New Gemini to AWS Bedrock Model Recommendations
Save up to 50% on LLM spend while increasing quality
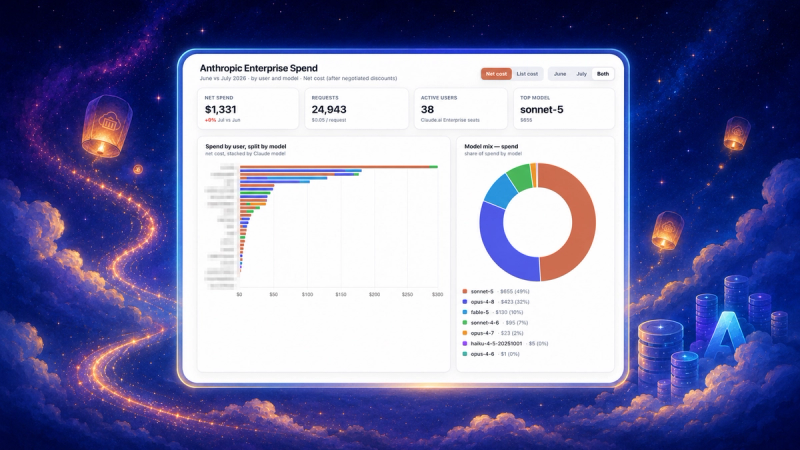
nOps AI Model Provider Recommendations give you side-by-side guidance on when to switch AI models — such as from Gemini (Vertex AI) to Amazon Bedrock models — to reduce costs significantly while maintaining the similar performance. This allows you to cut costs — often by an order of magnitude — without sacrificing response quality.
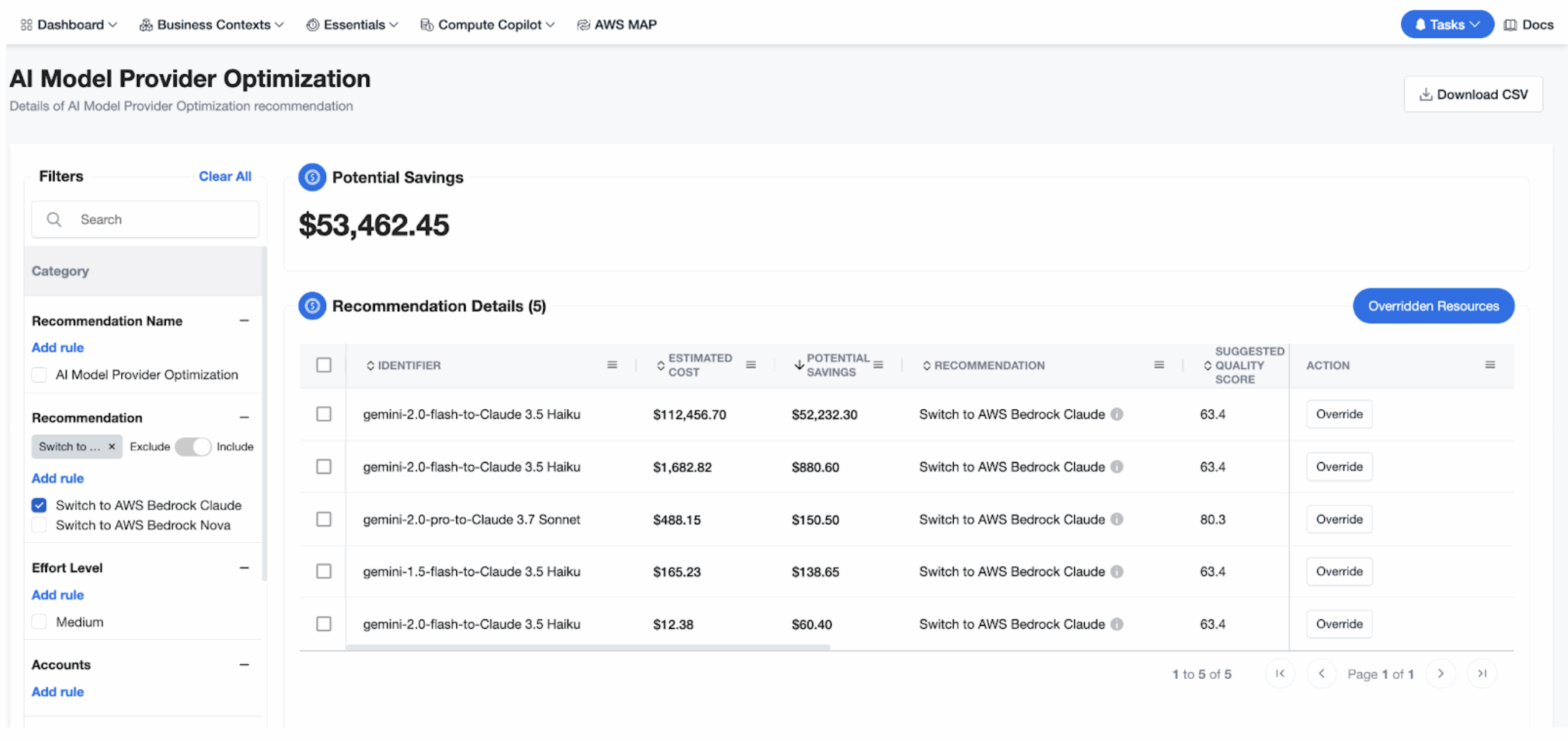
In the example below, a conversational service running Vertex AI (gemini-2.0-flash) costs $112,456 per month. Our engine flags that the same prompt mix fits Claude 3.5 Haiku on Bedrock, cutting costs by ~50% or $52,232.30 per month.
How It Works
nOps automatically detects your Gemini models using Vertex AI and assesses latency, context-window and function-calling needs. It calculates token economics using the latest model provider pricing from Amazon Bedrock to select and recommend the most cost-efficient AI model tier that meets your requirements—no guesswork needed.
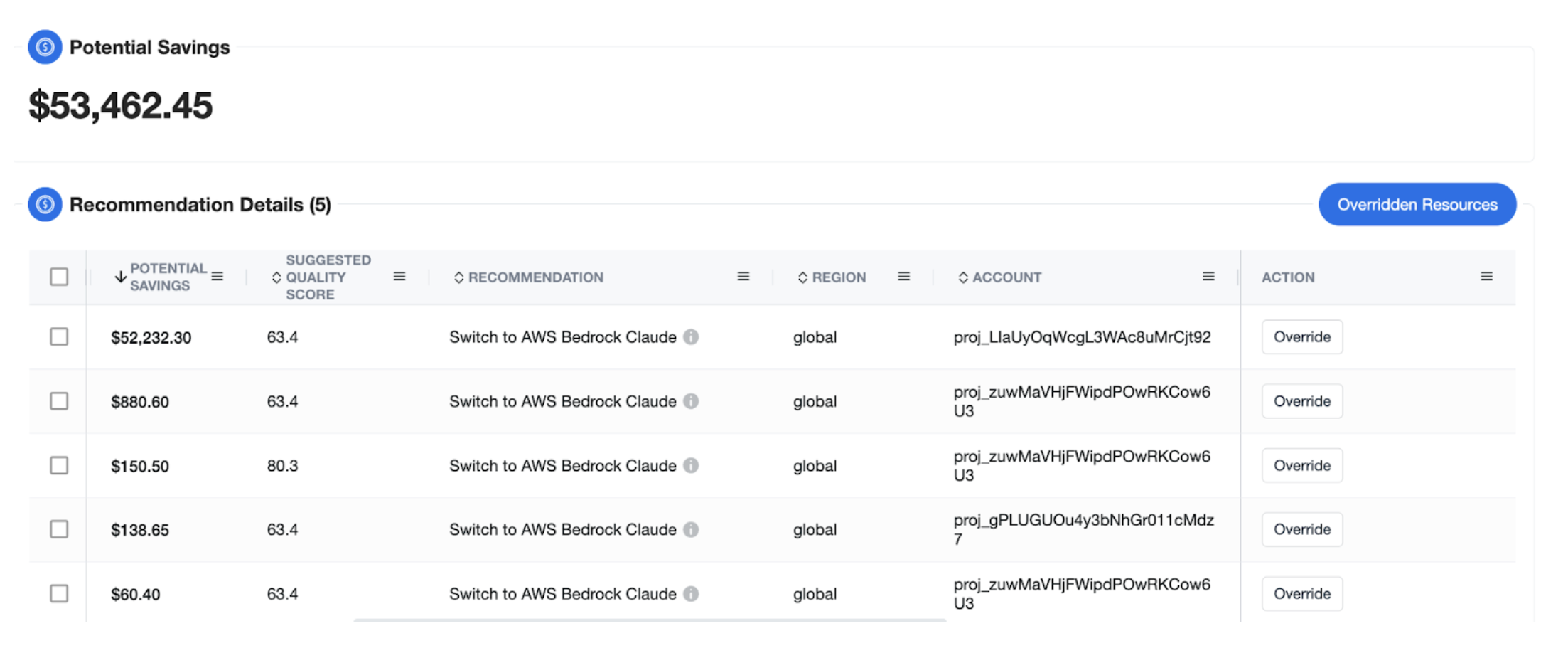
Each recommendation includes a clear explanation of the proposed model switch, including pricing, capabilities, quality change and projected savings.
How to Get Started
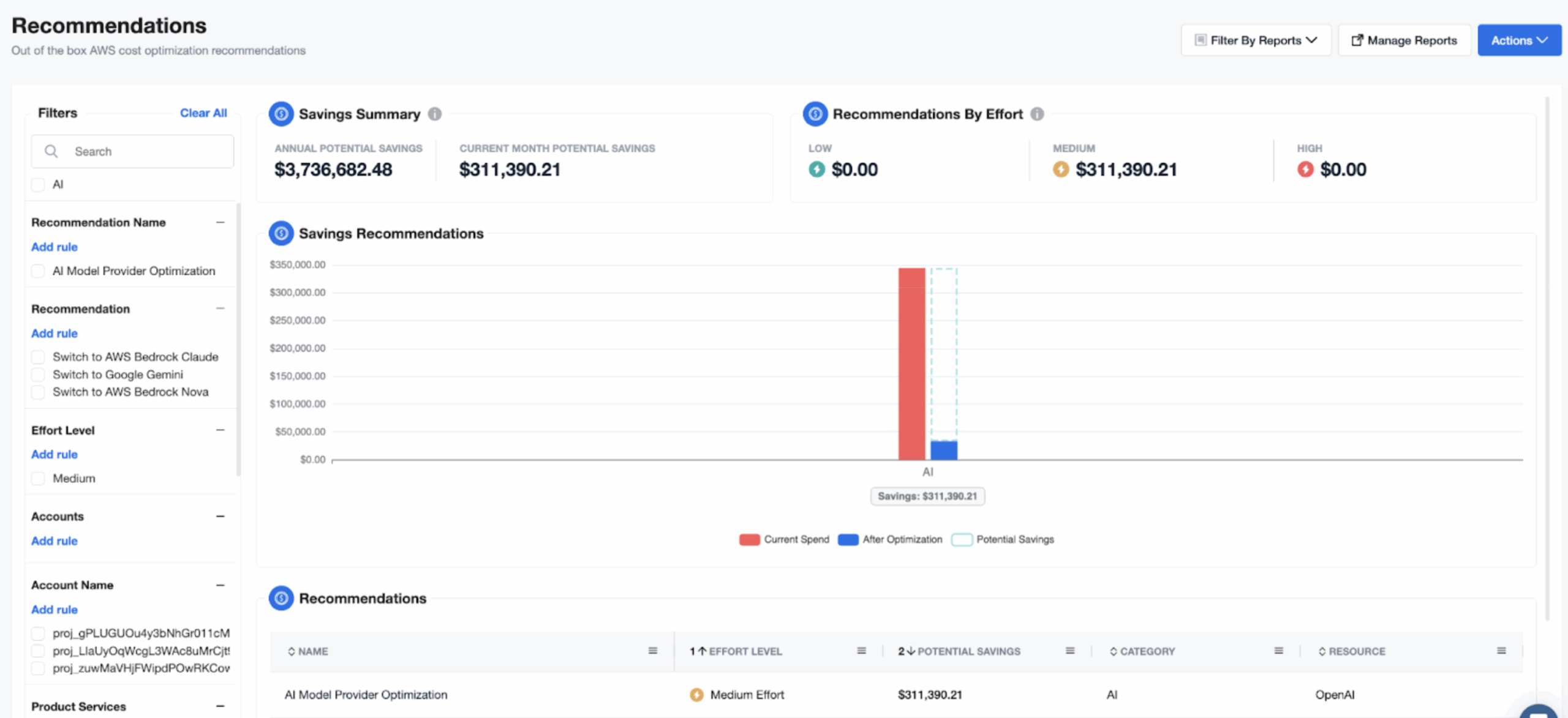
To access the new recommendations, log in to nOps. Navigate from Cost Optimization to the AI Model Provider Recommendations dashboard.
If you're already on nOps...
Have questions about AI Model Provider Recommendations? Need help getting started? Our dedicated support team is here for you. Simply reach out to your Customer Success Manager or visit our Help Center. If you’re not sure who your CSM is, send our Support Team an email.
If you’re new to nOps…
Ranked #1 on G2 for cloud cost management and trusted to optimise $2B+ in annual spend, nOps gives you automated GenAI savings with complete confidence. Book a demo to start saving on LLM cost without compromising on performance.