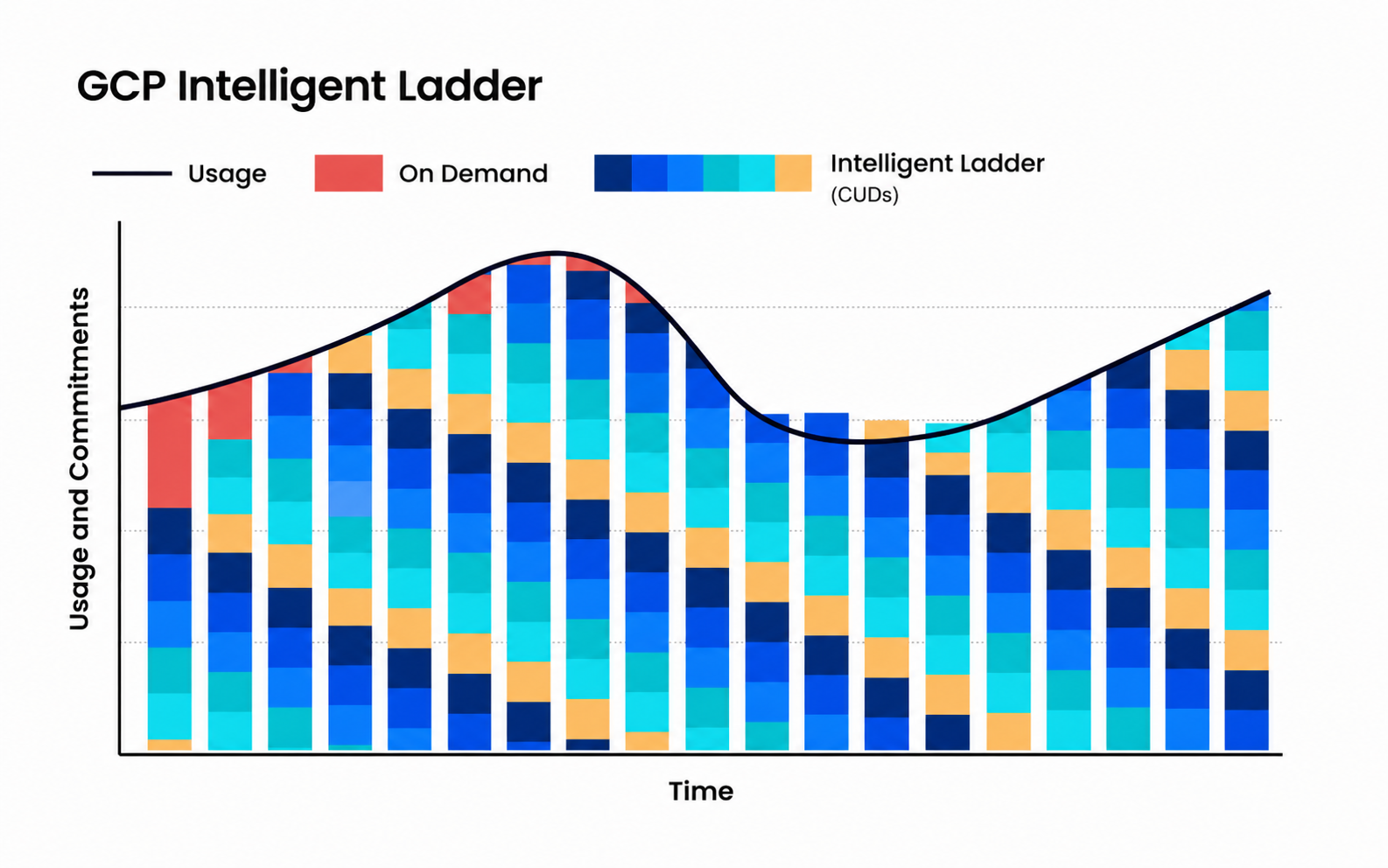
Intelligent Laddering to Avoid Renewal Cliffs
Intelligent laddering spreads expirations across many more frequent dates. Instead of making one big risky commitment bet, you’re making smaller incremental purchases with more flexibility.
Benefits of this approach:
- No single point of failure. If usage drops 20% in March, you simply don’t renew March’s tranche. The other eleven continue at full utilization.
- Rolling adjustment. Each monthly renewal is an opportunity to recalibrate based on actual recent usage — not a forecast from twelve months ago.
- Migration-friendly. If engineering starts a machine family migration in Q2, you let the old-family CUDs expire naturally while purchasing new-family CUDs at the new monthly cadence.
How nOps Eliminates the Overcommitment Problem
Here’s how our approach works for GCP:
Reduce risk with intelligent laddering automation. We implement the laddering strategy described above, but at a granularity no human team can replicate. Dozens of small commitments, each sized to current usage, each expiring on its own schedule. The result? More incremental savings (up to 55%), with far less risk of overcommitment.