

How to Stop Overprovisioning in Kubernetes
Overprovisioning in Kubernetes (alternatively known as excess capacity, resource waste, underutilization, etc.) occurs when your deployments’ requested resources (CPU or Memory) are significantly higher than what you actually use. It may not be feasible to eliminate 100% of excess capacity. However, Kubernetes clusters are often massively and unnecessarily overprovisioned, presenting a significant opportunity to improve costs and cut waste.
Addressing these inefficiencies requires tackling both horizontal and vertical pod scaling and node scaling with tools like Vertical Pod Autoscaler (VPA), Horizontal Pod Autoscaler, Cluster Autoscaler and Karpenter.
In this blog, we’ll explore what is overprovisioning, how to think about overprovisioning, best practices to reduce overprovisioning and how to take resource optimization to the next level with nOps.
What Is Overprovisioning in Kubernetes?
Overprovisioning occurs when applications request more CPU and memory resources than they actually use. This often happens due to:
- Uninformed Resource Requests: Developers often choose easy, round numbers for resource requests and limits—such as 500 millicores or 1GB of memory. While convenient, these guesses rarely match actual application needs, often resulting in wasted resources.
- Conservative Provisioning: Teams may intentionally over-allocate resources to prevent performance issues, especially during peak loads.
- Scaling Inefficiencies: Static or manual scaling strategies fail to adjust to the dynamic nature of Kubernetes workloads, leaving resources idle.
How much overprovisioning is okay?
As mentioned, you may want to provision a certain amount of excess capacity in your clusters depending on the circumstances. The two key considerations are:
Environment
In non-production environments, cost efficiency is supreme. Non-production, test or R&D workloads typically tolerate higher variability in performance, offering key opportunities for provisioning less without impacting quality of services. In production environments, however, there is a lower tolerance for disruption and more margin is necessary to maintain a high level of robustness and reliability even when optimizing for costs.
Workload type
- Stateless workloads are highly elastic and can easily be scaled up or down with minimal impact. Excess capacity is less critical, but rightsizing ensures cost efficiency.
- Stateful workloads require data persistence and robust infrastructure. Here, performance and reliability are more important than immediate cost savings, and higher tolerance for overprovisioning may be necessary.
- Batch/Data workloads often run on a schedule or in bulk. You can allocate excess capacity based on peak load expectations, but considerations like pod to node placement and workload schedule play a major factor in deciding how much excess capacity per node is appropriate.
- Data Persistence workloads should be carefully analyzed and have a stable buffer for excess capacity, given the need to maintain data integrity, with backup strategies and data storage costs as important considerations.
- AI/ML workloads often require intensive compute resources. Some excess capacity is crucial for ensuring model training and inference processes run smoothly, but optimizing for cost while maintaining performance can deliver significant savings.
Suggested Guidelines for Overprovisioning:
Workload Type | R&D | Production (Price) | Production (Performance) |
Stateless | 5% | 15% | 25% |
Stateful | 15% | 25% | 35% |
Data/Batch | 5% | 15% | 25% |
Data Persistence | 10% | 20% | 30% |
AI/ML | 10% | 20% | 30% |
Best Practices to Minimize Overprovisioning
Let’s dive into some best practices and strategies to optimize resources and improve cluster efficiency.
1. Formulate a Systemic Approach to Container Efficiency
Achieving container efficiency requires a systematic approach, starting from the smallest component and moving up. The basic steps include:
- Rightsize containers: Begin by optimizing container resource requests and limits to avoid overprovisioning resources.
- Optimize pod placement: Design a strategy to minimize resource contention.
- Optimize node provisioning: Utilize flexible auto-scaling solutions that adapt to workload needs, such as Karpenter.
- Optimize for price: Once container resources and infrastructure utilization is optimized, pricing strategies like Spot Instances and Savings Plans can further reduce costs.
2. Leverage Historical Data and Percentile Analysis to Rightsize Containers
Historical usage data is critical for rightsizing workloads. Metrics like p95, p98, and Max provide deeper insights into resource needs.
- p95: Ideal for stateless workloads where occasional performance dips are acceptable.
- p98: Suitable for batch workloads, balancing cost efficiency with reliability.
- Max: Best for mission-critical workloads (e.g., AI/ML), ensuring performance even during rare peaks.
Example: Using p95 metrics for a stateless API workload might reduce CPU requests by 20%, while maintaining 99.5% uptime.
3. Use the Right Scaling Approach
There are different ways that you can have your workloads adjust to fluctuating demand. Below we’ll walk through some of the most popular autoscaling strategies.
Horizontal Pod Autoscaler
Automatically adjusts the number of pods in a deployment based on CPU/memory utilization or custom metrics. It’s best suited for applications with variable load patterns.
Example configuration:
apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: example-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: my-app minReplicas: 2 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 70- Set
averageUtilizationthresholdsto match your app’s peak needs. For example, start with 70% and adjust based on performance testing. - You can combine HPA with external metrics (e.g., Prometheus) for more granular scaling. (See below for some concrete tips on this).
Vertical Pod Autoscaler (VPA):
Adjusts the CPU and memory requests/limits for pods based on usage patterns. It’s ideal for workloads where the number of pods remains stable but resource consumption varies.
Best Practices:
- Start with VPA in “recommendation” mode to analyze historical data before enabling live updates.
apiVersion: autoscaling.k8s.io/v1 kind: VerticalPodAutoscaler metadata: name: example-vpa spec: targetRef: apiVersion: "apps/v1" kind: Deployment name: my-app updatePolicy: updateMode: "Off" # Recommendation-only mode- Use tools like kubectl describe vpato analyze the recommended requests/limits for historical trends.
- Once confident, switch
updateModeto “Auto” to allow live updates.
Pitfalls to Avoid:
- Ensure your app handles restarts gracefully, as VPA may restart pods to apply new resource settings.
- Avoid aggressive downscaling; a sudden drop in memory can cause OutOfMemory (OOM) issues.
- Pay close attention to applications that require more memory during startup (Spark jobs for example). After initialization their memory utilization often decreases, however it’s important to request enough memory to ensure they have enough resources to start successfully.
For more advice on configuring HPA and VPA and using them both together, we cover this topic extensively in Horizontal vs Vertical Scaling: HPA, VPA, Karpenter, Goldilocks, KEDA & Beyond.
KEDA: Event-Driven Scaling
KEDA (Kubernetes Event-Driven Autoscaling) extends HPA capabilities by enabling scaling based on external events and metrics. It supports triggers like message queue length (RabbitMQ, Kafka), database load, or even custom APIs.
Why Use KEDA:
- Ideal for workloads with sporadic spikes or event-driven architectures, such as processing jobs from a queue or handling bursts of API requests.
- Allows you to scale workloads even when traditional metrics like CPU or memory aren’t good indicators of demand.
How to Configure a ScaledObject with KEDA:
apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: my-scaledobject namespace: default spec: scaleTargetRef: name: my-app minReplicaCount: 1 maxReplicaCount: 10 triggers: - type: kafka metadata: topic: my-topic bootstrapServers: kafka:9092 consumerGroup: my-group lagThreshold: "10"- Use minReplicaCount to ensure availability and lagThreshold (or equivalents) to match your specific trigger requirements.
4. Monitor Resource Usage with the Right Tools
To optimize resource allocation, continuously monitor actual usage with tools like:
Tool | Best For | Strengths | Limitations | Primary Use Cases |
Prometheus | Collecting CPU/memory metrics for custom dashboards | Highly customizable, supports extensive metric collection, integrates with other monitoring tools | Requires extensive configuration and external tools for visualization | Developers needing granular metrics for in-depth analysis |
Grafana | Visualizing trends and setting alerts for inefficient resource use | Powerful visualization capabilities, supports multiple data sources, user-friendly alerting | Relies on external data sources (like Prometheus) for full functionality | Teams requiring easy-to-read dashboards and trend analysis for resource management |
nOps | Real-time automated pod rightsizing, deep Kubernetes visibility and optimization recommendations | Comprehensive, end-to-end Kubernetes and AWS visibility and optimization | Primarily focused on optimization rather than raw metric collection | Organizations aiming to automate cost and resource efficiency improvements in Kubernetes |
Tip: Regularly audit your workloads. For example, if average CPU usage is consistently below 50%, reduce the request by 20% incrementally and monitor.
5. Define Realistic Resource Requests and Limits
Use Kubernetes ResourceQuota to set namespace-level constraints. For example:
apiVersion: v1 kind: ResourceQuota metadata: name: example-quota namespace: dev-namespace spec: hard: requests.cpu: "10" requests.memory: "32Gi" limits.cpu: "20" limits.memory: "64Gi"A pro tip is to start with generous quotas, then gradually refine resource definitions as usage trends stabilize.
How nOps Solves Overprovisioning
While HPA and VPA are helpful tools for scaling your pods, addressing overprovisioning at the node level is just as critical. This is where nOps truly shines, offering a comprehensive approach to optimize your entire Kubernetes environment.
Rightsized Pods
nOps minimizes CPU and memory overprovisioning by automatically applying optimal CPU and memory request values based on actual utilization. Manually rightsizing pods can be a time-consuming and error prone task, especially with the sheer number of applications often running on Kubernetes clusters. In addition, as CPU and memory utilization changes over time, engineers need to update their request values accordingly. nOps automates this process, enabling cost reduction at scale while maintaining application performance.
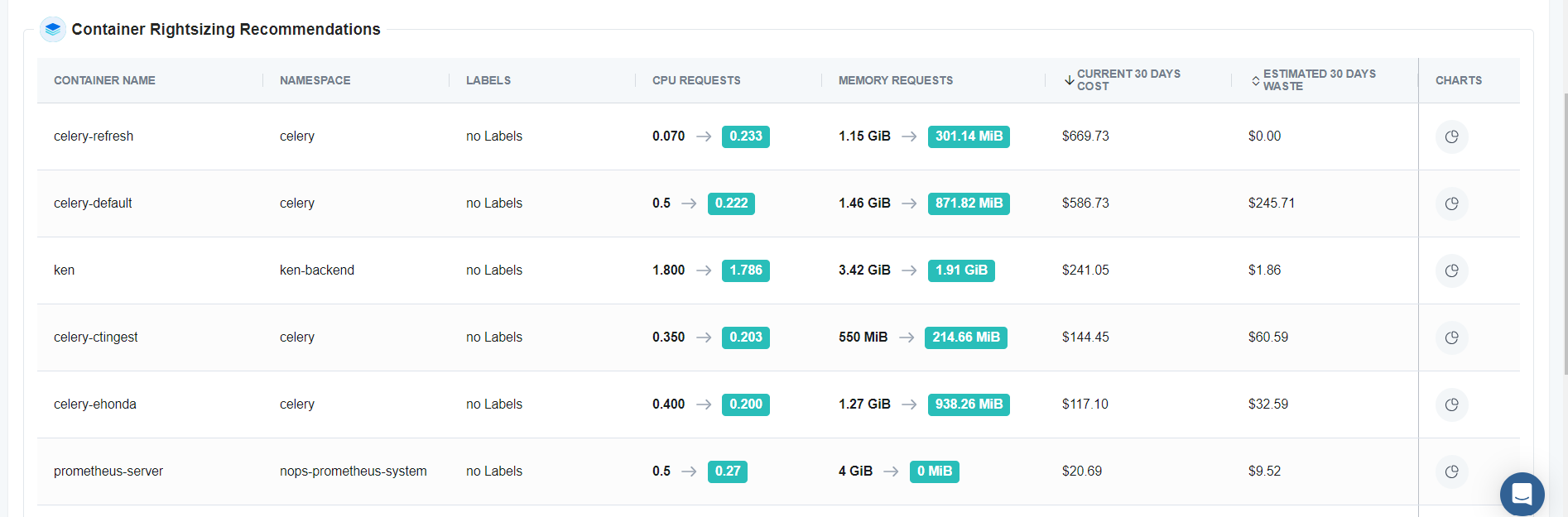
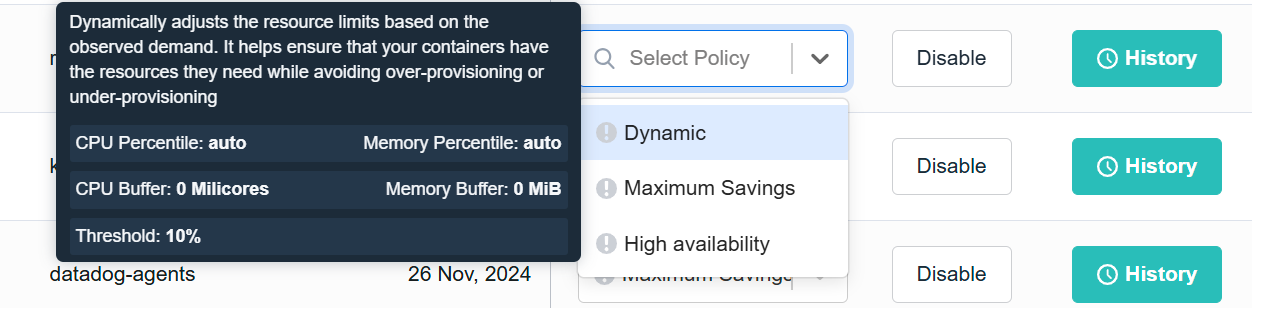
Dynamic Recommendation Policies
By default, nOps will automatically select the best dynamic rightsizing policy for your workload based on its historical resource consumption.
Recommendation Policies also enable users to automatically and continuously tailor recommendations to their unique requirements by leveraging nOps-supplied Quality of Service levels that combine CPU and memory recommendations to meet real-world operational requirements. Now you can take advantage of automatic resource allocation while still covering your peak traffic use cases.
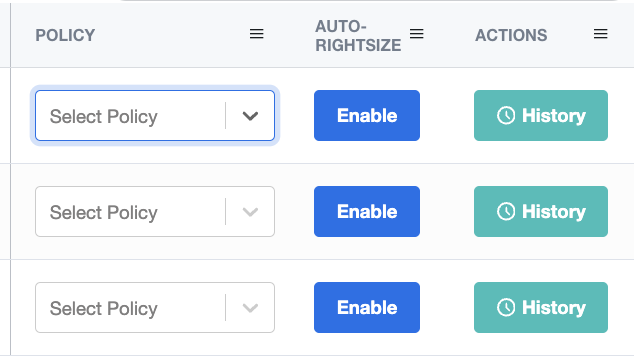
nOps offers a variety of preconfigured recommendation policies that cover common use cases, including a savings-oriented policy and a peak performance policy. Policies mix and match CPU and memory recommendations to create a custom combination that matches your use case.
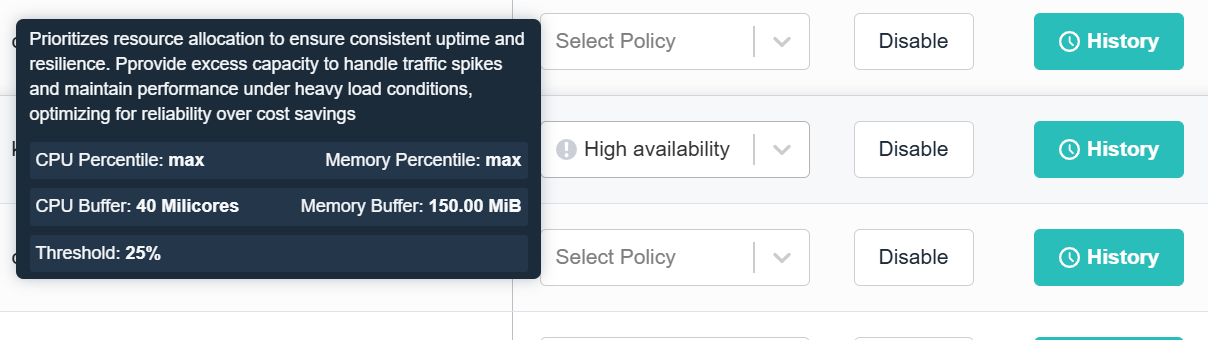
High Availability prioritizes resource allocation to ensure consistent updates and resilience.
Maximum Savings optimizes resource utilization and minimizes costs.
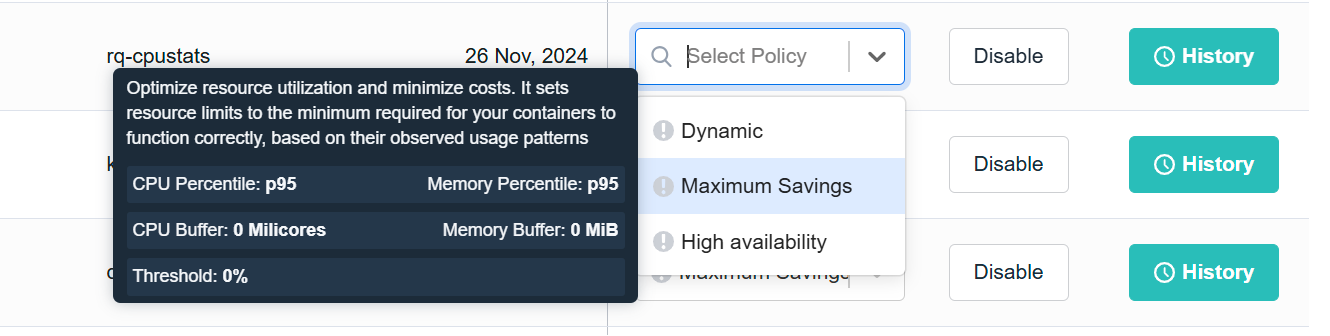
Dynamic continuously adjusts resources limits based on observed demand.
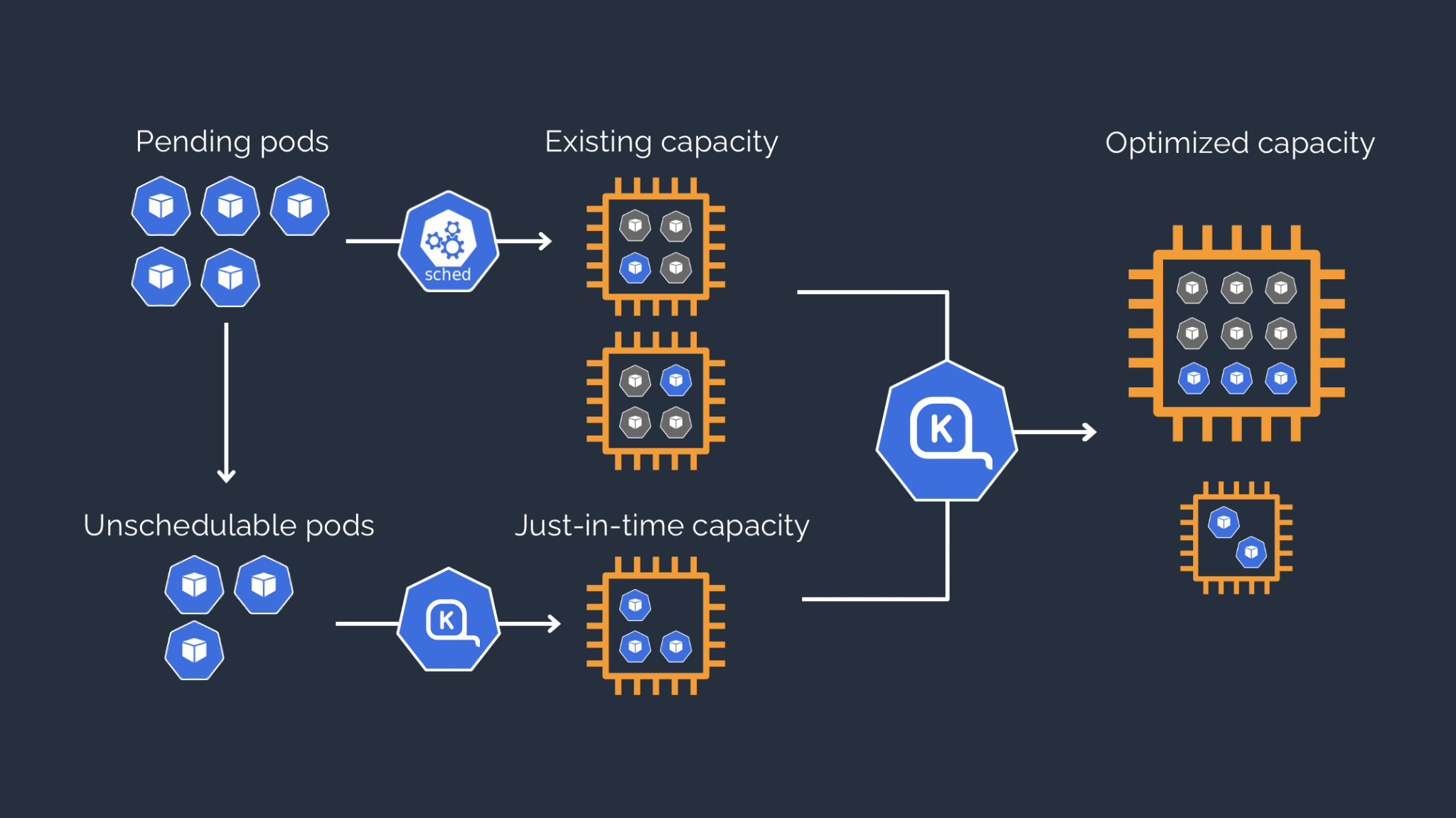
Rightsizing Nodes for Maximum Efficiency with Karpenter:
Many of our customers rely on Karpenter to dynamically provision right-sized nodes when new ones are needed. nOps elevates this capability by making Karpenter more cost-aware — seamlessly optimizing node selection to take advantage of the Spot Market and Savings Plans.
The result? Nodes that are not only perfectly sized for your workloads but also provisioned at the lowest possible cost, maximizing efficiency and minimizing expenses.
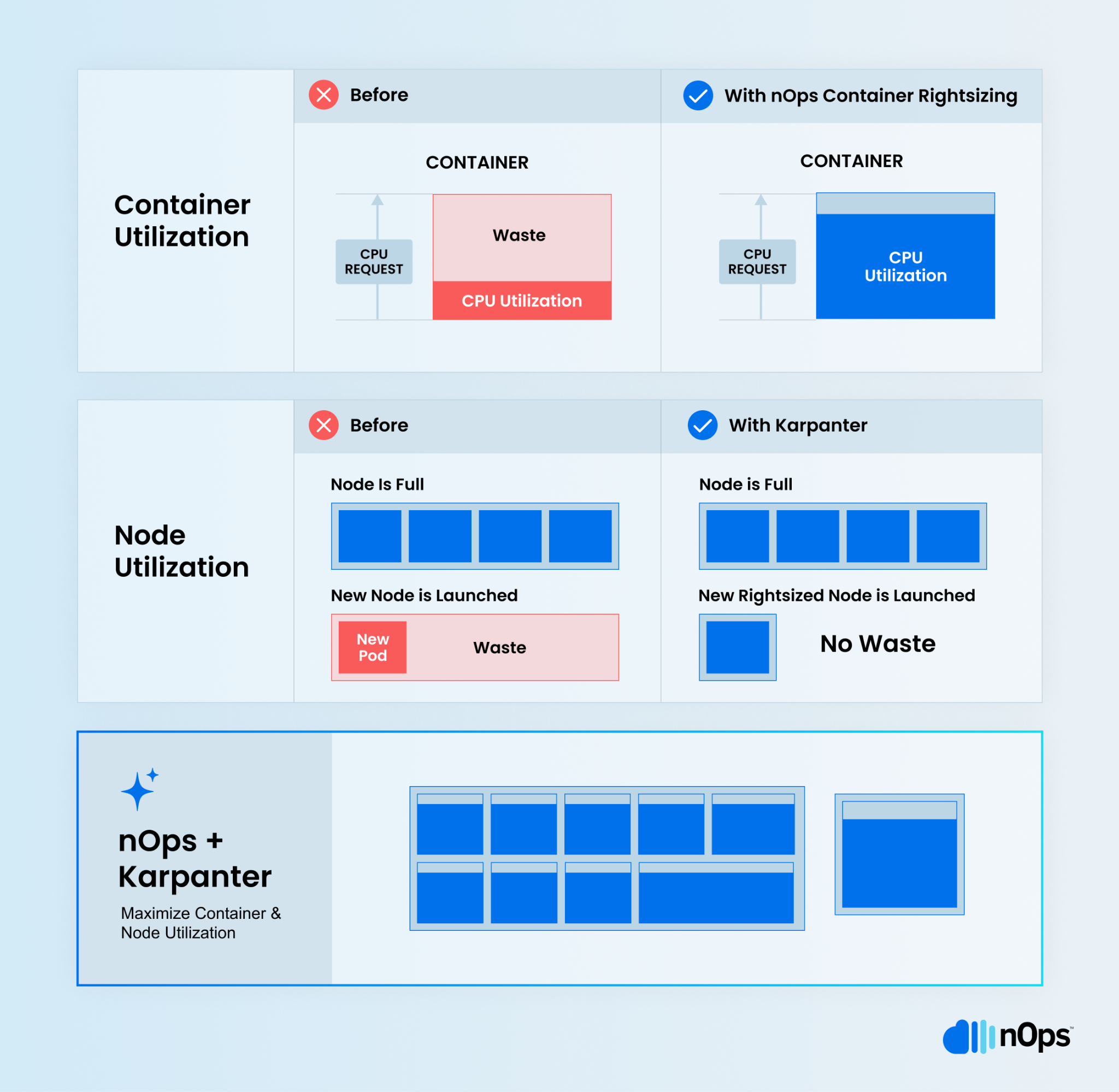
Binpacking for Maximum Utilization
nOps and Karpenter work together to enhance binpacking. By ensuring that your pods are only requesting the amount of CPU and memory that they need, more pods can fit onto your nodes. In addition, nOps employs consolidation policies to scale down underutilized nodes, redistributing pods to active nodes.
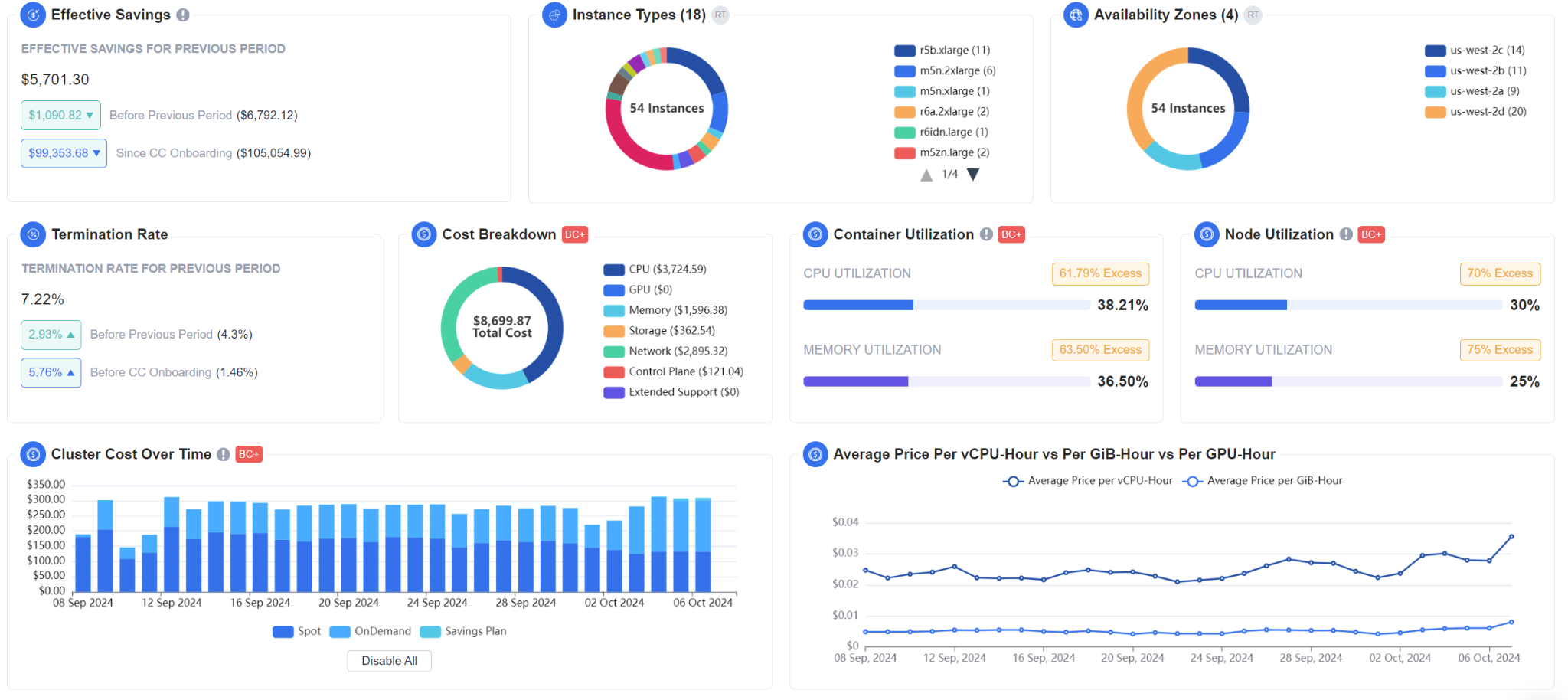
Cost Visibility
With deep visibility into workloads, utilization and costs, nOps empowers you to identify inefficiencies across your cluster and take immediate action to eliminate waste and optimize expenses.
At nOps, our mission is to make it easy for engineers to optimize. nOps was recently ranked #1 with five stars in G2’s cloud cost management category, and we optimize $2 billion in cloud spend for our customers.
Join our customers using nOps to understand your Kubernetes costs and leverage automation with complete confidence by booking a demo today!

























